

阿里达摩院斩获AI相关6大权威冠军,部分能力已超越人类
电子说
描述
让AI模仿人类的学习方式,结果会怎样?
8月26日,阿里达摩院语言技术实验室取得一系列突破,斩获自然语言处理(NLP)领域6大权威技术榜单冠军。据介绍,参与竞赛的6项自研AI技术均采用模仿人类的学习模式,全方位提升了机器的语言理解能力,部分能力甚至已超越人类。目前,这些技术均已大规模应用于阅读理解、机器翻译、人机交互等场景。
据悉,过去几年,AI在图像识别、语音识别等方面已逐步超越人类水平,但在复杂文本语义的理解上,AI与人类尚有差距,其主要原因就是传统AI学习文本知识效率较低。
为此,业界提出了一种模仿人类的学习思路,即先让AI在大规模的网页和书籍文字中进行训练,学习基本的词法、语法和语义知识,然后再在固定领域内的文本上进行训练,学习领域专有知识。
这一思想就是预训练语言模型的核心创新。自Google提出模仿人类注意力机制的BERT模型以来,预训练语言模型已成为NLP领域的热点研究方向。
达摩院早在2018年就开始布局通用的预训练语言模型,并逐渐将该思路拓展到了多语言、多模态、结构化和篇章文本理解和文本生成领域,如今已建立一套系统化的深度语言模型体系,其自研通用语言模型StructBERT、多语言模型VECO、多模态语言模型StructVBERT、生成式语言模型PALM等6大自研模型分别刷新了世界纪录。
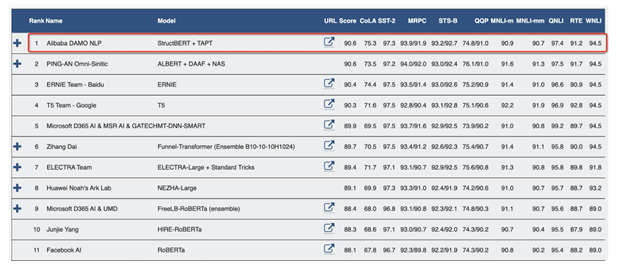
达摩院自研模型位居GLUE榜单第一名
其中,StructBERT能让机器更好地掌握人类语法,使机器在面对语序错乱或不符合语法习惯的词句时,仍能准确理解并给出正确的表达和回应,大大提高机器对词语、句子以及语言整体的理解力。该模型以平均分90.6分在自然语言处理领域权威数据集GLUE Benchmark中位居第一,显著超越人类水平(87.1分)。
达摩院语言技术实验室团队表示:“实验室的目标是让AI掌握人类知识的基础技术,预训练语言模型的诞生使得AI像人一样学习新知识成为可能,未来达摩院会全面对外开放这些技术,让特定领域的AI变得更加智能。”
过去两年,阿里获得了30多项NLP领域顶级赛事世界冠军,有100多篇相关顶会论文; 阿里自然语言技术已在金融、新零售、通讯、互联网、医疗、电力、客服等领域服务超十亿用户和数万企业客户。
-
认识一下阿里的AI殿堂-达摩院 精选资料分享2021-07-28 2217
-
阿里要建“达摩院”,马云、胡晓明、张建峰他们这样说2017-10-12 3013
-
达摩院AI领域开门红,微软谷歌专家纷纷入职阿里2017-10-17 1181
-
阿里巴巴达摩院自研AI芯片 助推中国芯2018-04-23 4574
-
阿里巴巴达摩院与公路院签署战略合作协议2018-09-12 4954
-
阿里达摩院发布2019十大科技趋势2019-01-03 3832
-
阿里达摩院首份科技趋势报告出炉:2019年十大科技趋势预测2019-02-07 3642
-
刚刚!贾扬清加入阿里!达摩院或将承载中国下一个AI愿景?2019-03-04 5458
-
阿里90后科学家研发,达摩院开源新一代AI算法模型2019-07-06 4204
-
阿里达摩院2020十大科技趋势发布 芯片设计将像搭积木一样快速2020-01-02 3584
-
阿里巴巴达摩院发布白皮书,AI将有大突破2020-02-12 5744
-
阿里达摩院发布首个泛自然资源行业AI引擎,实现对多源数据精准分析2020-09-19 2785
-
阿里达摩院都在研究什么2022-03-30 3983
-
阿里达摩院量子实验室裁撤 整体捐献给浙江大学2023-11-28 1497
-
阿里最新消息 阿里达摩院发布新型CPU 阿里国际在海外落地首个企业级Agent2026-03-24 3489
全部0条评论

快来发表一下你的评论吧 !
