

FPGA中使用FP16格式的点积运算实例分析
可编程逻辑
描述
Achronix资深现场应用工程师,杨宇
神经网络架构中的核心之一就是卷积层,卷积的最基本操作就是点积。向量乘法的结果是向量的每个元素的总和相乘在一起,通常称之为点积。此向量乘法如下所示:
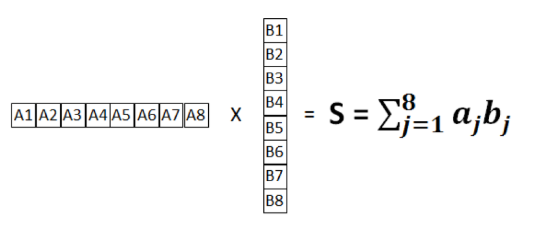
图1 点积操作
该总和S由每个矢量元素的总和相乘而成,因此S=a1b1+a2b2+a3b3+···anbn
本文讲述的是使用FP16格式的点积运算实例,展示了MLP72支持的数字类型和乘数的范围。
此设计实现了同时处理8对FP16输入的点积。该设计包含四个MLP72,使用MLP内部的级联路径连接。每个MLP72将两个并行乘法的结果相加(即aibi+ai+ai+1bi+1),每个乘法都是i_a输入乘以i_b输入(均为FP16格式)的结果。来自每个MLP72的总和沿着MLP72的列级联到上面的下一个MLP72块。在最后一个MLP72中,在每个周期上,计算八个并行FP16乘法的总和。
最终结果是多个输入周期内的累加总和,其中累加由i_first和i_last输入控制。 i_first输入信号指示累加和归零的第一组输入。 i_last信号指示要累加和加到累加的最后一组输入。最终的i_last值可在之后的六个周期使用,并使用i_last o_valid进行限定。两次运算之间可以无空拍。
● 配置说明
表 1 FP16点积配置表

● 端口说明

表2 FP16点积端口说明表
● 时序图
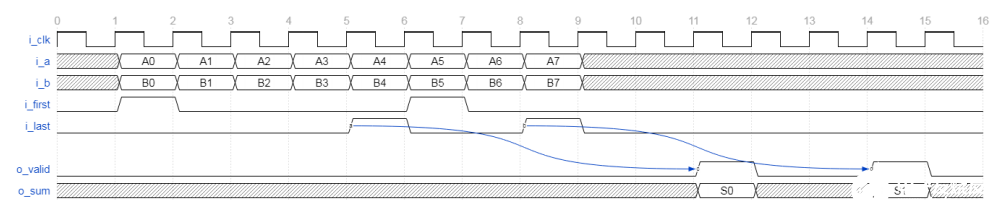
图2 FP16点积时序图
其中,
● 进位链
首先请看下图,MLP之间的进位链结构,这是MLP内部的专用走线,可以保证级联的高效执行。

图3 MLP进位链
● 乘法阶段
下图是MLP中浮点乘法功能阶段,其中寄存器代表一级可选延迟。

图4 MLP乘法功能阶段框图
MLP72浮点乘法级包括两个24位全浮点乘法器和一个24位全浮点加法器。两个乘法器执行A×B和C×D的并行计算。加法器将两个结果相加得到A×B + C×D。
乘法阶段有两个输出。下半部分输出可以在A×B或(A×B + C×D)之间选择。上半部分输出始终为C×D。
乘法器和加法器使用的数字格式由字节选择参数以及和参数设置的格式确定。
浮点输出具有与整数输出级相同的路径和结构。MLP72可以配置为在特定阶段选择整数或等效浮点输入。输出支持两个24位全浮点加法器,可以对其进行加法或累加配置。 进一步可以加载加法器(开始累加),可以将其设置为减法,并支持可选的舍入模式。
最终输出阶段支持将浮点输出格式化为MLP72支持的三种浮点格式中的任何一种。 此功能使MLP72可以外部支持大小一致的浮点输入和输出(例如fp16或bfloat16),而在内部以fp24执行所有计算。
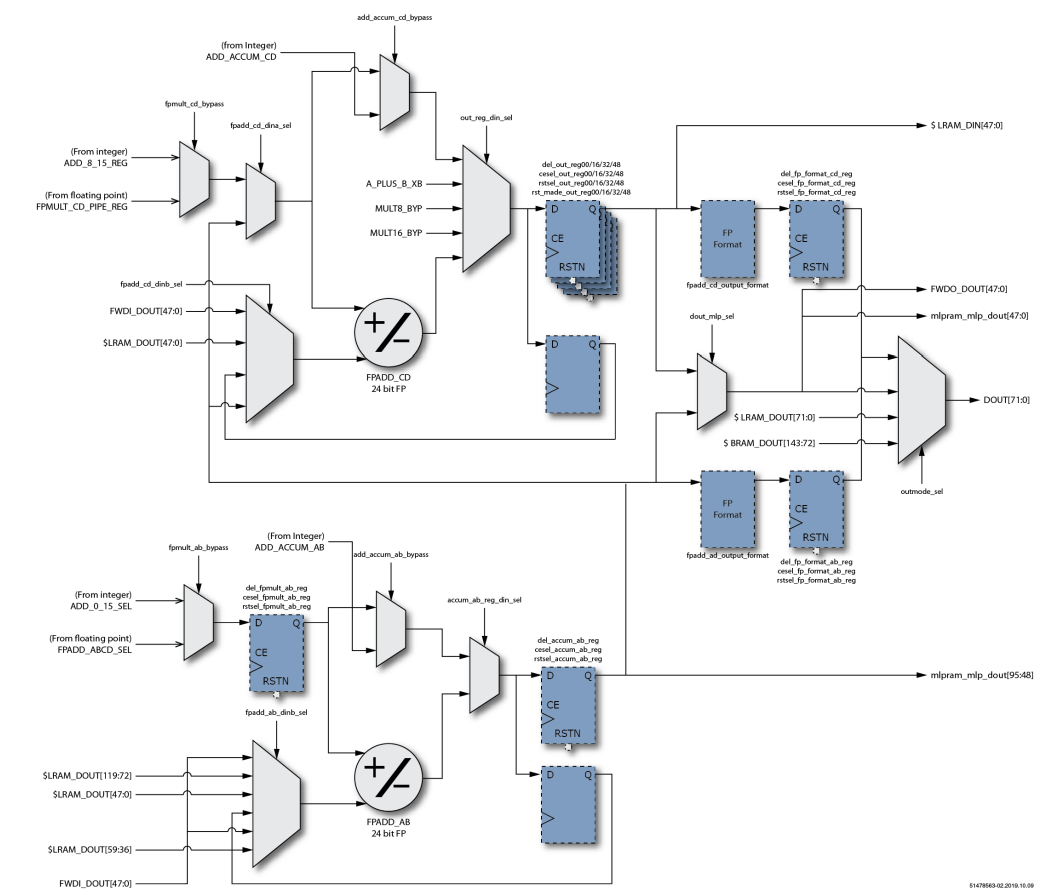
图5 MLP浮点输出阶段框图
需要强调的是本设计输入和输出都是FP16格式,中间计算过程,即进位链上的fwdo_out和fwdi_dout 都是FP24格式。具体逻辑框图如下所示:
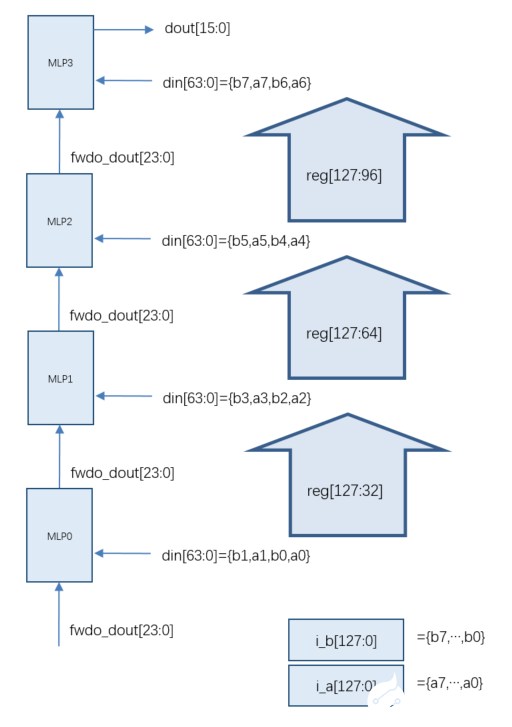
图 6 FP16点积逻辑框图
MLP内部数据流示意图:

图7 FP16点积在MLP内部数据流图
最终ACE的时序结果如下:
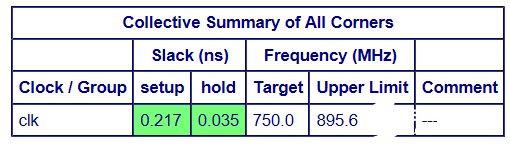
-
请问如何把WAV,MP3格式的音频文件转化为16位的数据IIS格式?2024-10-23 1082
-
Optimum Intel / NNCF在重量压缩中选择FP16模型的原因?2025-03-06 537
-
谁帮我转下99格式?2018-06-13 3861
-
使用运算放大器带宽计算的设计实例2018-09-13 3389
-
实例!详解FPGA如何实现FP16格式点积级联运算2020-08-18 2682
-
详解天线系统解决方案中的FP16格式点积级联运算2020-09-04 2178
-
推断FP32模型格式的速度比CPU上的FP16模型格式快是为什么?2023-08-15 781
-
什么是MP3格式2009-12-21 6801
-
如何使用FPGA实现FP16格式点积级联运算2020-08-15 2911
-
使用FPGA VHDL实现电子点餐项目设计的参考实例资料合集2020-12-23 1131
-
FPGA如何实现FP16格式点积级联运算2022-09-06 1843
-
NVIDIA GPU架构下的FP8训练与推理2024-04-25 4803
-
MOV格式与MP4格式的区别2024-12-06 11043
-
计算精度对比:FP64、FP32、FP16、TF32、BF16、int82025-06-26 3423
-
小白必读:到底什么是FP32、FP16、INT8?2025-10-20 1919
全部0条评论

快来发表一下你的评论吧 !
