

在FPGA设计中如何充分利用NoC资源去支撑创新应用设计
可编程逻辑
描述
一个运用NoC访问片外GDDR6的例子
作者:黄仑,Achronix资深现场应用工程师
日益增长的数据加速需求对硬件平台提出了越来越高的要求,FPGA作为一种可编程可定制化的高性能硬件发挥着越来越重要的作用。近年来,高端FPGA芯片采用了越来越多的Hard IP去提升FPGA外围的数据传输带宽以及存储器带宽。但是在FPGA内部,可编程逻辑部分随着工艺提升而不断进步的同时,内外部数据交换性能的提升并没有那么明显,所以FPGA内部数据的交换越来越成为数据传输的瓶颈。
为了解决这一问题,Achronix 在其最新基于台积电(TSMC)7nm FinFET工艺的Speedster7t FPGA器件中包含了革命性的创新型二维片上网络(2D NoC)。这种2D NoC如同在FPGA可编程逻辑结构之上运行的高速公路网络一样,为FPGA外部高速接口和内部可编程逻辑的数据传输提供了大约高达27Tbps的超高带宽。
作为Speedster7t FPGA器件中的重要创新之一,2D NoC为FPGA设计提供了几项重要优势,包括:
- 提高设计的性能,让FPGA内部的数据传输不再成为瓶颈。
- 节省FPGA可编程逻辑资源,简化逻辑设计,由NoC去替代传统的逻辑去做高速数据传输和数据总线管理。
- 增加了FPGA的布线资源,对于资源占用很高的设计有效地降低布局布线拥塞的风险。
- 实现真正的模块化设计,减小FPGA设计人员调试的工作量。
本文用了一个具体的FPGA设计案例,来体现上面提到的NoC在FPGA设计中的几项重要作用。这个设计的主要目的是展示FPGA内部的逻辑如何去访问片外的存储器。如图1所示,本设计包含8个读写模块,这8个读写模块需要访问8个GDDR6通道,这样就需要一个8x8的AXI interconnect模块,同时需要有跨时钟域的逻辑去将每个GDDR6用户接口时钟转换到逻辑主时钟。除了图1中的8个读写模块外,红色区域的逻辑都需要用FPGA的可编程逻辑去实现。
图1 传统FPGA实现架构
对于AXI interconnect模块,我们采用Github上开源的AXI4总线连接器来实现,这个AXI4总线连接器将4个AXI4总线主设备连接到8个AXI4总线从设备,源代码可以在参考文献2的链接中下载。我们在这个代码的基础上进行扩展,增加到8个AXI4总线主设备连接到8个AXI4总线从设备,同时加上了跨时钟域逻辑。
为了进行对比,我们用另外一个设计,目的还是用这8个读写模块去访问8个GDDR6通道;不同的是,这次我们将8个读写模块连接到Achronix的Speedster7t FPGA器件的2D NoC上,然后通过2D NoC去访问8个GDDR6通道。如图2所示:
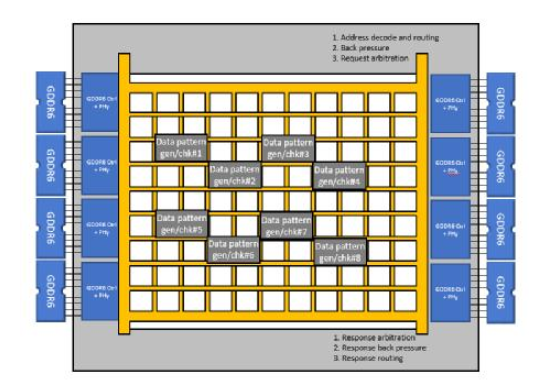
图2 Speedster7t 1500的实现架构
首先,我们从资源和性能上做一个对比,如图3所示:
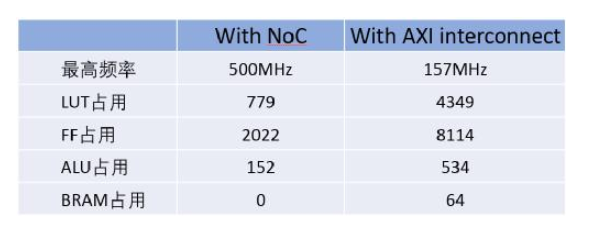
图3 资源占用和性能对比
从资源占用上看,用AXI总线连接器的设计会比用2D NoC的设计占用多出很多的资源,以实现AXI interconnect还有跨时钟域的逻辑。这里还要说明一点,这个开源的AXI interconnect实现的是一种最简单的总线连接器,并不支持2D NoC所能提供的所有功能,比如地址表映射,优先级配置。
最重要的一点是AXI interconnect只支持阻塞访问(blocking),不支持非阻塞访问(non-blocking)。阻塞访问是指发起读或者写请求以后,要等到本次读或者写操作完成以后,才能发起下一次的读或者写请求。而非阻塞访问是指可以连续发起读或者写请求,而不用等待上次的读或者写操作完成。在提高GDDR6的访问效率上面,阻塞访问会让读写效率大大下降。
如果用FPGA的可编程逻辑去实现完整的2D NoC功能,包括64个接入点、128bit位宽和400MHz的速率,大概需要850 k LE,等效于占用了Speedster7t 1500 FPGA器件56%的可编程资源。而2D NoC则可以提供 80个接入点、256bit位宽和2GHz速率,而且不占用FPGA可编程逻辑。
从性能上来看,使用AXI总线连接器的设计只能跑到157MHz,而使用NoC的设计则能跑到500MHz。如果我们看一下设计后端的布局布线图,就会有更深刻的认识。图4所示的是使用AXI总线连接器的设计后端布局布线图。
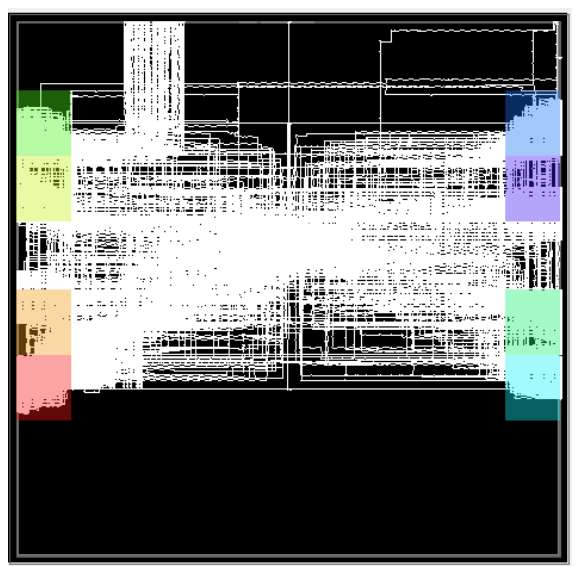
图4 使用AXI interconnect的设计后端布局布线图
从图中可以看到,因为GDDR6控制器分布在器件的两侧(图中彩色高亮的部分),所以AXI总线连接器的布局基本分布在器件的中间,既不能靠近左边,也不能靠近右边,所以这样就导致了性能上不去。如果增加pipeline的寄存器可以提高系统的性能,但是这样会占用大量的寄存器资源,同时会给GDDR的访问带来很大的延时。
如果再看一下图5中使用了2D NoC的布局布线图,就会有很明显的对比。首先,因为用2D NoC实现了AXI总线连接器和跨时钟域的模块,这就节省了大量的资源;另外,因为2D NoC遍布在整个器件上,一共有80个接入点,所以8个读写模块可以由工具放置在器件的任何地方,而不影响设计的性能。
图5 使用2D NoC设计的后端布局布线图
从本设计的整个流程来看,使用2D NoC会极大的简化设计,提高性能,同时节省大量的资源;FPGA设计工程师可以花更多的精力在核心模块或者算法模块设计上面,把总线传输、外部接口访问仲裁和接口异步时钟域的转换等工作全部交给2D NoC吧。
-
FPGA中如何充分利用DSP资源,DSP48E1内部详细资源介绍2020-09-30 33120
-
让你的内存每秒都能充分利用:内存释放专家2009-06-01 5848
-
如何充分利用光纤配线箱?2016-09-13 2825
-
如何充分利用这些频谱资源2019-07-11 2442
-
在XC7K325T FPGA中如何充分利用GTX资源?2020-07-22 3685
-
利用NoC资源解决FPGA内部数据交换的瓶颈2020-09-07 2865
-
如何利用NoC资源去支撑FPGA中的创新设计2020-10-20 1727
-
开关电源转换器中如何充分利用SiC器件的性能优势?2021-02-22 1683
-
如何充分利用电子设计工具呢2021-12-31 1410
-
并行编程无进展使多核芯片未能充分利用2010-04-01 1084
-
充分利用超级大写电脑2021-05-21 721
-
IGBT厂商扩产,APS生产排产帮助企业充分利用设备产能2022-11-03 1524
-
充分利用电位计 — 别让旋转乱套!2022-11-07 887
-
在FPGA设计中如何充分利用NoC资源去支撑创新应用设计2023-04-18 1135
-
在MCU开发中如何充分利用各种类型的断点?2023-09-18 1610
全部0条评论

快来发表一下你的评论吧 !
