

80页笔记看遍机器学习基本概念、算法、模型
描述
本文要介绍的是一份长约 80 页的学习笔记,旨在总结机器学习的一系列基本概念(如梯度下降、反向传播等),不同的机器学习算法和流行模型,以及一些作者在实践中学到的技巧和经验。
如果你是一个刚刚入门机器学习领域的人,这份学习笔记或许可以帮你少走很多弯路;如果你不是学生,这些笔记还可以在你忘记某些模型或算法时供你快速查阅。必要时,你可以使用 Ctrl+F 搜索自己想知道的概念。
笔记共分为以下六大部分:
激活函数
梯度下降
参数
正则化
模型
实用窍门
在第一部分「激活函数」中,作者提供了 Sigmoid、tanh、Relu、Leaky Relu 四种常用的机器学习激活函数。

第二部分「梯度下降」又分为计算图、反向传播、L2 正则化梯度、梯度消失和梯度爆炸等 12 个小节:

为了帮助读者理解,作者举了一些例子,并对很多内容进行了可视化的展示:
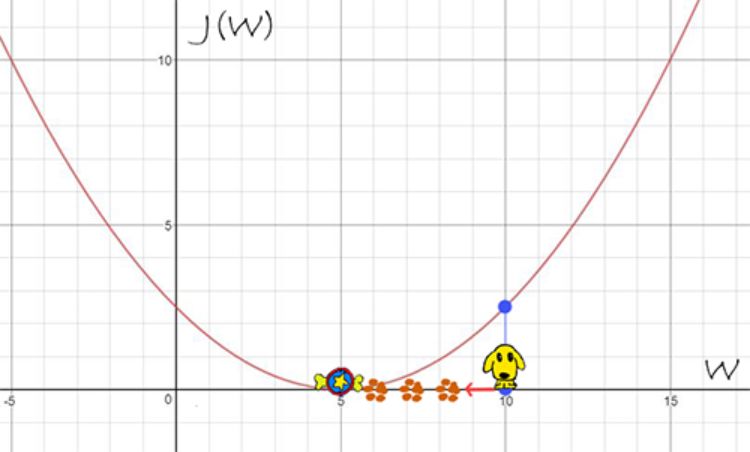
梯度下降
笔记的第三部分是机器学习中的参数,又分为可学习参数和超参数、参数初始化、超参数调优等几个小节。
为了防止新手走弯路,作者在「参数初始化」部分的开头就提醒道:其实,TensorFlow 等机器学习框架已经提供了鲁棒的参数初始化功能。类似的提醒在笔记中还有很多。 
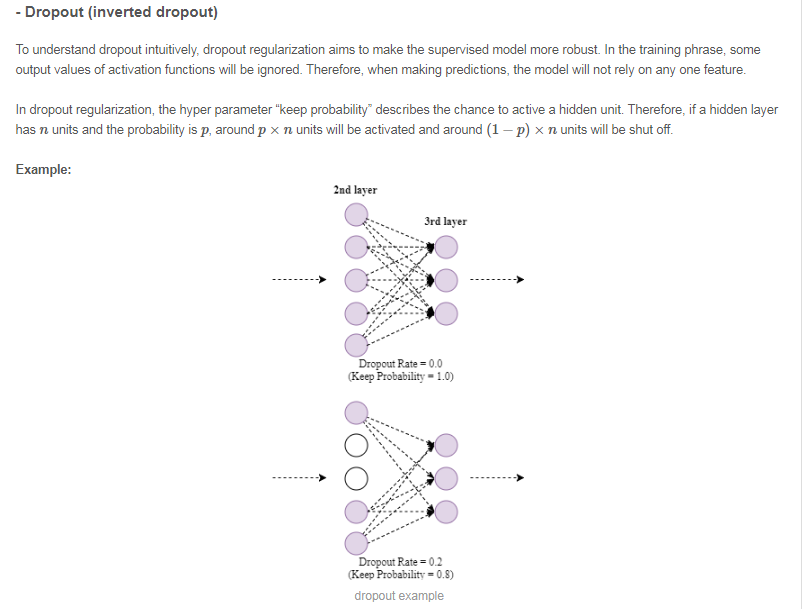
笔记的第四部分是正则化,包含 L2 正则化、L1 正则化、Dropout、早停四个小节。
第五部分是整份笔记的重中之重,详细描述了逻辑回归、多类分类(Softmax 回归)、迁移学习、多任务学习、卷积神经网络(CNN)、序列模型、Transformer 和 BERT 等八大类机器学习模型。并且,八大类模型下面又分为各个小类进行详解,具体如下所示:

解释相对简单的前四类机器学习模型。

解释最为详尽的卷积神经网络(CNN),包括 Filter/Kernel、LeNet-5、AlexNet、ResNet、目标检测、人脸验证以及神经风格迁移等。

序列模型,包括常见的循环神经网络模型(RNN)、Gated Recurrent Unit(GRU)、LSTM、双向 RNN、深度 RNN 示例、词嵌入、序列到序列翻译模型示例等。

Transformer 和 BERT 模型。
笔记最后一部分给出了一些「实用窍门」,包括训练/开发/测试数据集、不匹配的数据分布、输入归一化以及误差分析等 6 方面内容。其中有些窍门来自 Deep Learning AI 等在线课程,还有一部分是作者自己总结得到的。
-
NPU与机器学习算法的关系2024-11-15 2430
-
深度学习基本概念2023-08-17 3957
-
如何评估机器学习模型的性能?机器学习的算法选择2023-04-04 1869
-
常用机器学习算法的基本概念和特点2023-01-17 4948
-
FOC控制的基本概念2021-09-07 2318
-
人工智能基本概念机器学习算法2021-09-06 2790
-
详谈机器学习模型算法的质量保障方案2021-05-05 3096
-
决策树的基本概念/学习步骤/算法/优缺点2021-01-27 3385
-
理解机器学习中的算法与模型2020-07-31 4093
-
机器学习算法基本概念及选用指南2019-01-15 3551
-
什么是机器学习_十张图带你解析机器学习的基本概念2018-06-30 4347
-
机器学习的算法应用2017-08-24 3287
-
【阿里云大学免费精品课】机器学习入门:概念原理及常用算法2017-06-23 3614
全部0条评论

快来发表一下你的评论吧 !
