

 2020年第三届AI大会圆满成功,最新IP/芯片/方案/生态加速AI落地
2020年第三届AI大会圆满成功,最新IP/芯片/方案/生态加速AI落地
描述
2020年7月10日,由全球电子科技领域专业媒体<电子发烧友> 举办的第三届2020年人工智能大会盛大开幕,受疫情影响,今年AI大会由线下改成了线上举办,<电子发烧友>隆重邀请到了来自Imagination、赛灵思、中科创达、Arm中国、英伟达、英特尔、Synopsys、研华等众多家优秀AI企业的专家来作精彩的演讲。
电子发烧友总经理张迎辉在致辞中表示,在过去三年的快速发展中,中国的人工智能产业,已经成为了全球AI最大的市场和最快速发展的市场。
人工智能技术发展一日千里,当我们去年还在为图像、视频、语音、声音AI识别的技术问题不断钻研创新的时候,今年人脸识别已经在疫情防护中迅速落地,发挥着重要的作用。可以说,曾经走在技术创新前沿的企业,今年已经在市场上获得了巨大的回报。
此外,2020年国家推出了新基建的经济刺激发展规划,人工智能无疑会是新基建领域的重要一环,AI产业也将迎来更高速的发展和更加光明的前景。
调研:我国AI目前处于哪个阶段?未来发展机遇在哪里?
在大会上,电子发烧友AI产业分析师张慧娟从AI基础技术的演进、AI的应用现状、AI项目落地情况及AI落地变局与机遇四个方面做了精彩分享。
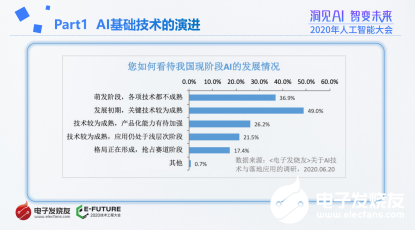
我国AI目前处于哪个阶段?张慧娟表示,根据电子发烧友调研,有36.9%的行业人士认为,我国现阶段AI处于萌发阶段,各项技术都不成熟,有49.0%的人士认为,我国AI处于发展初期,关键技术较为成熟。少数人士认为我国AI技术较为成熟,其中有26.2%的人士认为产品化能力有待加强的占,有21.5%的人士认为应用仍处于浅层次阶段。也有17.4% 的人士认为,我国现阶段AI格局正在形成,抢占赛道阶段。
在AI的应用现状方面,各家公司产品主要涉及到的AI技术有语音识别、机器学习平台、深度学习、图像识别、AI硬件优化等。产品在消费电子、智能家居、机器人领域的应用占多数。张慧娟谈到,近两年,AI在智能车载、智能安防、智能医疗、智慧教育等领域的应用也非常被看好,另外,因为技术难度大,只有极少数公司能够做到,所以在云端训练、远端推理领域的应用占较少。
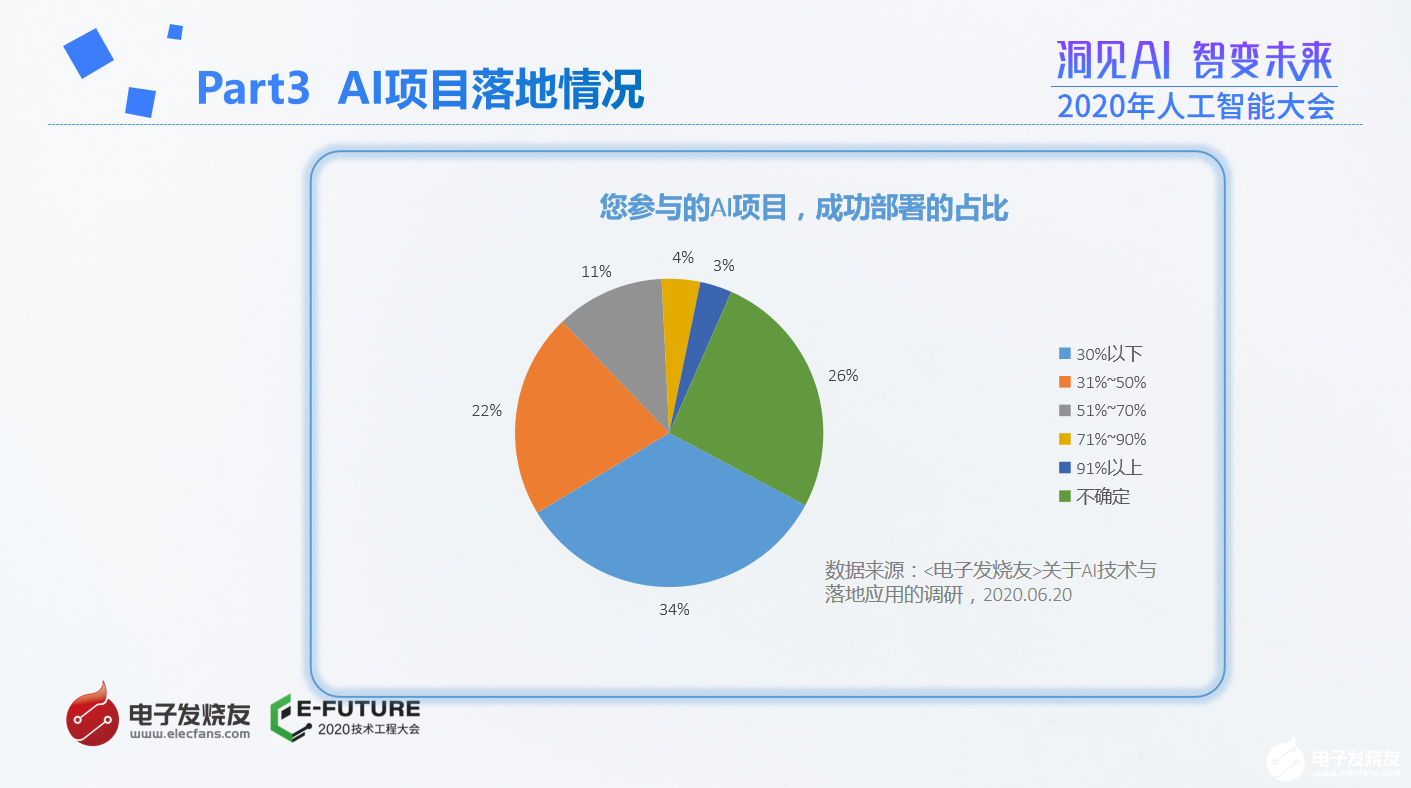
AI企业投入项目之后,存在很大的风险。根据调研,只有3% 的行业人士表示,参与项目之后,部署成功的概率能达到91%以上,而34% 的人士表示,成功概率在30%以下。在谈到项目失败的原因时,有60.4%的人士表示是产品应用市场与预期出现偏差,39.6%的人士表示是项目技术规格无法实现,35.6%的人士表示是配合不畅导致周期无法满足,还有23.5%的人士表示是项目资金出现问题。
张慧娟认为,虽然多数AI企业2019年的出货量同比增长放缓,整个行业的融资热情也有所降温。但从今年疫情期间,AI技术的加速落地,我们可以看到,AI产业还有很多的应用场景有待挖掘,也存在非常多的变局和机遇。
另外新基建也将给AI落地带来较大的拉动作用,不过AI企业还需要在算力、算法、产品形态与场景的精准匹配、安全、平台化服务能力及数据的获取/治理、软件平台各个方面优化提升和突破。
Imagination :基于GPU与神经网络加速器的异构计算——兼顾算力效率与算法普适性的平台
在此次人工智能大会上,Imagination 中国区战略市场与生态高级总监时昕带来的主题分享是《基于GPU与神经网络加速器的异构计算——兼顾算力效率与算法普适性的平台》。
异构计算技术从80年代中期产生,由于它能经济有效地获取高性能计算能力、可扩展性好、计算资源利用率高、发展潜力巨大,已成为并行/分布计算领域中的研究热点之一。目前Imagination与很多业界伙伴,都致力于异构计算。

“Imagination是一家IP公司,自己不生产芯片,主要是将授权给芯片客户,目前使用Imagination 授权IP的芯片出货量累计超110亿片,”时昕介绍道,“Imagination是全球唯一一家非美国的GPU IP核心专利持有公司,公司在移动端的GPU IP市场占有率接近40%,在汽车领域的GPU IP 市场占有率约为43%,Imagination的客户主要有苹果、联发科、TI、紫光展锐、三星、ST等等。”
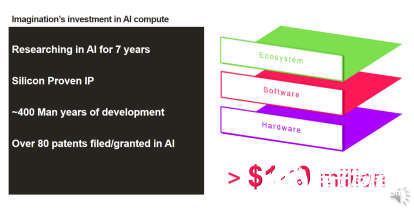
Imagination在AI领域投入大量的时间、金钱及人力,也取得了相当优秀的成绩,时昕表示,公司在人工智能领域研究了7年,投入费用超100万美元,已经申请/授权的人工智能专利超80项。
在会上,时昕重点介绍了Imagination灵活高效普适的异构平台NX-F及AI Synergy。NX-F神经网络边缘计算解决方案,具备高效神经网络支持的特点,引入了可编程性和浮点支持,包括计算优化GPGPU、PowerVR Rogue架构、基于多年的GPU计算经验等等。
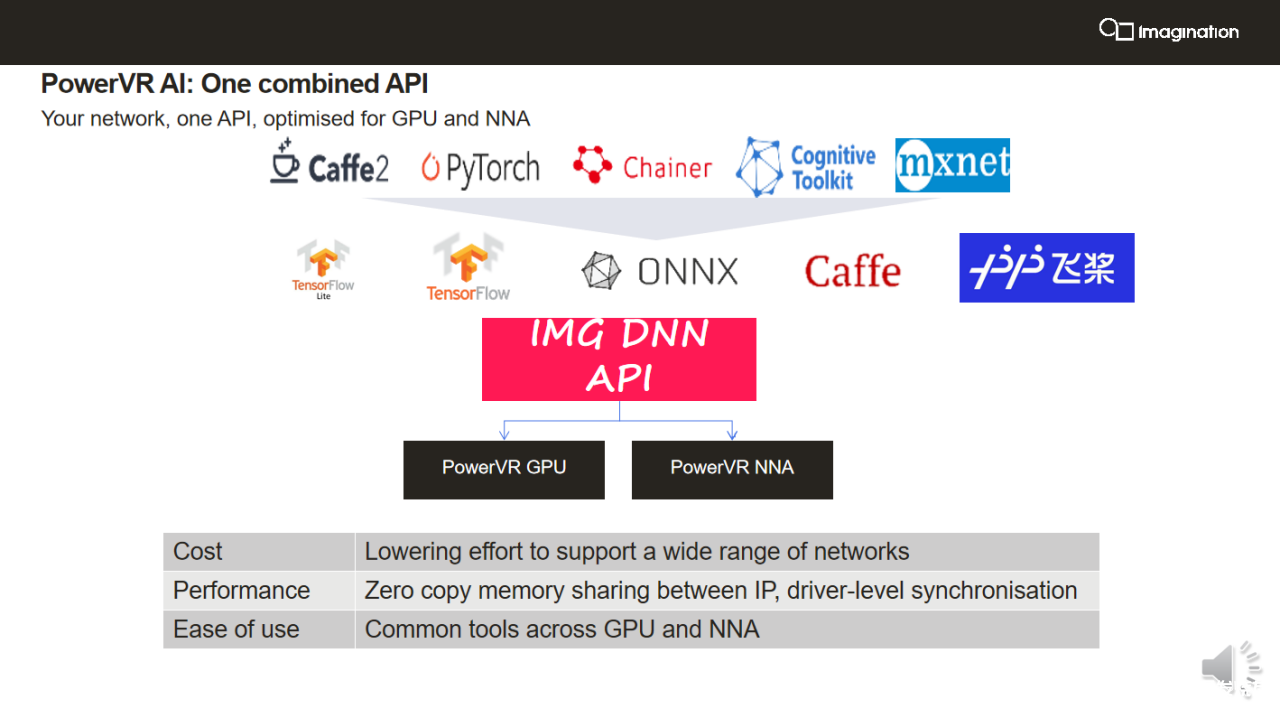
据时昕介绍,PowerVR AI,是一个组合API,支持在GPU和NNA中互联互通,软件可以完美的支持安卓的开发,在安卓之外,也支持常见的Linxux、TensorFlow、PyTorch等等。
Imagination还与英国软件公司codeplay有合作,2019年10月23日,Imagination宣布,得益于全新优化的开源SYCL神经网络库,使用TensorFlow的开发人员将可以直接面向PowerVR图形处理器(GPU)进行开发。其首个版本在2019年提供商用。
赛灵思:着眼效率提升和与IoT技术融合,AI芯片优化三大路径
7月10日,在电子发烧友主办的2020年人工智能大会高峰论坛上,来自赛灵思人工智能业务高级总监姚颂带来了《AI芯片技术与产业发展路径》的演讲。
姚颂指出,AI需要芯片,芯片需要AI。由于神经网络的加入,深度学习成为AI产业的助推力。转折点出现在2012年,英伟达在2007年和2008年推出CUDA,GPU和CUDA让深度学习复兴,对后来的整个人工智能起到了决定性的意义。2012年,Google当时有两个大神,一个是吴文达老师,斯坦福教授,后来成为百度的首席科学家,还有Justin和吴恩达做了一个猫眼识别的项目,花费了1000台服务器,16,000个CPU是一个非常大型的分布式的计算系统。采用了两个GPU,这个算法把神经网络劈成了两半,分别放在两个GPU上,一起训练出来,极大的简化了整个计算系统的复杂度,把海量的数据用起来。把神经网络和深度学习的优势给体现出来。

在姚颂看来,数据、算力和算法三大因素共同驱动了人工智能的兴起。AI芯片的发展主要是关键性的应用推动。AI正在为越来越多的细分应用提供支持,不同的模型针对不同的应用类别,例如分类、目标检测、道路分割等主要采用卷积神经网络(CNN)。
哪些杀手级应用推动芯片的应用?姚颂认为,下一代技术主力发展是IoT和AI,IoT如果只做简单的连接,价值不大,如果赋予IoT一定AI能力,比如全家实现语音控制和语音交互,这些智慧生活体验带动应用的兴起。新零售、新制造、医疗领域也将成为AI市场的新增长点。
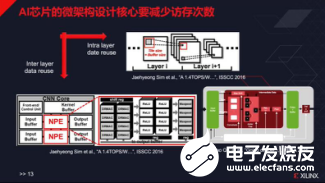
AI芯片的核心解决什么问题?姚颂认为,AI芯片主要解决的是带宽不足的问题,提高芯片的利用率。AI计算优化的三个维度,包括微架构设计、核心技术和算法压缩。AI芯片微架构设计的核心就是减少访存次数,芯片物理上的改进,采用的方法包括增大芯片尺寸,采用更多的晶体管,采用最新的制程和最高的带宽。
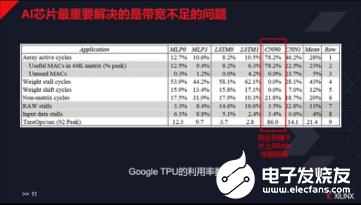
AI芯片近年来最大的进步非常大。姚颂分析说,清华大学高性能计算研究组的数据研究结果显示,从2019年到目前,ASIC产品已经出来,总体性能达到一个很好的指标,FPGA也在不断改进,,用数模混合方式做出来的AI芯片得到一些特别恐怖的新指标,目前离量产还有一段距离。
姚颂指出,AI芯片越专用,性能越好,设计难度越小。赛灵思的GPU是支持卷积神经网络,寒武纪是支持机器学习,AI芯片的需求确实差异很大。比如无线耳机的语音唤醒与识别需要AI芯片功耗低,成本低。自动驾驶需要的AI芯片低延迟、高可靠。
姚颂认为,生态与软件的重要性远远大于AI芯片本身。如果只有芯片和指令集,应用时就会产生很多问题。没有软件,开发者无法使用,没有生态,初学者根本没有办法看懂,学习成本很高,厂商不做板卡跟系统,工程师拿到你的AI芯片,最后做成产品也非常费劲。
中科创达:边缘计算推动边缘智能实现,5G与边缘智能融合前景看好
7月10日,在电子发烧友主办的2020年人工智能大会高峰论坛上,中科创达智能物联网事业群副总裁杨新辉带来了全球5G和AI融合趋势的精彩观点分享,并重点分析了边缘计算领域最新进展,以及5G与边缘智能融合的落地关键点。
杨新辉的观察是,全球5G+AI技术发展迅速,为IoT市场带来新机会,根据2020年IDC预测,5G智能终端的出货量会超过1亿台。纵观全球AI市场,德勤数据显示,到2020年人工智能在安防、金融、医疗等领域,边缘计算产品和应用逐步落地,营收可以达到2.4万亿美元的市场规模。2025年全球的互联网设备将超过250亿台连接,其中将可能有10%是通过5G网络产生的连接。
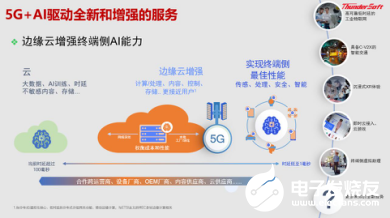
5G和AI未来将成为产业智能化的重要推手,考虑到5G网络具备可扩展能力和可靠性,更加灵活的无线网络,极大解决了连接安全和计算问题。在边缘计算和AI方向,边缘计算会有更多的感知和处理,机器视觉与人工智能将应用于无人驾驶,进行边缘的服务和数据的私有化,两者结合起来,将为整个的产业发展提供更强的动力。
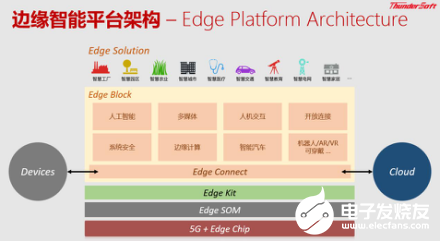
杨新辉认为,5G网络部署带动通信带宽的增加和大数据的产生,整个市场对边际计算的需求日益强烈。5G时代,为了保证边缘计算产业和网络边缘计算的服务有效应对到落地场景,中科创达提供TurboX Edge Platform边缘智能平台,底层提供基于5G的通讯模组和边缘计算的芯片,为了加速开发者的产品落地,他们又推出了成熟的边缘计算的开发套件TurboX Edge Kit。
TurboX Edge Platform边缘智能平台采用层级化、模块化的设计理念以及容器化的部署方式,基础层包含核心计算模块(SOM)、操作系统内核、硬件驱动和开发套件;中间件层包含以人工智能、边缘计算、安全、人机交互为主的模块化组件;应用层包含各垂直行业端到端解决方案以及云服务,实现了边缘与云端的数据协同、控制协同、管理协同。目前,该平台已经广泛应用在智能工业、智能城市、智能零售、智能网联汽车、机器人等多个垂直行业。
Arm中国:AI芯片的发展与周易AIPU
随着数据量指数级的增长,倒逼着算力需求升级,针对不同场景的算力升级需要不同的AI芯片。同时,神经网络的发展需要更高算力AI芯片。传统的CPU和GPU两大硬件架构进行的运算消耗大量的处理能力,AI芯片不仅对工作负载高的模型算子提升效率,也提供强大的可编辑引擎,对模型自定义层和新兴的算子提供支持。
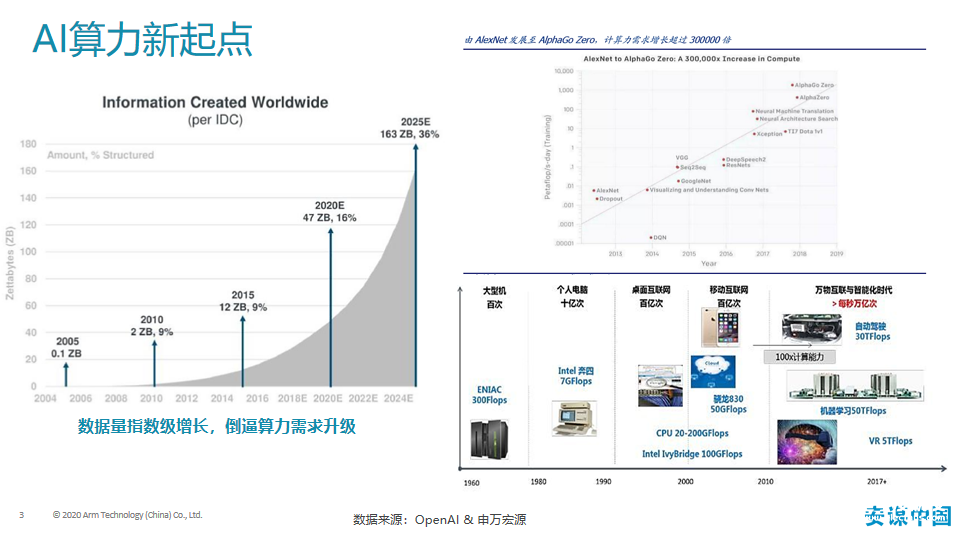
Arm中国高级AI技术市场经理吴彤在分析当前AI处理器的演进时谈到,为了提高AI芯片的性能,AI芯片领域专用架构DSA逐渐兴起,DSA将弥补软硬件的性能鸿沟,将硬件架构进行定制并使其具备特定领域应用特征,使该领域的一系列应用任务都能高效执行。典型的DSA架构包括机器学习领域的神经网络处理器,图形图像/虚拟现实领域的图像处理器GPU,以及可编程网络交换机及接口。
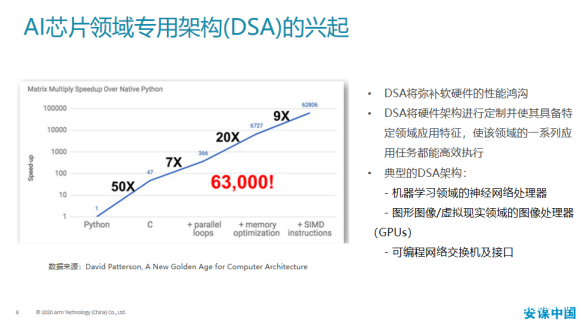
他还列举了目前AI芯片六个典型架构,包括英伟达A100 GPU、谷歌TPU 3.0、Xilinx Versal ACAP、Intel Habana Gaudi、Graphcore IPU以及Cerebras WSE。而AI芯片的发展方向将取决于算法和生态等因素,深度学习算法需求以及从底层硬件到工具链、更高阶的库再到应用的生态也至关重要,此外Chiplet小芯片通过封装技术将芯片进行整合,也推动着AI芯片的发展。
去年,Arm中国发布周易AIPU是其自主研发的神经网络处理IP,具有创新架构、安全性和可扩展性。
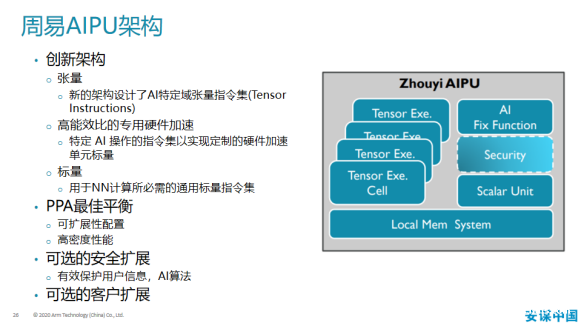
据透露,首款采用周易AIPU的芯片全志科技语音芯片R329将于年内上市。吴彤指出,由于算法迭代快,AI芯片如何适配呢,周易提供很好的编程特性,可支持市面上主流算法的升级,此外周易的可扩展性可支持0.2TOP到几十TOPS算力的应用。从工具链到库、统一面向AI应用的API、支持所有主流AI框架以及丰富的AI应用构建的生态也成为周易AIPU能够快速从设计到量产的关键。
英伟达:Jetson平台助力边缘计算开发
英伟达从硬件到软件构建的生态加速了其GPU产品的应用落地。此次,英伟达带来Jetson嵌入式计算平台在边缘端应用的最新情况。
JETSON平台已经聚集了50多万开发者,并且还在快速增长。JETSON在工业、物流、零售、医疗、农业、智慧城市等各行各业得到了广泛的应用。英伟达以强大的GPU而知名,然而在芯片的基出上,完善好用的工具链、SDK等的支持也令英伟达的芯片能够更方便的进入应用场景。
英伟达开发者关系总监李雨倩在演讲中表示,英伟达提供Tensor RT和Transfer learning工具,前者可支持多种算法模型平滑对接到英伟达的硬件,后者通过减枝、场景适配和新的层级,可对大型数据进行裁减,对场景增加数据集,以及预留部分通道拓展应用等等。
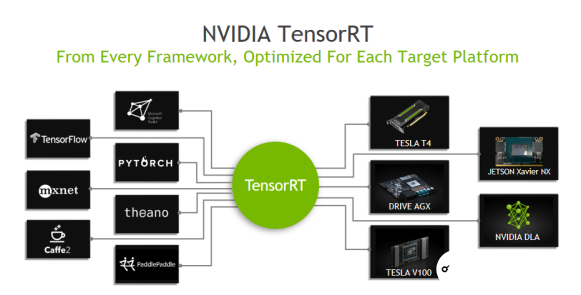
同时,英伟达提供DEEPSTREAM和ISSAC WORKFLOW两款SDK。DEEPSTREAM SDK提供了一整套数据流分析工具包,透过智能视频分析(IVA)和多传感器的数据处理来感知情景和意识。
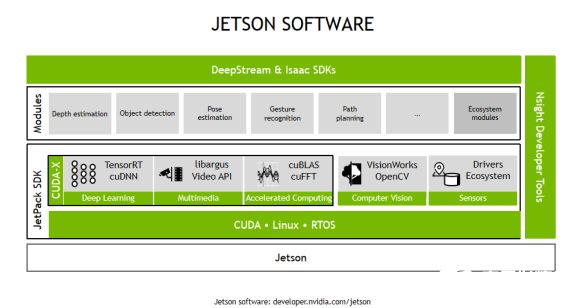
ISSAC SDK 是一个机器人软件开发工具包,ISSAC Robot Engine 方便在不同的平台上部署机器人应用,ISSAC GEMs集成了许多机器人感知导航算法模块,并且许多有GPU加速,给机器人开发提供便利。
JETSON系列共有四款芯片,包括JETSON NANO、TX2 series、AVIER NX、AGX XAVIER series,覆盖从0.5TFLOPS到32TOPS的算力需求。考虑到许多设备都受限于小尺寸和低功耗,为此英伟达推出了全新的Jetson Xavier NX,使用户能够在不增加设备尺寸或功耗的情况下,大幅提高AI性能。
JETSON产品系列作为人工智能的边缘计算平台,将以强大的生态体系带给更多场景的落地应用。
新思科技:边缘端AI的延迟、可靠性问题
由于云端计算存在着延迟、数据传输成本高、可靠性等问题,许多的AI计算将在边缘端承载。相关的典型案例,例如NETFLIX作为一家视频流服务公司,部署了许多边缘端的服务器,处理传输的优化和搜索。海康NVR在本地处理摄像头的视频流数据。
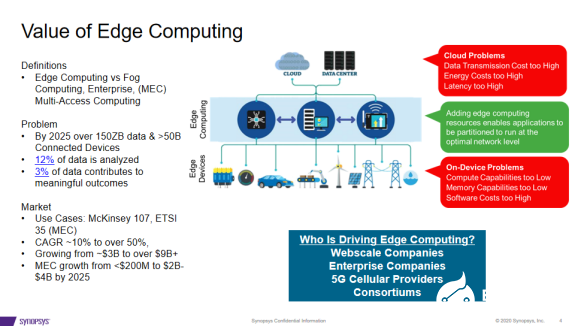
边缘计算对半导需求的影响主要在五个方面,在整个网络基础架构中添加服务器架构;人工智能嵌入所有系统;低功耗服务SOC芯片的应用;低延迟网络的需求,低延迟处理要求。而边缘AI将刺激AR/VR、机器人、游戏等低延迟应用的爆发。
Synopsys新思科技IP产品方案销售总监钟香建在针对AI加速器SOC的发展时谈到,大部分的AI加速器采用了12nm和7nm工艺,其实是14nm工艺。它的系统框架中采用了LPDDR、HBM2e、PCIe5.0、CXL等接口,以满足芯片或DIE到DIE之间的高速传输需求。其中,PCIe 4.0和5.0提供了当今AI SOC中最常用的接口,实现了可靠和可信的连接。CXL提供从主机到加速器的低延迟、缓存一致性连接。PCIe Switch有助聚合芯片阵列。Synopsys是PCIe IP领域的领导者,现在提供PCIe Switch IP来实现定制的AI聚合,提高系统性能。
此外,新思ARC EV处理器IP可使用标量、矢量、NN引擎完成人工智能处理,LPDDR IP提供低功耗、低成本的存储方案,HBM2 IP提供高带宽和高能源效率的方案,实现以最小的功耗和低延迟实现内存的吞吐量要求等。
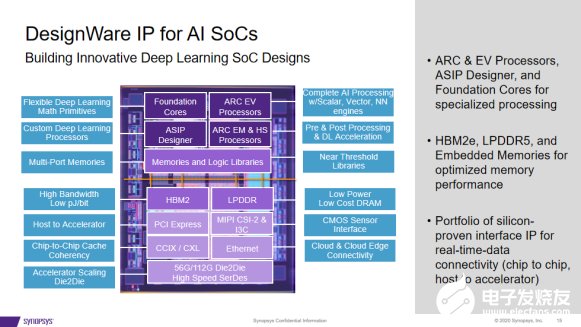
通过边缘计算和5G的新应用及服务预计将出现强劲增长。DesignWareIP正在解决所需的关键延迟、可靠性和性能改进。
英特尔: OpenVINO™工具包助力人工智能开发
英特尔的合作伙伴架构师马小龙,为我们介绍了英特尔为边缘AI应用的开发、部署和上市推广,提供了怎样的软硬件平台和资源。
人工智能正在改变每一个行业的体验和定义,在图像和语音识别领域,机器已经能够达到甚至超过人类的水平。随着用户对于人工智能延迟和性能要求的提升,边缘端的人工智能在今年获得了快速发展。边缘人工智能近年来在安防,智能城市,零售,制造和视频等行业领域都获得了广泛应用。
英特尔提供了人工智能应用开发的完整生态资源,首先开发者可以借助OpenVINO对已训练好的模型进行优化和异构部署; OpenVINO工具包是一项用于高性能深度学习推理的工具套件,借助OpenVINO可以更快更准确地将人工智能应用产品化,并从边缘到云基于英特尔架构来部署。同时该工具包使用了同一个API,可以实现一次编写,任意部署,因此可以大大降低人工智能应用迁移所需的开发工作量。已训练模型通过模型优化器(支持TensorFlow、Caffe等多种模型)转化成中间表示格式,再通过推理引擎部署在不同的英特尔架构上。
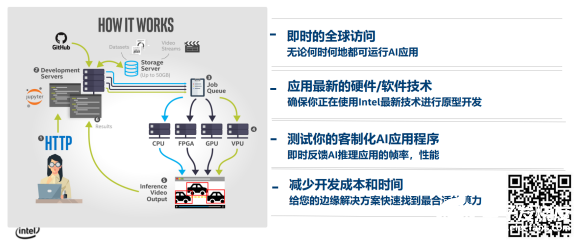
在测试与集成阶段,英特尔提供了Dev Cloud边缘开发云和物联网开发人员套件来加快产品落地,上市阶段也提供了边缘软件中心。若是目前手头没有配置好的OpenVINO开发环境或缺少相应的英特尔产品进行部署,就可以借助边缘开发云来快速部署和测试。Dev Cloud不仅提供了开发服务器、存储服务器,还拥有一系列不同边缘节点。而物联网开发人员套件中,既有即插即用的神经计算棒,也有基于酷睿处理器的多场景开发套件和加速卡。

为了解决性能限制、快速上市和异构部署的挑战,减少底层开发工作,英特尔也推出了边缘软件中心。该软件中心里包含了针对多应用的边缘洞见软件包,同时附带商用级别的参考示例,也和多个合作伙伴推出了经验证的边缘设备。
研华:基于Intel Movidius VPU及海思SoC的边缘AI解决方案
接下来,研华科技IoT嵌入式平台事业群物联网行业经理鞠剑为我们分享了基于Intel Movidius VPU及海思SoC这两大不同硬件平台的边缘AI方案。
英特尔的OpenVINO支持四大硬件架构,CPU、GPU、FPGA和VPU,其中的VPU就是Movidius系列产品。研华目前采用的是英特尔于2019年第四季度发布的Intel® Movidius™ Myriad™ X VPU,芯片型号为MA2485,该芯片相对Myriad 2 VPU在深度神经网络上的性能高出10倍,算力达4TOPS,专用神经网络算力达1TOPS,而且拥有超低功率,不到4W。研华基于该芯片推出了一整套边缘AI解决方案,既有加速模块也有推理系统。

这其中AI VPU加速模块已量产的有VEGA-320、VEGA-330、VEGA-340,而VEGA-341是下一代,预计在今年Q3正式量产。
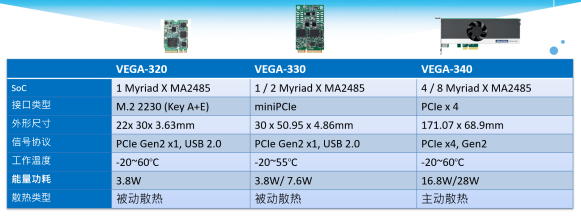
其中VEGA-320集成了MA2485芯片,接口为M.2 2230,主要应用于弱AI场景,比如交通/视频监控和信息亭/零售行业等;VEGA-330可集成1或2颗MA2485芯片,接口为mini PCIe,主要应用于工业级的AGV还有无人机/机器人领域;前两个加速模块都采用被动散热。VEGA-340是插卡式产品,可集成4或8颗MA2485,接口为PCIe x 4,采用主动散热,更适合医学影像和AOI这类强AI领域。VEGA-320和VEGA-330除了自带的标准散热器外,还可以选配效果更好的伴散热器。

在未加入AI VPU的情况下,测试的人脸识别案例平均每秒帧数为110,CPU负载在100%,能耗为27W。加入了VEGA-330之后,不仅提升了10FPS,还释放了50%的CPU负债。在额外加入硬件的情况下,反而将功耗降低了30%,功率达到18.9W。
AGV:VEGA-330边缘 AI 推断模块(VPU * 2)集成到他的 AGV 购物车中。这使得 AGV 能够通过摄像机视觉进行自主导航,并执行障碍物检测,以避免在人机混合工作场所发生事故。
AI纺织品缺陷检查:通过带有八个Intel Movidius VPU的研华VEGA-340可在分布式织机上进行实时AI检查。控制系统可以根据检测结果立即做出反应,提高生产质量和效率。
在研华推出的边缘推理系统中,Ei-A100主要用于教育零售领域,而AIR-200更适合AGV场景,EPC-C301则主要用于工厂自动化和机械臂等复杂场景。EPC-C301带有4个USB3.2摄像头接口,和CAN2.0自动化控制接口,选用了无风扇散热设计。
机器手臂AI(视觉)升级:将传统机械手臂进行视觉定位升级,通过EPC-C301内置的VEGA-330边缘AI推断模块,帮助客户进行运动轨迹辅助判断。使用手臂前端的摄像机进行自主运动,精确导航。
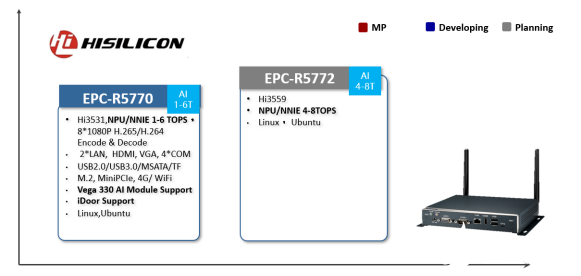
除了基于英特尔VPU的AI方案,研华科技也针对海思的SoC推出了自己的一套边缘AI智能物联网网关方案。目前正在研发的EPC-R5770就采用了海思的Hi3531。这款海思的SoC在视频编码能力很强,支持8路1080P H.265/H.264编解码。除了多路接口外,还支持附加VEGA-330的模组。EPC-R5772尚在计划中,选用的还是HI3559,各项参数仍然待定。
本次人工智能大会的圆桌论坛环节,由电子发烧友产业分析师张慧娟主持,邀请到Imagination公司时昕、英伟达公司李雨倩以及研华科技的鞠剑等数位嘉宾,共同探讨了AI新周期的新挑战,AI如何走向规模和普惠的话题。
更多关于2020年第三届中国人工智能大会暨首届中国人工智能卓越创新奖的详情,请点击官网链接:http://www.elecfans.com/activity/ai-2020/index.html。
-
 zhetian
2020-07-14
0 回复 举报百度的那位首席科学家叫吴恩达 收起回复
zhetian
2020-07-14
0 回复 举报百度的那位首席科学家叫吴恩达 收起回复
-
帝奥微第三届经销商大会圆满举行2025-12-26 809
-
奇异摩尔出席第三届芯粒开发者大会AI芯片与系统分论坛2025-07-22 1597
-
线上逛展 | 沉浸探索第三届OpenHarmony技术大会五大展区2024-10-24 1342
-
高燃回顾|第三届OpenHarmony技术大会精彩瞬间2024-10-16 1840
-
30s高能速递 | 第三届 OpenHarmony技术大会精彩抢鲜看2024-10-08 932
-
第三届中国电磁频谱学术大会圆满落幕,知语科技闪耀西安!2024-06-24 1728
-
第三届中国计算机教育大会圆满落幕2022-03-31 2780
-
是德2020第七届中国IoT大会AI技术运用方案资料2020-12-14 5459
-
2020年人工智能大会 线上直播2020-01-15 7398
-
邀请函 | 第三届全球智能工业大会倒计时!2019-11-20 2008
-
Nibiru 第三届 N+ 大会将于软博会期间举行,欢迎莅临~2018-08-07 1943
-
第三届中国硬件创新创客大赛总决赛精彩直播回放2017-11-22 5095
-
2016第三届中国IoT大会影响力报告2017-01-04 1322
-
第三届中国IoT大会—智能照明分论坛重磅来袭2016-11-11 4319
全部0条评论

快来发表一下你的评论吧 !
