

详谈机器学习的决策树模型
电子说
描述
决策树模型是白盒模型的一种,其预测结果可以由人来解释。我们把机器学习模型的这一特性称为可解释性,但并不是所有的机器学习模型都具有可解释性。
作为可解释性属性的一部分,特征重要性是一个衡量每个输入特征对模型预测结果贡献的指标,即某个特征上的微小变化如何改变预测结果。
直觉
不同于基尼不纯度或熵,没有一个通用的数学公式来定义特征的重要性,而特征的重要性在不同的模型中是不同的。
例如,对于线性回归模型,假设所有输入特征具有相同的尺度(如[0,1],那么每个特征的特征重要性就是与该特征相关的权值的绝对值。从这个公式可以看出线性回归模型的f (X) =∑i = 1 n (wixi),模型的结果是线性正比于每个组件(wixi)这是由重量决定的(wi)的组件。
对于决策树,为了度量特征的重要性,我们需要研究模型,看看每个特征是如何在模型的最终“决策”中发挥作用的。从前面的文章中我们了解到,在决策树模型中,在每个决策节点上,我们选择最佳的特征进行分割,以便进一步区分到达该决策节点的样本。在每一次分割中,我们都更接近最终的决定(即叶节点)。因此,我们可以说,在每个决策节点上,所选择的分割特征决定了最终的预测结果。直观地说,我们也可以说,那些被选择的特征比那些实际上在决策过程中没有作用的非被选择的特征更重要。现在,剩下的问题是我们如何量化地衡量这种重要性。
有人可能还记得,我们使用信息增益或基尼系数来衡量分割的质量。当然,还可以将增益与所选择的特性关联起来,并使用增益来量化该特性在这个特定的分裂发生时的贡献。此外,我们可以累积决策树中出现的每个特征的增益。
最后,每个特征的累积增益可以作为决策树模型的特征重要性。
另一方面,作为一个可能会注意到,这一决定节点不是同样重要的是,自从决定节点树的根可以帮助过滤所有的输入样本,而决定节点树的底部有助于区分总样本的只有少数。因此,一个特征在每个决策节点获得的增益的权重并不相同,即一个特征在一个决策节点获得的增益应按该决策节点帮助区分的样本比例进行加权。
基于上述直觉,我们可以推导出以下公式来计算决策树中每个特征的重要性I:

注:我们可以用上述公式中的信息增益来代替基尼系数增益度量,只要我们对所有特征都使用相同的度量。
通过上面的公式,我们可以得到一个值来衡量决策树中每个特征的重要性。有时,可能需要对值进行规范化,以便更直观地比较这些值,即将所有值缩放到(0,1)的范围内。例如,如果有两个特征经过归一化后得分相同(即0.5),我们可以说它们在决策树中同等重要。
举个例子
让我们看一个具体的例子,看看我们如何应用上面的公式来计算决策树中的特征重要性。首先,我们在下图中展示了一个实例决策树。
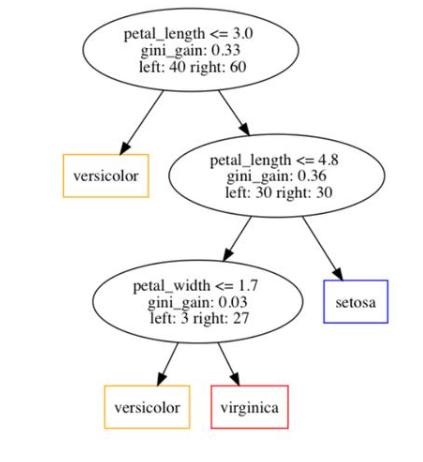
从图中可以看出,该树中共有3个决策节点。在每个决策节点中,我们指出了三条信息:
1、选择要分割的特性。
2、特征获得的基尼系数
3、分别分配给左子节点和右子节点的样本数量。
此外,我们可以看出决策树总共训练了100个样本。
因此,我们可以计算出树中涉及的两个特征的特征重要性如下:
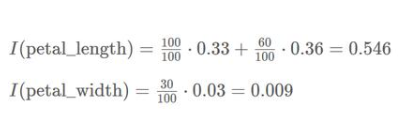
进一步,我们可以得到归一化特征重要性如下:

后记:路漫漫其修远兮,吾将上下而求索!
-
关于决策树,这些知识点不可错过2018-05-23 5126
-
决策树在机器学习的理论学习与实践2019-09-20 2150
-
机器学习的决策树介绍2020-04-02 1865
-
介绍支持向量机与决策树集成等模型的应用2021-09-01 1356
-
决策树的生成资料2023-09-08 665
-
基于决策树学习的智能机器人控制方法2015-11-30 537
-
决策树的构建设计并用Graphviz实现决策树的可视化2017-11-15 15397
-
机器学习:决策树--python2017-11-16 2016
-
机器学习之决策树生成详解2021-08-27 19865
-
决策树的原理和决策树构建的准备工作,机器学习决策树的原理2018-10-08 7192
-
机器学习中常用的决策树算法技术解析2020-10-12 1796
-
决策树的基本概念/学习步骤/算法/优缺点2021-01-27 3385
-
什么是决策树模型,决策树模型的绘制方法2021-02-18 14262
-
决策树的结构/优缺点/生成2021-03-04 8992
-
基于遗传优化决策树的建筑能耗预测模型2021-06-27 1107
全部0条评论

快来发表一下你的评论吧 !
