

2020年常见的20种数据科学工具,你了解多少
描述
概述
数据科学的工具数不胜数——你应该选择哪一个?
这里列出了超过20种的数据科学工具,满足数据科学生命周期不同阶段的需求。
引言
执行数据科学任务的最佳工具有哪些?作为数据科学新手,你应该选择哪些工具? 我相信在你的数据科学之旅的某些时刻中你已经问过(或搜索过)这些问题。这些问题是合理的!虽然在这个行业中并不缺乏数据科学工具,但是为你的数据科学旅程和生涯做出一个选择可能是一个棘手的决定。
我们得承认——数据科学的范围庞杂,每一个领域要求处理数据的方式各有不同,这让许多分析家/数据库科学家陷入困惑。而如果你是一位商业领袖,你将要选择你和你的公司所使用的工具,这很关键,因为这些工具会产生长期的影响。 同样地,问题是你应该选择哪种数据科学工具呢? 在本文中,我将通过罗列出数据科学领域广泛使用的工具并细分它们的用途和优势,来帮你解决这些困惑。所以,让我们开始吧!
处理大数据体量的工具
顾名思义,体量是指数据的规模和数量。要了解我在说的数据规模,你需要知道,世界上超过90%的数据是在最近两年内创建的! 十年来,随着数据量的增加,该技术也变得越来越好。计算和存储成本的降低使收集和存储大量数据变得更加容易。 数据体量定义了它是否符合大数据的条件。 当我们的数据范围在1Gb到10Gb左右时,传统的数据科学工具就可以很好地工作。那么这些工具有哪些呢?
Microsoft Excel–Excel是处理少量数据的最简单,最受欢迎的工具。它支持的最大行数只刚刚超过一百万,一张表一次最多只能处理16,380列。当数据量很大时,这些根本不够用。
Microsoft Excel:
https://www.analyticsvidhya.com/blog/category/excel/?utm_source=blog&utm_medium=22-tools-data-science-machine-learning
Microsoft Access –它是Microsoft流行的用于数据存储的工具。使用此工具可以平稳顺畅地处理高达2Gb的较小数据库,但超过这个数字,Access会开始崩溃。
SQL – SQL是自1970年代以来最流行的数据管理系统之一。几十年来,它一直是主要的数据库解决方案。SQL仍然很流行,但有一个缺点——随着数据库的不断增长,很难对其进行扩展。
到目前为止我们已经介绍了一些基本工具。现在该放大招了!如果你的数据大于10Gb,甚至超过1Tb+,那么需要使用我在下面提到的工具:
Hadoop –它是一个开源的分布式框架,用于管理大数据的数据处理和存储。当你从零开始构建机器学习项目时,很可能会使用此工具。
Hive –它是建立在Hadoop之上的数据仓库。Hive提供了一个类似于SQL的接口来查询存储在与Hadoop集成的各种数据库和文件系统中的数据。
处理大数据种类的工具
数据种类是指存在的不同类型的数据。数据类型可以是以下之一:结构化和非结构化数据。 让我们看一下不同数据类型的示例:
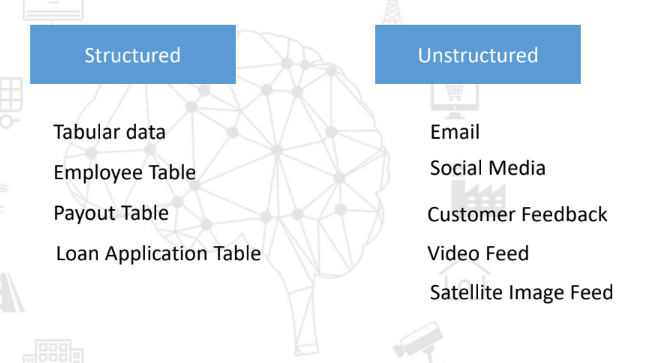
花一点时间去观察这些示例,并且将它们与你的真实数据关联起来。 你可能在结构化数据中观察到,这种类型的数据有固定的顺序和结构,而非结构化数据相反,这些示例并不遵循任何趋势或者模式。例如,顾客反馈在长度、情感和其他方面有所不同。另外,这类数据巨大并且种类繁多。 处理这类数据可能非常具有挑战性,那么市场上用于管理和处理这些不同数据类型的数据科学工具有哪些呢? 两个最常见的数据库是SQL和NoSQL。在NoSQL出现前,SQL多年来一直是市场主导者。
SQL的一些例子是Oracle,MySQL,SQLite,而NoSQL由诸如MongoDB,Cassandra等流行的数据库组成。这些NoSQL数据库由于具有扩展和处理动态数据的能力而被广泛地应用。
处理大数据速度的工具
第三个,也是最后一个V代表了速度。这是捕获数据时的速度,包括实时和非实时数据。我们在这里将主要讨论实时数据。 我们周围有许多捕获和处理实时数据的示例。最复杂的是自动驾驶汽车收集的传感器数据。想象一下,在自动驾驶汽车中,汽车必须同时动态地收集和处理有关车道、与其他车辆的距离等数据! 其他正在收集的实时数据的例子包括:
闭路电视
股票交易
信用卡交易欺诈检测
网络数据——社交媒体(Facebook、Twitter等)
“你知道吗? 在纽约证券交易所的每个交易时段中,都会生成超过1TB的数据!” 现在,让我们来看看处理实时数据的一些常用数据科学工具:
Apache Kafka – Kafka是Apache的开源工具。它用于创建实时数据管道。Kafka的一些优点在于——它具有容错性、速度很快,并且被大量机构投入生产使用。
Apache Storm – Apache的该工具几乎可用于所有编程语言。它每秒可处理多达100万个元组,并具有高度的可扩展性。对于高数据速率来说,这是个好工具。
Amazon Kinesis – 亚马逊提供的此工具类似于Kafka,但需要付费。然而,它提供的是开箱即用的解决方案,这使其成为组织机构的强势的备选方案。
Apache Flink – Flink是Apache另一种可用于实时数据的工具。Flink的优点在于它的高性能、容错能力和有效的内存管理。
现在,我们已经掌握了通常用于处理大数据的各种工具,接下来将介绍使用高级机器学习技术和算法来利用数据的部分。
广泛使用的数据科学工具
如果你要建立一个全新的数据科学项目,那么脑海中会浮现很多问题,这与你的水平无关——无论你是数据科学家,数据分析师,项目经理还是高级数据科学主管,都是如此。 你将面对的一些问题是: • 在数据科学的不同领域中应该使用哪些工具? • 应该购买这些工具的许可证还是选择开源工具?等等。 在本节中,我们将根据不同领域讨论行业中使用的一些受欢迎的数据科学工具。 数据科学本身就是一个广义术语,它由各种不同的领域组成,每个领域都有它自己的业务重要性和复杂性,正如下图所示:
数据科学的范围包含了各种领域,上图表示了这些领域的相对复杂性和它们提供的业务价值。让我们讨论一下以上频谱中显示的每一个点。
报告和商业智能
让我们从这个范围的底端开始。报告和商业智能使一个机构能够识别出数据的趋势和模式,从而制定关键的战略决策。这种分析的类型包括MIS、数据分析和仪表板。 这些领域中常用的工具有:
Excel – 它提供了多种选择,包括了数据透视表和图表,使你可以快速分析数据。简而言之,它是数据科学/分析工具中的“瑞士军刀”。
QlikView – 您只需单击几下即可合并,搜索,可视化和分析所有数据资源。这是一种易于学习的直观的工具,因此非常受欢迎。
Tableau – 它是当今市场上最受欢迎的数据可视化工具之一。它能够处理大量数据,甚至提供类似于Excel的计算功能和参数。Tableau因其整洁的仪表板和故事界面而倍受赞誉.
https://courses.analyticsvidhya.com/courses/tableau-2-0?utm_source=blog&utm_medium=22-tools-data-science-machine-learning
Microstrategy – 它是另一个BI工具,支持仪表板、自动分发和其他关键数据分析任务。
PowerBI – 它是商业智能(BI)领域中的Microsoft产品。PowerBI旨在与Microsoft技术进行集成。因此,如果你的组织有Sharepoint或SQL数据库用户,那么你和你的团队将会喜欢这个工具。
Google Analytics – 想知道Google Analytics如何进入此名单的吗?嗯……数字营销在业务转型中起着重要作用,没有比它更好的工具可以用来分析你的数字化工作。
预测分析和机器学习工具
顺着前面那个图再往上走,其复杂性和商业价值也变高了!这是大多数数据科学家赖以生存的领域。你将要解决的问题类型是统计建模,预测,神经网络和深度学习。 让我们了解一些该领域的常用工具:
Python – 由于其易用性,灵活性和开源特性,Python是当今行业数据科学中最主要的语言之一。它已经在ML社区中迅速普及并被广泛接受。
https://courses.analyticsvidhya.com/courses/introduction-to-data-science?utm_source=blog&utm_medium=22-tools-data-science-machine-learning
R – 它是数据科学中另一种非常常用且受人尊敬的语言。R有一个蓬勃发展且被极大支持的社区,附带了许多软件包和库,支持大多数的机器学习任务。
Apache Spark – Spark由加州大学伯克利分校于2010年开源,此后已成为最大的大数据社区之一。它被称为大数据分析的“瑞士军刀”,因为它具有多种优势,例如灵活性、速度、计算能力等。
Julia – 它是一种即将到来的语言,被捧为Python的继承者。目前它仍处于起步阶段,观察其在未来的表现将会是一件有趣的事。
Jupyter Notebooks – 这些笔记本广泛用于Python编程。尽管它主要用于Python,但它也支持其他语言,例如Julia,R等。
到目前为止,我们讨论的工具都是真正的开源工具。你无需支付费用或购买任何额外的许可证。它们拥有活跃的社区,可以定期维护和发布更新。 现在,我们将看一些在某些特定行业中通用的收费工具:
SAS – 这是一个非常受欢迎且功能强大的工具。在银行和金融部门中被普遍使用。它的使用在美国运通,摩根大通,西格玛,苏格兰皇家银行等私人组织中占有很高的份额。
SPSS – SPSS是“社会科学统计软件包”的缩写,在2009年被IBM收购。它提供高级统计分析、庞大的机器学习算法库、文本分析等。
Matlab – Matlab在组织机构的领域里确实被低估了,但在学术界和研究部门中得到了广泛的使用。最近相较于Python,R和SAS,Matlab已经阵地失守,但是大学(尤其在美国)仍在使用Matlab教授许多本科课程。
深度学习的通用框架
深度学习需要大量的计算资源,并且需要特殊的框架才能有效地利用这些资源。因此,你很可能需要GPU或TPU。 让我们看看本节中用于深度学习的一些框架。
TensorFlow – 它很容易成为当今行业中使用最广泛的工具。Google可能与此有关!
PyTorch – 这种超级灵活的深度学习框架正在成为TensorFlow的强势竞争对手。PyTorch最近受到一些关注,它的开发者是Facebook的研究人员。
Keras和Caffe是广泛用于构建深度学习应用程序的其他框架。
人工智能工具
AutoML的时代就在这里。如果还没有听说过这些工具,那么这是一个自我学习的好机会!作为数据科学家,你很可能会在不久的将来与他们合作。
列举一些最受欢迎的AutoML工具,包括AutoKeras,Google Cloud AutoML,IBM Watson,DataRobot,H20的无人驾驶AI和亚马逊的Lex。AutoML有望成为AI / ML社区中的下一个大事件。它旨在消除或减少技术性,以便商业领导者可以使用它来制定战略决策。 这些工具将推动整个数据分析流程自动化!
尾注
我们已经讨论了数据收集引擎以及完成检索、处理和存储,这一整个流水线所需的工具。数据科学的众多领域中每个领域都有自己的一套工具和框架。 选择数据科学工具通常取决于你的个人选择、你的领域或项目,当然也取决于你的机构。 在评论中让我知道你喜欢使用的最喜欢的数据科学工具或框架!
-
20张图让你理解各种数学概念2018-10-10 2252
-
这几种常见的薄膜电阻器你都了解吗?2021-06-07 1936
-
2020年中国科技核心期刊目录自然科学卷2021-07-16 2607
-
MIT Technology Review 2020年“十大突破性技术”解读 【中国科学基金】2020年第3期发布 精选资料分享2021-07-26 1872
-
ModBus四种数据DI/DO/AI/AO是什么?2021-11-02 6224
-
2010年世界十大最差电子科学工作2010-04-15 2941
-
一种用于形状精确描述的数学工具2017-12-25 929
-
十大机器学习工具及数据科学工具2018-05-29 4352
-
2018年数据科学和机器学习工具调查2018-06-07 5287
-
2020年数据科学领域的四种发展趋势2020-02-18 5640
-
数据科学的工具数不胜数——你应该选择哪一个?2020-08-27 2369
-
虹科分享 | 网络流量监控 | 你的数据能告诉你什么:解读网络可见性的4种数据类型2023-02-21 1362
-
常见的数据采集工具的介绍2024-07-01 2939
-
数据科学工作流原理2024-11-20 1201
全部0条评论

快来发表一下你的评论吧 !
