

机器学习的任务:从学术论文中学习数据预处理
电子说
描述
作为工作中最关键的部分,数据预处理同时也是大多数数据科学家耗时最长的项目,他们大约80%的时间花在这上面。
这些任务有怎样重要性?有哪些学习方法和技巧?本文就将重点介绍来自著名大学和研究团队在不同培训数据主题上的学术论文。主题包括人类注释者的重要性,如何在相对较短的时间内创建大型数据集,如何安全处理可能包含私人信息的训练数据等等。
1. 人类注释器(human annotators)是多么重要?
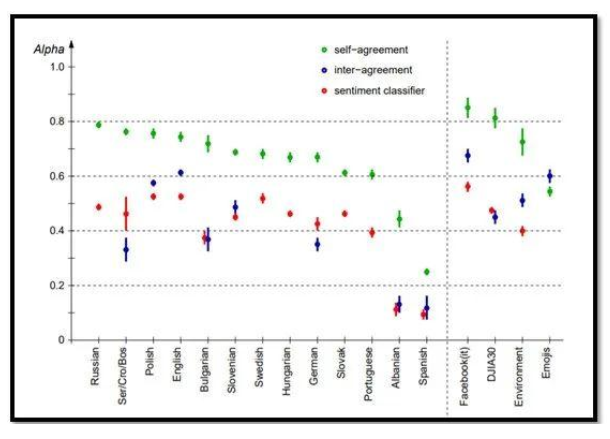
本文介绍了注释器质量如何极大地影响训练数据,进而影响模型的准确性的第一手资料。在这个情绪分类项目里,Joef Stefan研究所的研究人员用多种语言分析了sentiment-annotated tweet的大型数据集。
有趣的是,该项目的结果表明顶级分类模型的性能在统计学上没有重大差异。相反,人类注释器的质量是决定模型准确性的更大因素。
为了评估他们的注释器,团队使用了注释器之间的认同过程和自我认同过程。研究发现,虽然自我认同是去除表现不佳的注释器的好方法,但注释者之间的认同可以用来衡量任务的客观难度。
研究论文:《多语言Twitter情绪分类:人类注释器的角色》(MultilingualTwitter Sentiment Classification: The Role of Human Annotators)
作者/供稿人:Igor Mozetic, Miha Grcar, Jasmina Smailovic(所有作者均来自Jozef Stefan研究所)
出版/最后更新日期:2016年5月5日
2.机器学习的数据收集调查
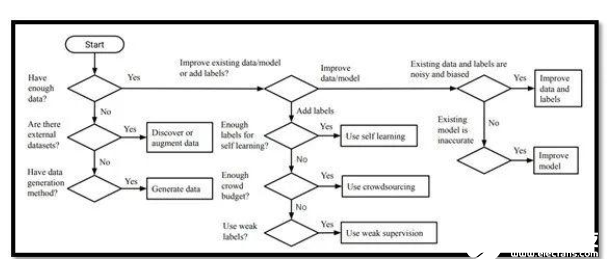
这篇论文来自韩国先进科学技术研究所的一个研究团队,非常适合那些希望更好地了解数据收集、管理和注释的初学者。此外,本文还介绍和解释了数据采集、数据扩充和数据生成的过程。
对于刚接触机器学习的人来说,这篇文章是一个很好的资源,可以帮助你了解许多常见的技术,这些技术可以用来创建高质量的数据集。
研究论文:《机器学习的数据收集调查》(A Survey on Data Collection for MachineLearning)
作者/供稿人: Yuji Roh, Geon Heo, Steven Euijong Whang (所有作者均来自韩国科学技术院)
出版/最后更新日期:2019年8月12日
3.用于半监督式学习和迁移学习的高级数据增强技术
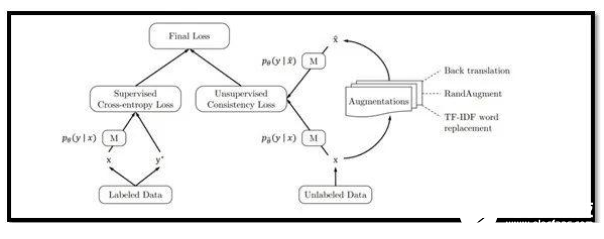
目前数据科学家面临的最大问题之一就是获得训练数据。也可以说,深度学习所面临最大的问题之一,是大多数模型都需要大量的标签数据才能以较高的精度发挥作用。
为了解决这些问题,来自谷歌和卡内基·梅隆大学的研究人员提出了一个在大幅降低数据量的情况下训练模型的框架。该团队提出使用先进的数据增强方法来有效地将噪音添加到半监督式学习模型中使用的未标记数据样本中,这个框架能够取得令人难以置信的结果。
该团队表示,在IMDB文本分类数据集上,他们的方法只需在20个标记样本上进行训练,就能够超越最先进的模型。此外,在CIFAR-10基准上,他们的方法表现优于此前所有的方法。
论文题目:《用于一致性训练的无监督数据增强》(UnsupervisedData Augmentation for Consistency Training)
作者/供稿人:Qizhe Xie (1,2), Zihang Dai (1,2), Eduard Hovy (2),Minh-Thang Luong (1), Quoc V. Le (1) (1 – Google研究院,谷歌大脑团队, 2 – 卡耐基·梅隆大学)
发布日期 / 最后更新:2019年9月30日
4.利用弱监督对大量数据进行标注
对于许多机器学习项目来说,获取和注释大型数据集需要花费大量的时间。在这篇论文中,来自斯坦福大学的研究人员提出了一个通过称为“数据编程”的过程自动创建数据集的系统。
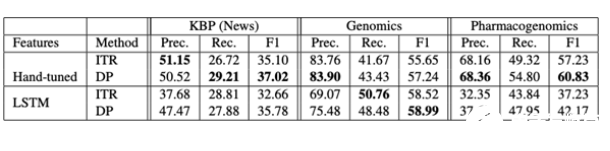
上表是直接从论文中提取的,使用数据编程(DP)显示了与远程监督的ITR方法相比的精度、召回率和F1得分。
该系统采用弱监管策略来标注数据子集。产生的标签和数据可能会有一定程度的噪音。然而,该团队随后通过将训练过程表示为生成模型,从数据中去除噪音,并提出了修改损失函数的方法,以确保它对“噪音感知”。
研究论文:《数据编程:快速创建大型训练集》(DataProgramming: Creating Large Training Sets, Quickly)
作者/供稿人:Alexander Ratner, Christopher De Sa, Sen Wu, DanielSelsam, Christopher Re(作者均来自斯坦福大学)
发布/最后更新日期:2017年1月8日
5.如何使用半监督式知识转移来处理个人身份信息(PII)
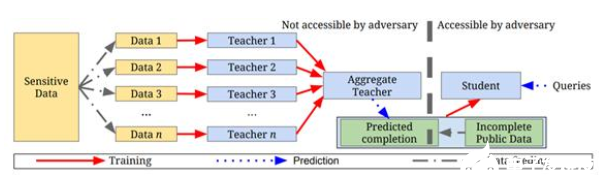
来自谷歌和宾夕法尼亚州立大学的研究人员介绍了一种处理敏感数据的方法,例如病历和用户隐私信息。这种方法被称为教师集合私有化(PATE),可以应用于任何模型,并且能够在MNIST和SVHN数据集上实现最先进的隐私/效用权衡。
然而,正如数据科学家Alejandro Aristizabal在文章中所说,PATE所设计的一个主要问题为该框架要求学生模型与教师模型共享其数据。在这个过程中,隐私得不到保障。
为此Aristizabal提出了一个额外的步骤,为学生模型的数据集加密。你可以在他的文章Making PATEBidirectionally Private中读到这个过程,但一定要先阅读其原始研究论文。
论文题目:《从隐私训练数据进行深度学习的半监督式知识转移》(Semi-SupervisedKnowledge Transfer for Deep Learning From Private Training Data)
作者/供稿人:Nicolas Papernot(宾夕法尼亚州立大学)、Martin Abadi(谷歌大脑)、Ulfar Erlingsson(谷歌)、Ian Goodfellow(谷歌大脑)、Kunal Talwar(谷歌大脑)。
发布日期 / 最后更新:2017年3月3日
阅读顶尖学术论文是了解学术前沿的不二法门,同时也是从他人实践中内化重要知识、学习优秀研究方法的好办法,多读读论文绝对会对你有帮助。
-
机器学习中的数据预处理与特征工程2024-07-09 2779
-
机器学习为什么需要数据预处理2023-08-24 3164
-
机器学习和深度学习的区别2023-08-17 5912
-
机器学习是什么,机器学习的定义2022-02-03 10454
-
信号处理与机器学习的结合论文2021-07-26 1422
-
基于Spark的学术论文热点数据挖掘方法2021-06-02 1199
-
详谈机器学习的智能语音处理技术2021-01-27 7441
-
人工智能、机器学习以及深度学习三者之间的关系是什么?2020-07-26 12454
-
Python数据预处理方法2020-06-03 1724
-
苹果发布关于人工智能的学术论文2018-07-12 5179
-
什么是机器学习?机器学习能解决什么问题?(案例分析)2018-05-18 17116
-
基于社区划分的学术论文推荐模型2017-12-19 859
-
机器学习论文简析2017-09-30 1111
全部0条评论

快来发表一下你的评论吧 !
