

手把手教你在机器学习过程设计Python接口
电子说
描述
前言
为了进行机器学习工程,首先要部署一个模型,在大多数情况下作为一个预测API。为了使此API在生产中工作,必须首先构建模型服务基础设施。这包括负载平衡、扩展、监视、更新等等。
乍一看,所有这些工作似乎都很熟悉。Web开发人员和DevOps工程师多年来一直在自动化微服务基础设施。当然,我们可以重新定位他们的工具?
不幸的是,我们不能。
虽然ML的基础结构与传统的DevOps类似,但它与ML的特殊性足以使标准的DevOps工具不那么理想。这就是为什么我们开发了Cortex——机器学习工程的开源平台。
在一个非常高的层次上,Cortex被设计用来简化在本地或云上部署模型,从而自动化所有底层基础设施。该平台的一个核心组件是预测器接口——一个可编程Python接口,开发人员可以通过该接口编写预测api。
设计一个专门为web请求提供预测的Python接口是一个挑战,我们花了几个月的时间(目前仍在改进)。在这里,我想分享一些我们已经开发的设计原则:
1.预测器只是一个Python类
Cortex的核心是我们的预测器,它本质上是一个预测API,包括所有的请求处理代码和依赖关系。预测器接口为这些预测api实施了一些简单的需求。
因为Cortex采用微服务的方式来进行模型服务,预测器界面严格关注两件事:
初始化模型
提供预测
在这种精神下,Cortex的预测界面需要两种功能,即剩余的init__()和predict(),它们或多或少做你所期望的事情:
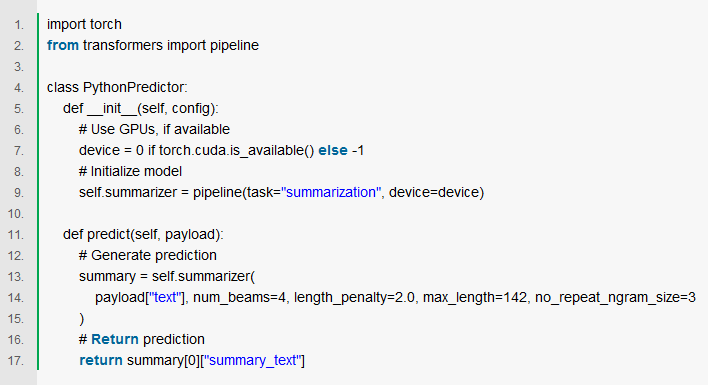
初始化之后,您可以将一个预测器看作一个Python对象,当用户查询端点时,将调用它的单个predict()函数。
这种方法的最大好处之一是,对于任何有软件工程经验的人来说,它都是直观的。不需要接触数据管道或模型训练代码。模型只是一个文件,而预测器只是一个导入模型并运行predict()方法的对象。
然而,除了语法上的吸引力之外,这种方法还提供了一些关键的好处,即它如何补充了皮层更广泛的方法。
2. 预测只是一个HTTP请求
为生产中提供预测服务而构建接口的复杂性之一是,输入几乎肯定会与模型的训练数据不同,至少在格式上是这样。
这在两个层面上起作用:
POST请求的主体不是一个NumPy数组,也不是您的模型用来处理的任何数据结构。
机器学习工程就是使用模型来构建软件,这通常意味着使用模型来处理它们没有受过训练的数据,例如使用GPT-2来编写民间音乐。
因此,预测器接口不能对预测API的输入和输出固执己见。预测只是一个HTTP请求,开发人员可以随意处理它。例如,如果他们想部署一个多模型端点,并基于请求参数查询不同的模型,他们可以这样做:

虽然这个界面让开发者可以自由地使用他们的API做什么,它也提供了一些自然的范围,使皮质在基础设施方面更加固执己见。
例如,在后台Cortex使用FastAPI来设置请求路由。Cortex在这一层设置了许多与自动排序、监控和其他基础设施功能相关的过程,如果开发人员需要实现路由,这些功能可能会变得非常复杂。
但是,因为每个API都有一个predict()方法,所以每个API都有相同数量的路由—1。假设这允许Cortex在基础设施层面做更多的事情,而不限制工程师。
3.服务模型只是一个微服务
对于在生产中使用机器学习的人来说,规模是一个主要的问题。型号可能会很大(GPT-2大约是6 GB),计算成本高,并且可能有很高的延迟。特别是对于实时推断,扩大规模来处理流量是一项挑战——如果你的预算有限,情况更是如此。
为了解决这个问题,Cortex把预测器当作微型服务,可以水平伸缩。更具体地说,当开发人员进行Cortex部署时,Cortex将包含API,旋转为推理准备的集群,并进行部署。然后,它将API公开为负载平衡器背后的web服务,并配置自动缩放、更新和监视:
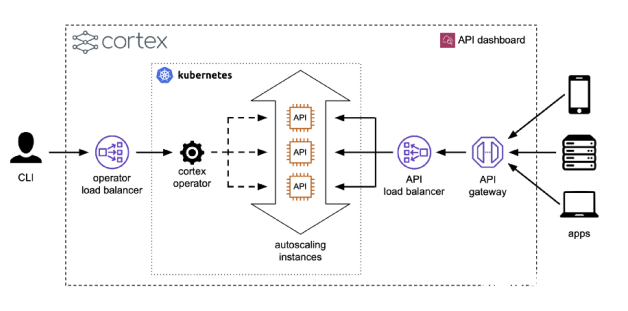
预测器接口是此过程的基础,尽管它“只是”一个Python接口。
预测器接口所做的是强制打包代码,使其成为推理的单个原子单元。单个API所需的所有请求处理代码都包含在一个预测器中。这使得大脑皮层能够很容易地衡量预测因素。
通过这种方式,工程师不必做任何额外的工作——当然,除非他们想做一些调整——准备一个用于生产的API。一个皮层的部署是默认的生产准备就绪。
-
手把手教你学FPGA仿真2023-10-19 1064
-
手把手教你学习Spyglass工具2023-04-03 6929
-
手把手教你学习STM322021-12-17 2173
-
手把手教你开关电源PCB排板2021-09-18 1942
-
手把手教你学LabVIEW视觉设计2019-03-06 3577
-
手把手教你如何开始DSP编程2018-04-09 1462
-
手把手教你在家搭建监控系统2017-01-17 1167
-
手把手教你安装Quartus II2016-09-18 1685
-
手把手教你学习FPGA—LED篇2016-08-08 982
-
原创手把手教你学习FPGA视频教程,不看后悔哟2013-08-14 34117
-
手把手教你制作机器人2012-08-12 19047
-
美女手把手教你如何装机(中)2010-01-27 1656
-
手把手教你写批处理-批处理的介绍2009-10-25 1400
-
手把手教你构建一个完整的工程2009-08-03 541
全部0条评论

快来发表一下你的评论吧 !
