

机器学习的方法及应用领域
人工智能
描述
机器学习(machinelearning)是一门多领域交叉学科,涉及了概率论、统计学、算法复杂度等多门学科。专门研究计算机怎样模拟或实现人的学习行为,它能够发现和挖掘数据所包含的潜在价值。机器学习已经成为了人工智能的一个分支,通过自学习算法,发现和挖掘数据潜在的规律,从而对未知的数据进行预测。机器学习已经广泛的运用在了,计算机科学研究、自然语言处理、机器视觉、语音、游戏等。机器学习的方法主要分为三种,监督学习(supervisedlearging)、无监督学习(unsupervisedlearning)、强化学习(reinforcementlearning),下面将介绍这三种方法的本质区别以及它们的应用领域。
一、监督学习
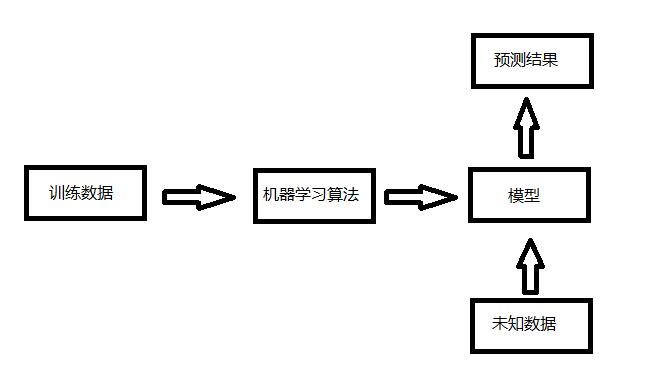
训练过程
上图展示了监督学习训练模型的过程,在监督学习中的训练数据是带类标的。监督学习通过使用有类标的训练数据构建模型,我们可以通过训练得到的模型对未知的数据进行预测。比如,在对手写数字识别所使用的机器学习算法就属于监督学习,在训练模型之前,我们需要先定义那张图片表示的是数字几,以便计算机从数据中提取特征更好的像类标靠近。监督学习可以被分为分类和回归,像上面手写数字的识别就属于监督学习中的分类,像房间的预测就属于回归。
1、分类
分类是基于对于已知数据(带类标)的学习,实现对新样本类标的预测。类标是离散的、无序的值。像对于垃圾邮件的分类就属于二分类,其中五角星表示非垃圾邮件而原表示垃圾邮件,而我们所需要训练的模型就是图中的直线,能够将垃圾邮件和分垃圾邮件进行区分。我们可以将横轴和纵轴理解为对于区分邮件的两个特征,可以发现这些数据都是离散的。上面所提到的手写数字的识别属于多分类。
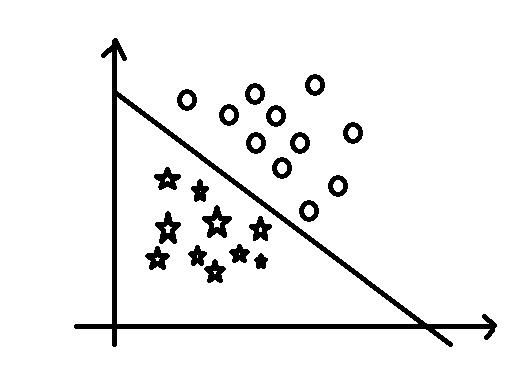
分类
2、回归
回归是针对连续型输出变量进行预测,我们通过从大量的数据中寻找自变量(输入)和相应连续的因变量(输出)之间的关系,通过学习这种关系来对未知的数据进行预测。如下图,通过自变量和因变量来拟合一条直线,使得训练数据与拟合直线之间的距离最短,最常用的距离是采用平均平方距离。通过对训练数据的分析我们可以获取到这条直线的斜率和截距,从而可以对于未知数据进行预测。
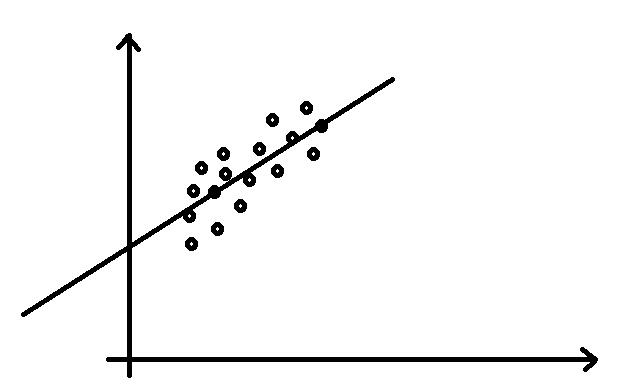
回归
二、强化学习
强化学习是通过构建一个系统(agent),在与环境(environment)交互的过程中提高系统的性能。环境的当前状态信息会包括一个反馈信号,我们可以通过这个反馈信号对当前的系统进行评价改善系统。通过与环境的交互,agent可以通过强化学习来得到一系列行为,通过对激励系统的设计使得正向反馈最大。强化学习经常被使用在游戏领域,比如围棋比赛,系统会根据当前棋盘上的局态来决定下一步的位置,通过游戏结束时的胜负来作为激励信号。
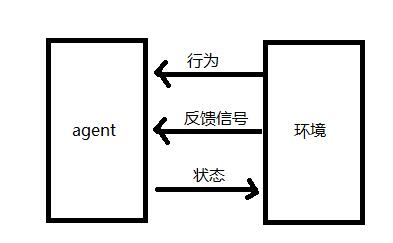
强化学习
三、无监督学习
无监督学习所处理的是无类标或者数据的总体趋势不明朗,通过无监督学习我们可以将这些不知道类标和输出标量以及没有反馈信号的情况下,来寻找数据中所潜在的规律。无监督学习可以分为聚类和降维。
1、聚类
聚类属于一种探索性的数据分析技术,在没有任何已知信息(类标、输出变量、反馈信号)的情况下,我们可以将数据划分为簇。在分析数据的时候,所划分的每一个簇中的数据都有一定的相似度,而不同簇之间具有较大的区别。
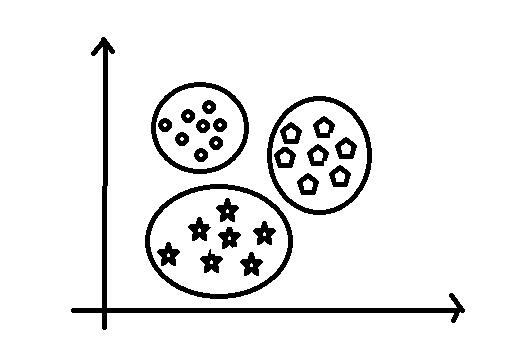
聚类
2、降维
在实际情况中所处理的数据都是高维的(成百上千),那么这将会导致我们每次所处理的数据量是非常的庞大,而存储空间通常都是有限的。无监督的降维技术经常被使用在数据特征的预处理中,通过降维技术我们可以去掉数据中的噪声,以及不同维度中所存在的相似特征,最大程度上在保留数据的重要信息情况下将数据压缩到一个低维的空间中,但同时也还是会降低算法的准确性。
- 相关推荐
- 热点推荐
- �
-
【下载】《机器学习》+《机器学习实战》2017-06-01 199245
-
人工智能的应用领域有哪些?2020-10-23 5159
-
FPGA学习--FPGA应用领域2020-10-26 2285
-
深圳CCD视觉对位系统有什么功能及应用领域?2021-10-29 1241
-
描述嵌入式Linux的应用领域2021-11-05 1366
-
什么是机器学习? 机器学习基础入门2022-06-21 3077
-
深度解析机器学习三类学习方法2018-05-07 15264
-
如何开始接触机器学习_机器学习入门方法盘点2018-05-20 4790
-
《机器学习与数据挖掘:方法和应用》2018-06-27 997
-
机器学习为生物信息学开辟了有希望的新应用领域2020-09-10 3344
-
机器视觉在工业上的应用领域2020-10-09 6677
-
机器人的应用领域及主要分类2021-10-02 45861
-
激光焊接机器人的应用领域介绍2021-10-11 2892
-
MFM推拉力测试机的应用领域和使用方法2023-11-22 1345
-
传统机器学习方法和应用指导2024-12-30 2562
全部0条评论

快来发表一下你的评论吧 !
