

NVIDIA为TOP500超级计算机加速、节能
电子说
描述
NVIDIA为全球最快的10台超级计算机中的8台提供加速。 NVIDIA Selene成为美国速度最快的工业系统,同时具有领先水平的能效表现。
最新TOP500超级计算机榜单展现了现代科学计算的整体情况:通过AI和数据分析进行扩展并使用NVIDIA技术提供加速。
目前,全球排名前十的超级计算机中有8台采用了NVIDIA GPU、InfiniBand网络技术,或同时采用了两种技术。其中包括美国、欧洲和中国最强大的超级计算机系统。
在TOP500榜单的所有系统中,有三分之二的系统(333套)采用了NVIDIA(现已与Mellanox合并)为其赋力。而在2017年6月发布的榜单上,采用两家公司的系统占比总和还不到一半(203套)。
如今,榜单上有将近四分之三(74%)的全新InfiniBand系统采用了NVIDIA Mellanox HDR 200G InfiniBand,这也展现了该最新智能高速数据互连技术的迅速普及。
自2019年11月以来,榜单上使用HDR InfiniBand的TOP500系统数量几乎增加了一倍。共有141台超级计算机使用了InfiniBand,自2019年6月以来增长了12%。
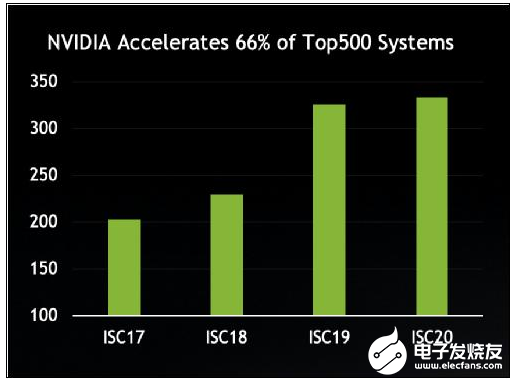
越来越多TOP500系统采用了NVIDIA GPU、Mellanox网络技术,或同时采用了这两种技术。
在TOP500超级计算机中,有305套系统使用了NVIDIA Mellanox InfiniBand和Ethernet网络(占61%),包括所有141套InfiniBand系统和164套(占63%)使用Ethernet的系统。
在能效方面,使用NVIDIA GPU的系统表现也都脱颖而出。与不使用NVIDIA GPU的系统相比,其能效(以gigaflops/watt为单位)平均高出2.8倍。
这也是为何排在TOP500榜单前25的超级计算机中有20台系统都选择采用NVIDIA GPU的原因之一。
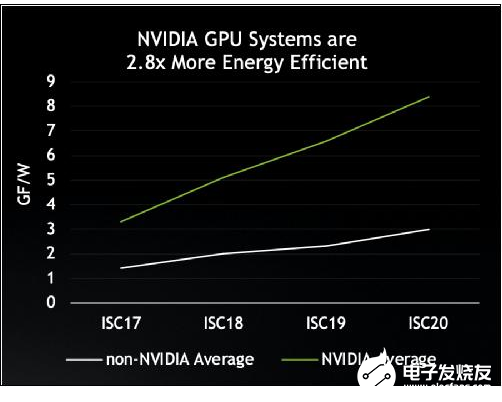
NVIDIA GPU提高了TOP500超级计算机的能效。
最能够证明此能效表现的是NVIDIA内部研究集群的新成员—— Selene(如上图所示)。该系统在Linpack基准测试中以27.5 petaflops的性能表现,在最新Green500榜单中排名第二,在整个TOP500榜单中排名第七。
Selene的功耗为20.5 gigaflops/watt,与Green500榜单上的第一名相差甚微,但排名第一的系统体积更小,其性能表现仅排在第394位。
Selene是排名前100系统中唯一突破20 gigaflops/watt能效表现大关的系统,同时也是全球性能排名第二的工业超级计算机,仅次于意大利能源巨头Eni S.p.A.的NO. 6 系统(同样使用了NVIDIA GPU)。
在能效方面,相比于未使用NVIDIA GPU的其它TOP500系统的平均能效表现,Selene的能效高出了6.8倍。Selene的优异性能和能效均要归功于NVIDIA A100 GPU中的第三代Tensor Core核心。该核心可以为传统的64位数学模拟及精度较低的AI工作提供加速。
Selene所取得的名次对于它来说已经是一项了不起的成就了,毕竟该系统只用了不到4周的时间就构建完成了。工程师们可以使用NVIDIA的模块化参照架构,快速构建Selene。
该参考架构既NVIDIA的DGX SuperPOD。该系统基于强大而灵活的现代数据中心构建模块 —— NVIDIA DGX A100系统。
高度灵活的DGX A100系统现已上市。该系统在一台6U服务器中集成了8颗A100 GPU以及NVIDIA Mellanox HDR InfiniBand网络技术,可以为高性能计算、数据分析和AI工作(包括训练和推理)等多种组合提供加速,并实现快速部署。
从系统扩展至SuperPOD
参照该参考架构设计,任何企业机构都可以快速搭建属于其自己的世界级计算集群。参照设计展示了如何像搭积木一样使用高性能NVIDIA Mellanox InfiniBand交换机连接20台DGX A100系统。
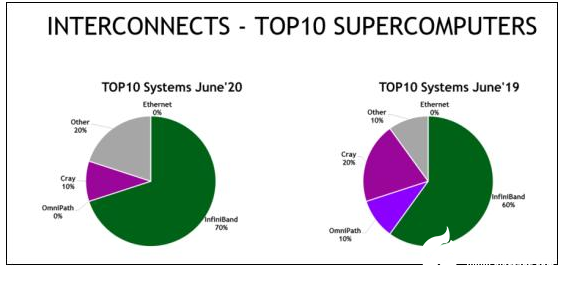
InfiniBand为排名前10的超级计算机中的7台提速,其中包括中国、欧洲和美国性能最强大的系统。
4名操作人员仅需不到1个小时,就能组装起一套由20台系统组成的DGX A100集群,创建出一套性能可以达到2-petaflops的系统,如此性能表现足以被列入TOP500榜单当中了。此类系统能够在标准数据中心的功率和散热能力承担范围内轻松运行。
通过添加NVIDIA Mellanox InfiniBand交换机层,工程师将14套分别配置有20台DGXA100系统的模块组的相连接,从而创造出了Selene。Selene系统具有:
·280台 DGX A100系统
·2240颗NVIDIA A100 GPU
·494台NVIDIA Mellanox Quantum 200G InfiniBand交换机
·56 TB/s的网络架构
·7PB的高性能全闪存
Selene最重要的性能规格之一是可以提供超过1 exaflops的AI性能。此外,在TPCx-BB关键数据分析基准测试中,其仅使用了16台DGX A100系统就创造了新纪录,其性能表现高出其他系统20倍。
如今,AI和分析已成为科学计算中的新需求,因此这些结果也显得格外重要。
在全球各地,研究者正在使用深度学习和数据分析预测各种最具潜力的领域,并进而开展实验。这一方法能够帮助研究者减少成本高昂且费时的实验量,从而加快取得科学成果的速度。
例如,目前有6台在建系统虽然没有出现在此次TOP500榜单中,但它们都采用了NVIDIA于上月发布的A100 GPU。这些系统将被用于加速HPC和AI的融合,开辟科学研究的新时代。
TOP500扩展科学计算应用
在这些系统当中,其中一台位于美国阿贡国家实验室(Argonne National Laboratory)。该机构的研究者将使用24台NVIDIA DGX A100系统组成的集群对数十亿种药物进行扫描,以寻找COVID-19的治疗方法。
阿贡国家实验室的计算生物学家Arvind Ramanathan在有关A100 GPU的首批用户报告中表示:“这项工作中的一大难点在于在计算机上进行模拟,因此我们运用AI来指导下一步的采样地点和时间。”
美国国家能源研究科学计算中心(NERSC)正在将AI应用于几个针对Perlmutter的项目中,Perlmutter是该中心的pre-exascale系统,拥有6200颗A100 GPU。
例如,其中一个项目将使用强化学习来控制光源实验,另有一个项目将使用生成模型在高能物理探测器上重现复杂的模拟。
为了加快新冠病毒蛋白的分析速度,慕尼黑的研究者们正在依靠Summit超级计算机中的6000颗GPU训练自然语言模型。有迹象表明,领先的TOP500系统正在超越使用双精度数学运行的传统模拟。
AI、数据分析和边缘串流正在重新定义科学计算。
随着向深度学习和分析的扩展,科学家们也在运用云计算服务,甚至运用来自于网络边缘的远程仪器的流式数据。这些要素共同构成了NVIDIA所加速的现代科学计算的四个支柱:
·模拟:在抗击新冠病毒的过程中,橡树岭国家实验室(Oak Ridge National Laboratory)的研究者使用Summit超级计算机的内置GPU运行AutoDock,在24小时内模拟了20亿种化合物。
·AI和数据分析:Spark 3.0 为关键且耗时的机器学习处理流程前端提供GPU加速。
·科学边缘串流:欧洲核子研究所(CERN)最近宣布,NVIDIA GPU将使其大型强子对撞机内粒子碰撞事件产生的数据量减少500倍。
·可视化:NVIDIA的IndeX和Magnum IO软件帮助增强火星登陆者号的可视化功能,这是全球规模最大的交互式实时立体可视化项目。
这些都表明研究者和企业都迫切需要从云到网络边缘的AI和分析加速,这也是为什么全球最大的云服务提供商以及全球顶尖的OEM厂商们都在采用NVIDIA GPU的原因。
此外,最新的TOP500榜单也以另一这种方式说明了NVIDIA为实现AI和HPC民主化所付出的努力。任何想要在计算能力上领先一步的公司都可以使用NVIDIA技术,如为全球最强大的系统提供支持的DGX系统。
最后,NVIDIA要向排名第一的日本Fugaku超级计算机的幕后工程师们表示祝贺,这表明Arm正在变得日益实用并且已经成为高性能计算的可行选择。这也是NVIDIA在去年宣布为Arm处理器架构提供CUDA加速计算软件的原因之一。
-
全球最新TOP500超算榜单出炉!揭秘英伟达雄霸三分之二版图的扩张之路!2020-06-25 14084
-
第57版世界TOP500超算排名公布,中国数量第一,美国算力第一2021-06-30 22426
-
超级计算机和特种计算机的比较和价值2008-12-01 1444
-
超级计算机Top500出炉:AMD助力顶级机器,但Intel2010-01-06 1417
-
2014全球超级计算机TOP10 中国完胜日本2014-07-08 26715
-
世界超级计算机500强公布,美国Summit问鼎2018-06-29 6293
-
NVIDIA GPU提高了TOP500超级计算机的能效2020-06-30 2554
-
全球超级计算机Top500新榜单公布2020-11-17 4785
-
日本 Arm 架构的超级计算机登上 Top500 榜首2020-11-18 2254
-
基于云的AI超级计算机正世界上最强大的计算机的榜单上蓄势待发2021-06-29 3424
-
NVIDIA研发全球最快的超级计算机推动临床测序和新药研发2021-08-23 4934
-
NVIDIA和Recursion利用AI超级计算机加快新药研发2024-05-16 2127
-
Green500全球最节能超级计算机榜单:采用NVIDIA技术包揽前三2024-05-24 1535
-
NVIDIA加速全球大多数超级计算机推动科技进步2024-11-24 964
-
NVIDIA驱动的现代超级计算机如何突破速度极限并推动科学发展2025-06-26 1081
全部0条评论

快来发表一下你的评论吧 !
