

干货:一些Python有用的小技巧,离精通更进一步
电子说
描述
Python看起来似乎是一种任何人都可以学习的简单语言,但实际上,学会不等于精通,Python的“后劲儿”超乎我们的想象,它容易入门却很难掌握。在Python中,一个通常有多种处理方法,但很容易出错的地方很多;或者仅仅因为不知道模块的存在,你就得重新创建标准库,这很浪费时间。
Python标准库是一个巨大的野兽,它的生态系统绝对是庞大的。虽然Python模块可能有200万千兆字节,好在有一些使用技巧存在,我们可以用Python中与科学计算相关的标准库和包来学习。
1.反转字符串
虽然看似是很基础的操作,但是用char循环来反转字符串可能会非常繁琐麻烦。幸运的是,Python包含了一个简单的内置操作来准确地执行这个任务,我们只需访问字符串上的索引::-1。
a = “!dlrow olleH”
backward = a[::-1]

2.Dims作为变量
在大多数语言中,为了将数组放入一组变量中需迭代循环值,或按位置访问暗点,如下所示:
firstdim = array[1]
然而,在Python中有一种更好更快的方法。为了将一列值改为变量,可以简单地将变量名设置为与数组长度相同的数组:
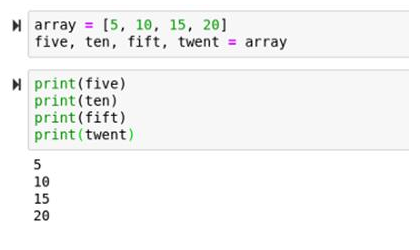
array = [5, 10, 15, 20]
five, ten, fift, twent = array
3.生成器的next()迭代
在编程中的大多数正常情况下,可以访问一个索引,并使用计数器获取位置数字,计数器将只是一个值,添加到:
array1 = [5, 10, 15, 20]
array2 = (x ** 2 for x in range(10))
counter = 0for i in array1:# This code wouldn‘t work because ’i‘ is not in array2.
# i = array2[i]
i = array2[counter]
# ^^^ This code would because we areaccessing the position of i
我们也可以用next()代替它。Next使用一个迭代器,该迭代器将当前位置存储在内存中,并在后台迭代列表:
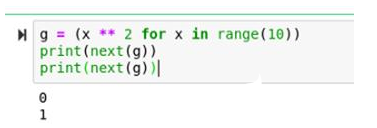
g = (x ** 2 for x in range(10))
print(next(g))
print(next(g))
4.智能拆包
迭代地解压值可能会非常耗费时力,Python中有几种不错的方法可以用来解压列表的方法。其中一个是*,它将填充未分配的值并将它们添加到变量名下的新列表中。
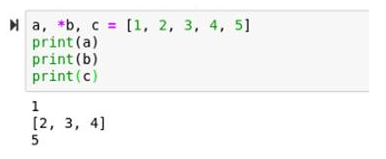
a, *b, c = [1, 2, 3, 4, 5]
5.列举
不了解列举那可不太行。列举可以获取列表中某些值的索引,在数据科学中使用数组而不是数据帧时,这就特别有用:
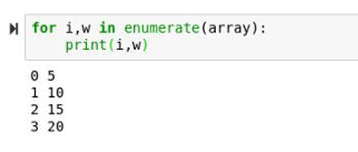
for i,w in enumerate(array):
print(i,w)
6.命名切片
Python中,分割列表非常简单,各式各样优秀工具都能做到。特别好的一点是,它还能够给列表命名,这对于Python中的线性代数特别有用:
a = [0, 1, 2, 3, 4, 5]
LASTTHREE = slice(-3, None)
slice(-3, None, None)
print(a[LASTTHREE])

7.Itertools
如果深入学习Python,那你肯定要熟悉itertools。itertools是标准库中的一个模块,它可以不断地解决迭代问题。它不仅使编写复杂循环大幅度变容易,而且还使代码更简洁快速。有数百种Itertools的使用示例,来看看其中一个:
c = [[1, 2], [3, 4], [5, 6]]
# Let’s convert this matrix to a 1 dimensional list.
import itertools as it
newlist = list(it.chain.from_iterable(c))
8.分组相邻列表
在for循环中,对相邻循环进行分组当然很容易,特别是使用zip(),但这肯定不是最好的方法。为了更轻松便捷地实现这一点,可以用zip编写一个lambda表达式,该表达式将对相邻列表进行分组,如下所示:
a = [1, 2, 3, 4, 5, 6]
group_adjacent = lambda a, k: zip(*([iter(a)] * k))
group_adjacent(a, 3) [(1, 2, 3), (4, 5, 6)]
group_adjacent(a, 2) [(1, 2), (3, 4), (5, 6)]
group_adjacent(a, 1)
9.计数器
集合也是模块中很好的标准库,这里向大家介绍的是集合中的计数器。使用计数器,可以轻松获得一个列表的计数。这对于获取数据中的值总数、数据的空计数,以及查看数据的唯一值非常有用。
“为什么不直接使用Pandas呢?”使用Pandas来实现这一点无疑会困难得多,而且这只是在部署算法时需要添加到虚拟环境中的另一个依赖项。另外,Python中的计数器类型有很多Pandas系列没有的特性,这使其在某些情况下更有用。
A = collections.Counter([1, 1, 2,2, 3, 3, 3, 3, 4, 5, 6, 7])
A Counter({3: 4, 1: 2, 2: 2, 4: 1, 5: 1, 6: 1, 7: 1})
A.most_common(1) [(3, 4)]
A.most_common(3) [(3, 4), (1, 2), (2, 2)]
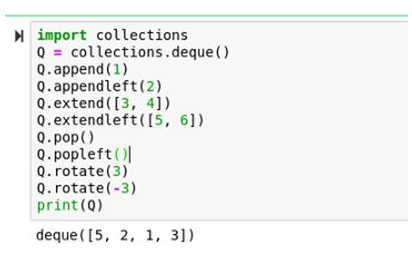
10.出队
如下所示,出队能让代码非常整洁:
import collections
Q = collections.deque()
Q.append(1)
Q.appendleft(2)
Q.extend([3, 4])
Q.extendleft([5, 6])
Q.pop()
Q.popleft()
Q.rotate(3)
Q.rotate(-3)
print(Q)
这些是笔者一直爱用的Python技巧,都非常通用和实用,实践中总有机会能用到。Python的标准库函数工具箱变得越来越多样,还有很多笔者也没听说过的工具。学无止境,这多么令人兴奋!
-
【单片机开发300问】怎样进一步降低功耗2011-12-07 4236
-
【OK210申请】嵌入式进一步学习(想试着做个简单的平板玩玩)2015-06-24 2847
-
E4406A达到adc对齐时不会更进一步了2018-12-28 2080
-
如何让计算机视觉更进一步接近人类视觉?2021-06-01 1846
-
进一步提高UPS电源的可靠性2021-12-28 1068
-
如何从工业4.0更进一步转向工业5.0?2018-07-09 1619
-
提速降费政策更进一步 取消流量“漫游”费为5G铺路2018-05-10 6550
-
Oculus Quest VR头盔获得FCC认证 意味着距离上市更进一步2018-12-25 4238
-
缩短交互路径 智能家居产品或者全屋智能的体验将更进一步2019-04-24 1274
-
智能家居交互方向或是无感化 全屋智能的体验将更进一步2019-04-26 1745
-
华为推出新功能,鸿蒙系统将更进一步2019-10-31 4962
-
Type-C接口需求的增加,使得USB PD实现进一步扩增2019-12-13 1213
-
更进一步学习MySQL2020-09-24 2380
-
【转载】更进一步的了解Keil Flash的下载算法2021-11-26 994
-
荣耀Magic4系列3月17日发布会,隐私保护更进一步2022-03-14 3602
全部0条评论

快来发表一下你的评论吧 !
