

基于FPGA上实现硬件入侵检测系统的设计
可编程逻辑
描述
1 引言
随着互联网的飞速发展,网络流量不断增大、网络攻击类型层出不穷。入侵检测的高速度、低漏检率、低误报率等要求,使传统的以软件为核心的 IDS面临着越来越大的压力。仅靠模式匹配算法的改进对入侵检测速度的提高是有限的,不是解决问题的根本策略。
通过对入侵检测系统中检测速度瓶颈及模式匹配算法的分析,提出了基于硬件实现入侵检测的策略。在系统中用硬件代替传统入侵检测系统中的软件实现主要部件功能:如数据采集和过滤、多模式匹配及数据包调度等,硬件实现比软件实现的速度能显著提高。
2 系统设计
系统原型的设计基于SOPC技术,采用了多处理器并行处理结构、可扩充指令集和协处理器加速算法等设计思想。其核心内容是采用多级并行处理技术和专用功能部件代替复杂费时算法,以获得极大的数据包处理性能。
1. 系统总体结构设计
原型系统的主要部件有数据采集模块、报文分派器、软核处理单元、模式匹配协处理器、自定义指令、主控通路接口及响应输出等。系统的体系结构如图 1所示。
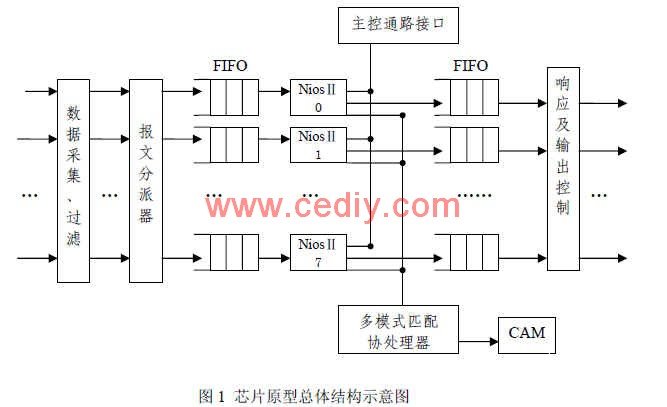
为了解决高速网络环境下入侵检测系统的检测速度瓶颈问题,在入侵检测过程的各个环节中,各处理器部件都必须能线速处理数据包。本系统中采用硬件模块实现数据采集功能,对数据包的分析检测模块采用并行处理的方法来提速;另外还采用协处理器来加速完成模式匹配过程。基于 FPGA协处理器能够加速多种不同的算法,其获得的性能是软件实现性能的几十倍。
2.数据采集部件
传统的网络数据截获用软件实现,通过函数拷贝 MAC缓冲区内的数据包来实现数据采集,运行速度低,丢包率高。本系统中的数据采集和过滤模块直接用硬件实现。当输入端口有数据进来时,过滤单元选择性的把需要的数据拷贝到 Buffer中,具有很高的采集速度,在千兆环境下丢包率很低。
报文分派器按照公平的轮询策略依次从输入通路上读取 IP报文,然后根据输入缓冲中 FIFO的空闲状况,将 IP报文分派到软核处理器的输入缓冲 FIFO中。
3.软核处理器单元
使用SOPC Builder定义网络处理器原型芯片中的并行处理单元 ——Altera NiosⅡ处理器软核。定义中需要设置各种硬件参数,包括工作频率、cache选项、加电引导方式、中断寄存器设置、内存大小、Flash基地址以及各种的访问模式和地址映射等。依次对多个处理器软核进行描述,并因此生成每个处理器软核的逻辑符号和软件编程接口,生成.elf文件。对芯片原型中的其他硬件逻辑设计采用硬件描述语言,生成的硬件配置数据与处理器软核的.elf文件合成用于配置芯片原型 FPGA的.hex文件。
本系统芯片原型内的多个 PE采用并行结构,各个 PE有自己的数据和指令存储器,共享模式匹配协处理器模块。PE之间的通信使用并行通信接口 PIO来实现。其中 NiosⅡ是微处理器软核,RAM和 Cache存放指令和数据, Load_Header和 Send_Header是报文头输入 /
输出逻辑,Lookup Controllor是多模式匹配协处理器接口逻辑, Cam_update Controllor是规则表管理逻辑接口,PIO是并行通信接口。
4. 协处理器设计
尽管有软件模式匹配算法的改进,模式匹配仍然是高速流量分析的限制。我们通过下载所有模式匹配任务到可重配置的 FPGA协处理器来消除这个瓶颈。 FPGA能对 Snort规则中每种模式与包内容进行比较,整个规则集装入在一个低端 FPGA设备上。
本系统中处理器软核 NiosⅡ共享匹配查表协处理器,采用总线仲裁器共享机制。每个处理器软核有一个匹配查表协处理器的接口控制器 Lookup,它作为自定义指令逻辑包含在处理器软核内部。匹配查表协处理器与处理器软核并行工作,通过查询方式判断协处理器工作是否结束。协处理器使用 CAM存放规则表。 3 系统关键技术及实现
1. 多处理器技术
PE(Processor Element)是网络处理器的核心部件,承担系统内主要计算任务,每个 PE实际上是一个微处理器核。网络处理器通常包括多个 PE,PE之间有两种主要连接方式:并行连接和串行连接。
2. 多级并行处理技术
网络数据包处理存在本质上的并行性,为了昀大限度地提高报文处理速度,满足网络应用的需求,网络处理器实现不同层次并行处理:实现处理器级并行处理、通过硬件多线程实现线程级的并行处理、通过指令流水线实现指令级的并行处理。处理器间的并行还可以分为 PE之间的并行运行及 PE与协处理器之间的并行。
3. 硬件线程和 “0开销”切换技术
PE内部采用硬件多线程技术,每个 PE中有多个硬件线程,硬件线程是指享有独立的程序计数器、寄存器和存储空间的线程。 “0”延迟切换原理是:硬件线程在进行线程切换时,既不需要保存将要停止运行的线程的现场信息,也不需要恢复即将运行的就绪进程的现场信息,因此不消耗 PE资源,能做到“0开销”切换。NP利用硬件线程掩盖了线程切换的延迟,提高了 PE的运行效率。一般地,通过合理设计调度策略,PE运行效率可接近 。
4. 分布式数据存储技术
存储器也是网络处理器的关键,其存取速度和带宽是影响网络处理器性能的重要因素。按照存储转发的思想,所有报文进入网络处理器后必须缓存。要线速处理报文,报文的输出速度必须与输入速度一致,既存储器带宽是端口速度的两倍以上,这对目前存储器是一个巨大的挑战。
一方面,NP采用数据分布式存储结构。NP内设置多级存储器:片上快速存储器和片外慢速存储器。另一方能,网络处理器采用数据预取、块传送、高速数据通路等技术来解决高速计算和高速数据传送的问题。
5.系统实现
本系统是面向入侵检测的网络处理器原型,入侵检测的流程包括数据采集、数据包预处理、数据包检测、及响应四个步骤。原型系统将入侵检测的主要工作,如数据采集及过滤、多模式匹配、数据包在多处理单元上的分派等用硬件实现,而数据包的分析检测也用多个处理单元进行并行处理。
该原型系统包括:一个主控模块、一个硬件数据采集模块、八个软核并行处理单元、一个多模式匹配协处理器。系统采用报文分派器完成 IP报文到核处理器的分派任务,软核微处理器对报文做入侵检测。每个软核微处理器都拥有一个输入缓冲 FIFO和输出缓冲 FIFO,用于缓冲需要处理的报文。响应和输出控制模块根据报文的检查结果,决定是否作为非法包丢弃还是作为正常包转发到相应的输出数据通路上。 4 系统测试及性能分析
为了进行系统测试,开发了如图 2所示的验证平台。系统原型验证平台使用多片 FPGA实现各种功能接口,同时将网络处理器的核心功能在单个 FPGA芯片中实现,用于支持网络处理器控制功能和系统管理功能的主控模块也采用一个独立的 FPGA实现。
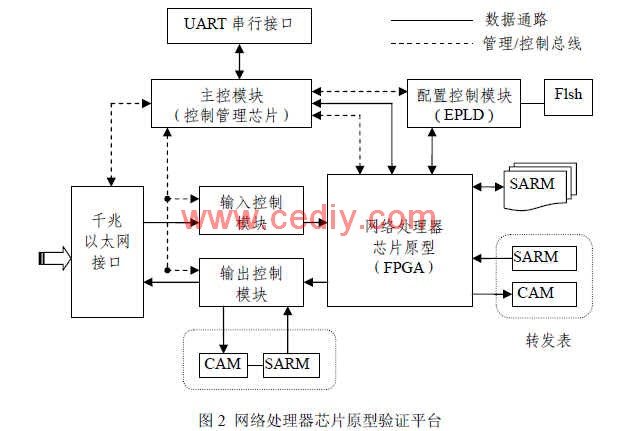
系统性能测试在系统验证平台下进行。通过JTAG接口将验证平台与微机相连,使用IDE开发环境进行软件调试。报文生成器是 FPGA内的一个模块,使用它能产生变长的连续报文。网络处理器芯片的输入端接收 33位数据( 32位数据和 1位标志位),经报文分派器分配给多个 PE进行处理。每个 PE对报文头进行解析,并查找规则表,产生 11位转发控制信息用于输出控制。
在 FPGA上进行模式匹配的重要性能指标是吞吐率。我们通过输入不同大小的数据包进行实验,实验结果如表 1所示。
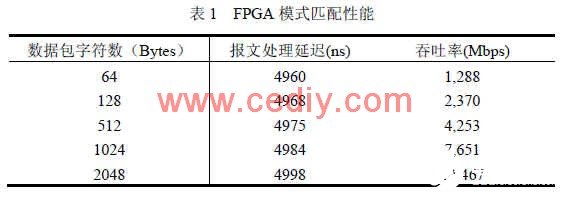
PE读取第一个报文头到读取第二个报文头的时间为 246个时钟周期,报文处理延迟为 4920ns,实验测量值与计算值基本符合。实验中系统每秒处理 330K个报文,系统的吞吐率与报文长度有关,总的吞吐率理论上可达到 14Gbps,但理论值只有在 PE与协处理器满负荷运行下才有可能获得。从表 1还可看出,在 FPGA内部随着资源使用的增加,内部延迟会增加,吞吐率稍有降低。
5 小结
通过对入侵检测系统中检测速度瓶颈的分析,设计了一个基于硬件的入侵检测系统原型。该原型采用基于网络处理器的硬件策略取代传统入侵检测的软件策略,实验证明该系统的性能与传统方法相比有显著的提高,很好地解决了入侵检测中的速度问题。系统都是在基于 FPGA上实现的,并可以根据实际需要增加硬件和自定义指令来提高系统性能。
本文作者创新点:设计了一个基于 SOPC网络处理器的入侵检测系统原型,将入侵检测的主要工作用硬件来实现,与传统的基于软件策略相比性能有显著的提高。
责任编辑:gt
-
分布式入侵检测系统的设计2009-03-10 2689
-
红外入侵检测系统有什么优点?2020-03-18 2297
-
具有双检测点的入侵检测系统设计与实现2009-05-26 858
-
利用KNN算法实现基于系统调用的入侵检测技术2009-06-13 779
-
基于数据挖掘的入侵检测系统设计和实现2009-08-04 613
-
基于Apriori改进算法的入侵检测系统的研究2009-08-10 646
-
基于数据挖掘的入侵检测系统研究2009-08-13 900
-
入侵检测报警聚合与关联系统设计与实现2009-08-26 709
-
支持计算机取证的入侵检测系统的设计与实现2009-08-29 773
-
基于专家系统的入侵检测系统的实现2009-08-31 473
-
基于水印追踪技术的入侵检测系统的研究2009-09-02 666
-
基于粗糙集理论的网络入侵检测系统2010-01-15 836
-
数据挖掘技术在入侵检测系统中的实现2010-01-22 1257
-
基于ZigBee协议的红外入侵检测系统的设计2009-12-05 1838
-
在FPGA上构建EVM硬件的实现2023-06-26 1412
全部0条评论

快来发表一下你的评论吧 !
