

图文详解:神经网络的激活函数
电子说
描述
什么是神经网络激活函数?
激活函数有助于决定我们是否需要激活神经元。如果我们需要发射一个神经元那么信号的强度是多少。
激活函数是神经元通过神经网络处理和传递信息的机制
为什么在神经网络中需要一个激活函数?
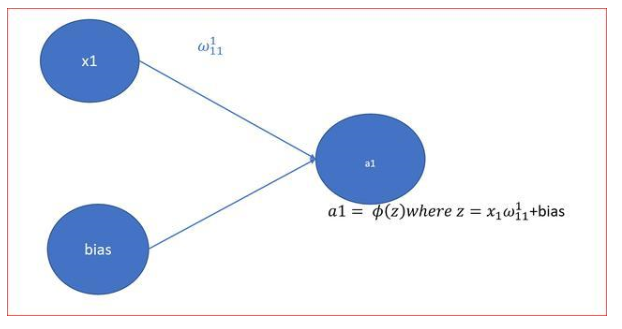
在神经网络中,z是输入节点与节点权值加上偏差的乘积。z的方程与线性方程非常相似,取值范围从+∞到-∞
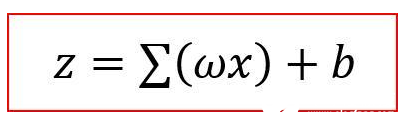
如果神经元的值可以从负无穷到正无穷变化,那么我们就无法决定是否需要激活神经元。这就是激活函数帮助我们解决问题的地方。
如果z是线性的,那么我们就不能解决复杂的问题。这是我们使用激活函数的另一个原因。
有以下不同类型的激活函数
阀值函数或阶梯激活函数
Sigmoid
Softmax
Tanh或双曲正切
ReLU
Leaky ReLU
为什么我们需要这么多不同的激活函数,我怎么决定用哪一个呢?
让我们回顾一下每一个激活函数,并了解它们的最佳使用位置和原因。这将帮助我们决定在不同的场景中使用哪个激活函数。
阀值函数或阶梯激活函数
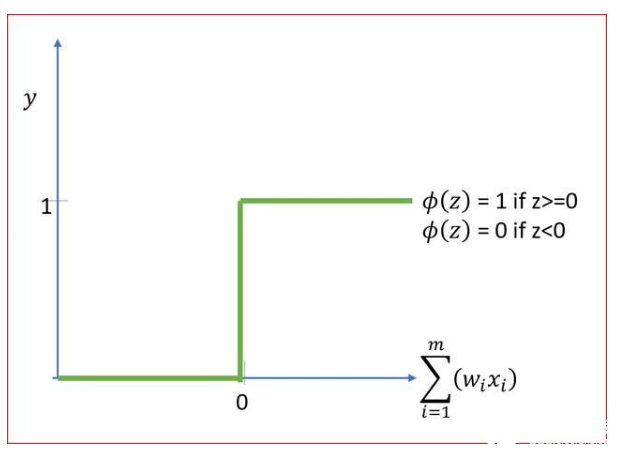
这是最简单的函数
如果z值高于阈值,则激活设置为1或yes,神经元将被激活。
如果z值低于阈值,则激活设置为0或no,神经元不会被激活。
它们对二分类很有用。】
Sigmoid激活函数
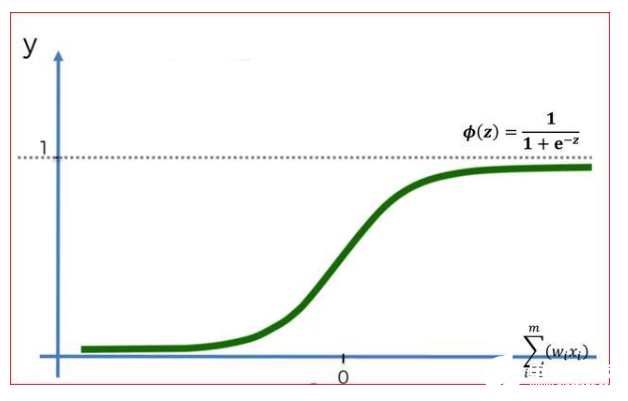
Sigmoid函数是一种光滑的非线性函数,无扭结,形状类似于S形。
它预测输出的概率,因此被用于神经网络和逻辑回归的输出层。
由于概率范围在0到1之间,所以sigmoid函数值存在于0到1之间。
但是如果我们想分类更多的是或不是呢?如果我想预测多个类,比如预测晴天、雨天或阴天,该怎么办?
Softmax激活有助于多类分类
Softmax激活函数
Sigmoid激活函数用于两类或二类分类,而softmax用于多类分类,是对Sigmoid函数的一种推广。
在softmax中,我们得到了每个类的概率,它们的和应该等于1。当一个类的概率增大时,其他类的概率减小,因此概率最大的类是输出类。
例如:在预测天气时,我们可以得到输出概率,晴天为0.68,阴天为0.22,雨天为0.20。在这种情况下,我们以最大概率的输出作为最终的输出。在这种情况下我们预测明天将是晴天。
Softmax计算每个目标类的概率除以所有可能的目标类的概率。
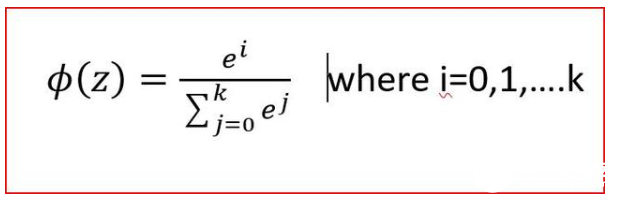
双曲正切或Tanh激活函数
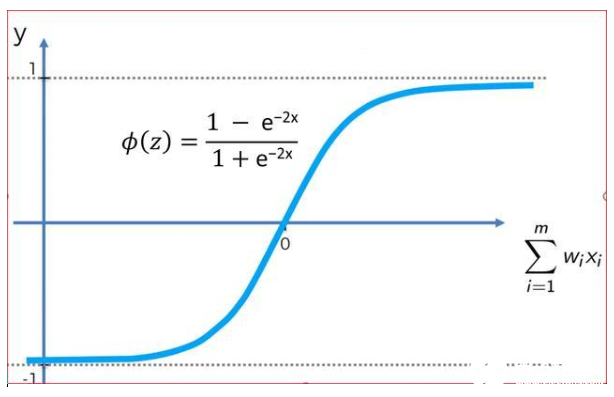
对于双曲tanh函数,输出以0为中心,输出范围在-1和+1之间。
看起来很像Sigmoid。实际上双曲tanh是缩放的s形函数。与Sigmoid相比,tanh的梯度下降作用更强,因此比Sigmoid更受欢迎。
tanh的优点是,负输入将被映射为强负,零输入将被映射为接近零,这在sigmoid中是不会发生的,因为sigmoid的范围在0到1之间
ReLU
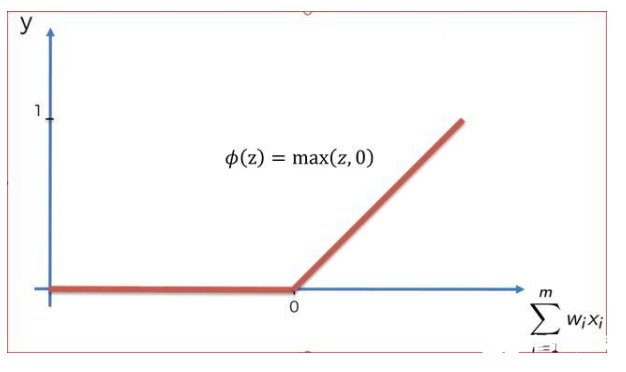
ReLU本质上是非线性的,这意味着它的斜率不是常数。Relu在0附近是非线性的,但斜率不是0就是1,因此具有有限的非线性。
范围是从0到∞
当z为正时,ReLU的输出与输入相同。当z为0或小于0时,输出为0。因此,当输入为0或低于0时,ReLU会关闭神经元。
所有的深度学习模型都使用Relu,但由于Relu的稀疏性,只能用于隐含层。稀疏性指的是空值或“NA”值的数量。
当隐层暴露于一定范围的输入值时,RELU函数将导致更多的零,从而导致更少的神经元被激活,这将意味着更少的神经网络交互作用。
ReLU比sigmoid或tanh更积极地打开或关闭神经元
Relu的挑战在于,负值变为零降低了模型正确训练数据的能力。为了解决这个问题,我们有Leaky ReLU
Leaky ReLU
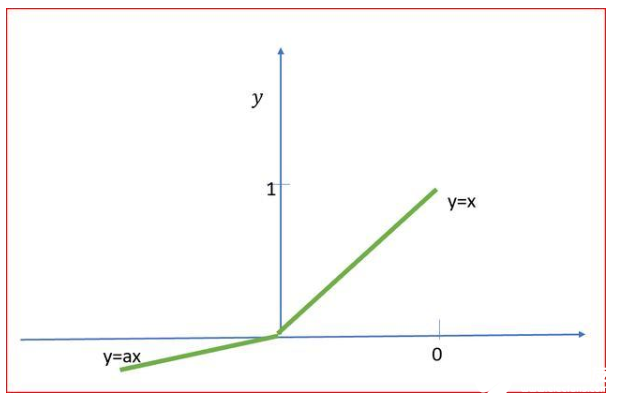
a的值通常是0.01
在Leaky ReLU中,我们引入了一个小的负斜率,所以它的斜率不是0。这有助于加快训练。
Leaky ReLU的范围从-∞到+∞
-
NMSIS神经网络库使用介绍2025-10-29 296
-
前馈神经网络的基本结构和常见激活函数2024-07-09 3155
-
卷积神经网络激活函数的作用2024-07-03 3256
-
神经网络中激活函数的定义及类型2024-07-02 2358
-
神经网络中的激活函数有哪些2024-07-01 2203
-
神经网络基本的训练和工作原理是什么2023-08-07 1370
-
神经网络初学者的激活函数指南2023-04-18 1263
-
神经网络移植到STM32的方法2022-01-11 3294
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3341
-
【PYNQ-Z2试用体验】神经网络基础知识2019-03-03 4000
-
【人工神经网络基础】为什么神经网络选择了“深度”?2018-09-06 1026
-
ReLU到Sinc的26种神经网络激活函数可视化大盘点2018-01-11 33477
全部0条评论

快来发表一下你的评论吧 !
