

CUDA 6中的统一内存模型
描述
CUDA介绍
CUDA(Compute Unified Device Architecture,统一计算设备架构)是由NVIDIA公司于 2006 年所推出的一种并行计算技术,是该公司对于GPGPU( General-purpose computing on graphics processing units, 图形处理单元上的通用计算 )技术的正式命名。通过此技术,用户可在GPU上进行通用计算,而开发人员可以使用C语言来为CUDA架构编写程序 。相比CPU,拥有CUDA技术的GPU成本不高,但计算性能很突出。本文中提到的是2014年发布的CUDA6, CUDA6最重要的新特性就是支持统一内存模型(Unified Memory)。
注:文中经常出现“主机和设备”,本文的“主机”特指CPU、“设备”特指GPU。
CUDA 6中的统一内存模型
NVIDIA在CUDA 6中引入了统一内存模型 ( Unified Memory ),这是CUDA历史上最重要的编程模型改进之一。在当今典型的PC或群集节点中,CPU和GPU的内存在物理上是独立的,并通过PCI-Express总线相连。在CUDA6之前, 这是程序员最需要注意的地方。CPU和GPU之间共享的数据必须在两个内存中都分配,并由程序直接地在两个内存之间来回复制。这给CUDA编程带来了很大难度。
统一内存模型创建了一个托管内存池(a pool of managed memory),该托管内存池由CPU和GPU共享,跨越了CPU与GPU之间的鸿沟。CPU和GPU都可以使用单指针访问托管内存。关键是系统会自动地在主机和设备之间迁移在统一内存中分配的数据,从而使那些看起来像CPU内存中的代码在CPU上运行,而另一些看起来像GPU内存中的代码在GPU上运行。
在本文中,我将向您展示统一内存模型如何显著简化GPU加速型应用程序中的内存管理。下图显示了一个非常简单的示例。两种代码都从磁盘加载文件,对其中的字节进行排序,然后在释放内存之前使用CPU上已排序的数据。右侧的代码使用CUDA和统一内存模型在GPU上运行。和左边代码唯一的区别是,右边代码由GPU来启动一个内核(并在启动后进行同步),并使用新的API cudaMallocManaged() 在统一内存模型中为加载的文件分配空间。
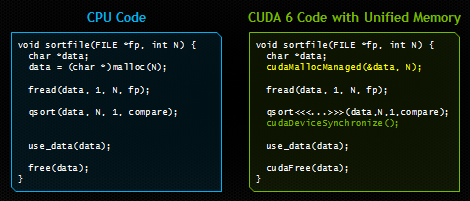
如果您曾经编程过CUDA C / C++,那么毫无疑问,右侧的代码会为您带来震撼。请注意,我们只分配了一次内存,并且只有一个指针指向主机和设备上的可访问数据。我们可以直接地将文件的内容读取到已分配的内存,然后就可以将内存的指针传递给在设备上运行的CUDA内核。然后,在等待内核处理完成之后,我们可以再次从CPU访问数据。CUDA运行时隐藏了所有复杂性,自动将数据迁移到访问它的地方。
统一内存模型提供了什么
统一内存模型为程序员提供了两大捷径
简化编程、简化内存模型
统一内存模型通过使设备内存管理(device memory management)成为一项可选的优化,而不是一项硬性的要求,从而降低了CUDA平台上并行编程的门槛。借助统一内存模型,程序员现在可以直接开发并行的CUDA内核,而不必担心分配和复制设备内存的细节。这将降低在CUDA平台上编程的学习成本,也使得将现有代码移植到GPU的工作变得容易。但这些好处不仅有利于初学者。我在本文后面的示例中将展示统一内存模型如何使复杂的数据结构更易于与设备代码一起使用,以及它与C++结合时的强大威力。
通过数据局部性原理提高性能
通过在CPU和GPU之间按需迁移数据,统一内存模型可以满足GPU上本地数据的性能需求,同时还提供了易于使用的全局共享数据。这个功能的复杂细节被 CUDA驱动程序和运行时隐藏了,以确保应用程序代码更易于编写。迁移的关键是从每个处理器获得全部带宽。250 GB / s的GDDR5内存对于保证开普勒( Kepler )GPU的计算吞吐量至关重要。
值得注意的是, 一个经过精心调优的CUDA程序,即使用流(streams)和 cudaMemcpyAsync来有效地将执行命令与数据传输重叠的程序,会比仅使用统一内存模型的CUDA程序更好 。可以理解的是:CUDA运行时从来没有像程序员那样提供何处需要数据或何时需要数据的信息!CUDA程序员仍然可以显式地访问设备内存分配和异步内存拷贝,以优化数据管理和CPU-GPU并发机制 。首先,统一内存模型提高了生产力,它为并行计算提供了更顺畅的入口,同时它又不影响高级用户的任何CUDA功能。
统一内存模型 vs 统一虚拟寻址?
自CUDA4起,CUDA就支持统一虚拟寻址(UVA),并且尽管统一内存模型依赖于UVA,但它们并不是一回事。UVA为 系统中的所有内存提供了单个虚拟内存地址空间,无论指针位于系统中的何处,无论在设备内存(在相同或不同的GPU上)、主机内存、或片上共享存储器。UVA也允许 cudaMemcpy在不指定输入和输出参数确切位置的情况下使用。UVA启用“零复制(Zero-Copy)” 内存,“零复制”内存是固定的主机内存,可由设备上的代码通过PCI-Express总线直接访问,而无需使用 memcpy。零复制为统一内存模型提供了一些便利,但是却没有提高性能,因为它总是通过带宽低而且延迟高的PCI-Express进行访问。
UVA不会像统一内存模型一样自动将数据从一个物理位置迁移到另一个物理位置。由于统一内存模型能够在主机和设备内存之间的各级页面自动地迁移数据,因此它需要进行大量的工程设计,因为它需要在CUDA运行时(runtime)、设备驱动程序、甚至OS内核中添加新功能。以下示例旨在让您领会到这一点。示例:消除深层副本
统一内存模型的主要优势在于,在访问GPU内核中的结构化数据时,无需进行深度复制(deep copies),从而简化了异构计算内存模型。如下图所示,将包含指针的数据结构从CPU传递到GPU要求进行“深度复制”。
下面以struct dataElem为例。
struct dataElem {int prop1;int prop2;char *name;}
要在设备上使用此结构体,我们必须复制结构体本身及其数据成员,然后复制该结构体指向的所有数据,然后更新该结构体。副本中的所有指针。这导致下面的复杂代码,这些代码只是将数据元素传递给内核函数。
void launch(dataElem *elem) { dataElem *d_elem;char *d_name;
int namelen = strlen(elem-》name) + 1;
// Allocate storage for struct and name cudaMalloc(&d_elem, sizeof(dataElem)); cudaMalloc(&d_name, namelen);
// Copy up each piece separately, including new “name” pointer value cudaMemcpy(d_elem, elem, sizeof(dataElem), cudaMemcpyHostToDevice); cudaMemcpy(d_name, elem-》name, namelen, cudaMemcpyHostToDevice); cudaMemcpy(&(d_elem-》name), &d_name, sizeof(char*), cudaMemcpyHostToDevice);
// Finally we can launch our kernel, but CPU & GPU use different copies of “elem” Kernel《《《 。.. 》》》(d_elem);}
可以想象,在CPU和GPU代码之间分享复杂的数据结构所需的额外主机端代码对生产率有严重影响。统一内存模型中分配我们的“ dataElem”结构可消除所有多余的设置代码,这些代码与主机代码被相同的指针操作,留给我们的就只有内核启动了。这是一个很大的进步!
void launch(dataElem *elem) { kernel《《《 。.. 》》》(elem);}
但统一内存模型不仅大幅降低了代码复杂性。还可以做一些以前无法想象的事情。让我们看另一个例子。
Example: CPU/GPU Shared Linked Lists
链表是一种非常常见的数据结构,但是由于它们本质上是由指针组成的嵌套数据结构,因此在内存空间之间传递它们非常复杂。如果没有统一内存模型,则无法在CPU和GPU之间分享链表。唯一的选择是在零拷贝内存(被pin住的主机内存)中分配链表,这意味着GPU的访问受限于PCI-express性能。通过在统一内存模型中分配链表数据,设备代码可以正常使用GPU上的指针,从而发挥设备内存的全部性能。程序可以维护单链表,并且无论在主机或设备中都可以添加和删除链表元素。
将具有复杂数据结构的代码移植到GPU上曾经是一项艰巨的任务,但是统一内存模型使此操作变得非常容易。我希望统一内存模型能够为CUDA程序员带来巨大的生产力提升。
Unified Memory with C++
统一内存模型确实在C++数据结构中大放异彩。C++通过带有拷贝构造函数(copy constructors)的类来简化深度复制问题。拷贝构造函数是一个知道如何创建类所对应对象的函数,拷贝构造函数为对象的成员分配空间并从其他对象复制值过来。C++还允许 new和 delete这俩个内存管理运算符被重载。这意味着我们可以创建一个基类,我们将其称为 Managed,它在重载的 new运算符内部使用 cudaMallocManaged(),如以下代码所示。
class Managed {public:void *operator new(size_t len) {void *ptr; cudaMallocManaged(&ptr, len); cudaDeviceSynchronize();return ptr; }
void operator delete(void *ptr) { cudaDeviceSynchronize(); cudaFree(ptr); }};
然后,我们可以让 String类继承 Managed类,并实现一个拷贝构造函数,该拷贝构造函数为需要拷贝的字符串分配统一内存。
// Deriving from “Managed” allows pass-by-referenceclass String : public Managed { int length; char *data;
public:// Unified memory copy constructor allows pass-by-value String (const String &s) { length = s.length; cudaMallocManaged(&data, length); memcpy(data, s.data, length); }
// 。..};
同样,我们使我们的 dataElem类也继承 Managed。
// Note “managed” on this class, too.// C++ now handles our deep copiesclass dataElem : public Managed {public:int prop1;int prop2; String name;};
通过这些更改,C++的类将在统一内存中分配空间,并自动处理深度复制。我们可以像分配任何C++的对象那样在统一内存中分配一个 dataElem。
dataElem *data = new dataElem;
请注意,您需要确保树中的每个类都继承自 Managed,否则您的内存映射中会有一个漏洞。实际上,任何你想在CPU和GPU之间分享的内容都应该继承 Managed。如果你倾向于对所有程序都简单地使用统一内存模型,你可以在全局重载 new和 delete, 但这只在这种情况下有作用——你的程序中没有仅被CPU访问的数据(即程序中的所有数据都被GPU访问),因为只有CPU数据时没有必要迁移数据。
现在,我们可以选择将对象传递给内核函数了。如在C++中一样,我们可以按值传递或按引用传递,如以下示例代码所示。
// Pass-by-reference version__global__ void kernel_by_ref(dataElem &data) { 。.. }
// Pass-by-value version__global__ void kernel_by_val(dataElem data) { 。.. }
int main(void) { dataElem *data = new dataElem; 。..// pass data to kernel by reference kernel_by_ref《《《1,1》》》(*data);
// pass data to kernel by value -- this will create a copy kernel_by_val《《《1,1》》》(*data);}
多亏了统一内存模型,深度复制、按值传递和按引用传递都可以正常工作。统一内存模型为在GPU上运行C++代码提供了巨大帮助。
这篇文章的例子可以在Github上找到。
统一内存模型的光明前景
CUDA 6中关于统一内存模型的最令人兴奋的事情之一就是它仅仅是个开始。我们针对统一内存模型有一个包括性能提升与特性的长远规划。我们的第一个发行版旨在使CUDA编程更容易,尤其是对于初学者而言。从CUDA 6开始, cudaMemcpy()不再是必需的。通过使用 cudaMallocManaged(),您可以拥有一个指向数据的指针,并且可以在CPU和GPU之间共享复杂的C / C++数据结构。这使编写CUDA程序变得容易得多,因为您可以直接编写内核,而不是编写大量数据管理代码并且要维护在主机和设备之间所有重复的数据。您仍然可以自由使用 cudaMemcpy()(特别是 cudaMemcpyAsync())来提高性能,但现在这不是一项要求,而是一项优化。
CUDA的未来版本可能会通过添加数据预取和迁移提示来提高使用统一内存模型的应用程序的性能。我们还将增加对更多操作系统的支持。我们的下一代GPU架构将带来许多硬件改进,以进一步提高性能和灵活性。
责任编辑:pj
-
一个用于6D姿态估计和跟踪的统一基础模型2023-12-19 2619
-
CUDA核心是什么?CUDA核心的工作原理2023-09-27 12052
-
介绍CUDA编程模型及CUDA线程体系2023-05-19 3316
-
如何在OpenCV中实现CUDA加速2022-09-05 6413
-
CUDA编程模型的统一内存2022-05-07 2359
-
CUDA简介: CUDA编程模型概述2022-04-20 4291
-
微基准测试的性能特征及如何在应用程序中使用统一内存2022-04-18 5859
-
CUDA编程之统一内存的介绍2022-04-11 3504
-
什么是CUDA?2021-07-26 1613
-
NVIDIA CUDA 计算统一设备架构2019-03-05 4377
-
基于CUDA技术的视频显示系统设计方案2018-01-18 6400
-
cuda程序设计2010-11-12 678
全部0条评论

快来发表一下你的评论吧 !
