

分析解决MySQL数据库的数据延迟跳动
电子说
描述
今天分析了另外一个关于数据库延迟跳动的问题,也算是比较典型,这个过程中也有一些分析问题的方法和技巧工参考。
首先在高可用检测中,有一套环境的检测时断时续,经过排查发现是数据库产生了延迟,在登录到从库show slave status查看,会发现Seconds_behind_master的值是不断跳动的,即从0~39~0~39这样的频率不断跳动,让人很搓火。
查看数据库的相关日志发现竟然没有任何可以参考的日志记录,怎么分析这个问题呢,我们先来复现,于是我按照节奏抓取了3次问题出现的日志,即通过show slave status连续监测,抓取show slave status输出的结果保存下来,这样我们就得到了一个问题发生过程中的偏移量变化,而这个变化则是在SQLThread在回放过程中产生的问题。
比如下面的一段输出,我截取的是Slave端的relay log进行分析,相应的字段为Relay_Log_Pos
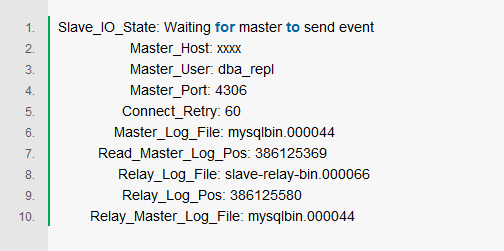
所以很快得到了偏移量的变化情况:385983806 ,386062813 ,386125580
接着我使用mysqlbinlog开始分析这些日志过程中的明细,根据如下的命令可以很快得到转储的日志中相关的表有3张。

我逐步分析了每张表的数据操作情况,得到的信息还是比较有限,继续做更进一步的分析,比如我们分析一下整个日志中的事务量大小:
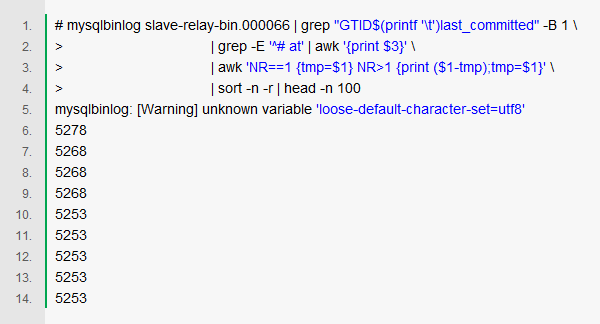
可以看到是5K左右,算是比较大了,而这些额外的信息从哪里获得呢,我在主库开启了general_log,这样就能够得到更细粒度的操作日志了。
进一步分析发现,整个业务使用了显示事务的方式:SET autocommit=0,整个事务中包含了几个大SQL,里面存储了很多操作日志明细,而且在事务操作过程中还基于Mybatis框架调用了多次select count(1) from xxx的操作。
经过和业务沟通也基本明确了以上问题。
-
labview有调用mysql数据库问题????2014-05-19 3385
-
mysql数据库设计步骤2019-05-13 2817
-
MySQL数据库使用2019-10-24 1530
-
MySQL数据库如何安装和使用说明2020-02-13 3623
-
华为云数据库-RDS for MySQL数据库2022-10-27 2604
-
有哪些不同的MySQL数据库引擎?2023-04-03 2386
-
MySQL数据库管理与应用2023-08-28 2059
-
mysql是一个什么类型的数据库2023-11-16 3299
-
MySQL数据库基础知识2023-11-21 2115
-
mysql数据库基础命令2023-12-06 1672
-
数据库数据恢复—未开启binlog的Mysql数据库数据恢复案例2023-12-08 2330
-
数据库数据恢复—MYSQL数据库ibdata1文件损坏的数据恢复案例2024-12-09 1523
-
数据库数据恢复—Mysql数据库表记录丢失的数据恢复流程2024-12-16 1485
-
MySQL数据库的安装2025-01-14 1421
-
MySQL数据库是什么2025-05-23 1616
全部0条评论

快来发表一下你的评论吧 !
