

近五年来中文电子病历的命名实体识别研究进展
描述
阅读综述性论文是一种能够快速了解某一领域的方法,接下来通过今年的一篇综述性论文来了解一下近五年来中文电子病历的命名实体识别研究进展。
基本的,我们应该先来了解一下两个概念:电子病历和命名实体识别。
电子病历(Electronic Medical Record,EMR)是指医务人员在医疗活动过程中,使用医疗机构信息系统生成的数字化信息, 并能实现存储、管理、传输和重现的医疗记录。电子病历中的文本内容是医务人员按照《病历书写基本规范》和《电子病历基本规范(试行)》中相关书写规定,围绕患者医疗需求与服务活动而记录的描述性文本内容。
命名实体识别(Named Entity Recognition,NER)是指识别自由文本中具有特定意义的实体,如人名、地名、专有名词等。与通用领域的命名实体不同,电子病历中的命名实体通常有疾病、症状、治疗等实体。
有了上述两个概念的了解后,接下来我们就可以来了解中文电子病历命名实体识别的任务,它包括:
①电子病历数据的获取与匿名化处理;
②明确命名实体种类,进行语料标注;
③构建模型进行实体识别;
④结果评价及优化。
以电子病历中现病史章节为例,中文电子病历命名实体识别研究任务流程如图1所示:
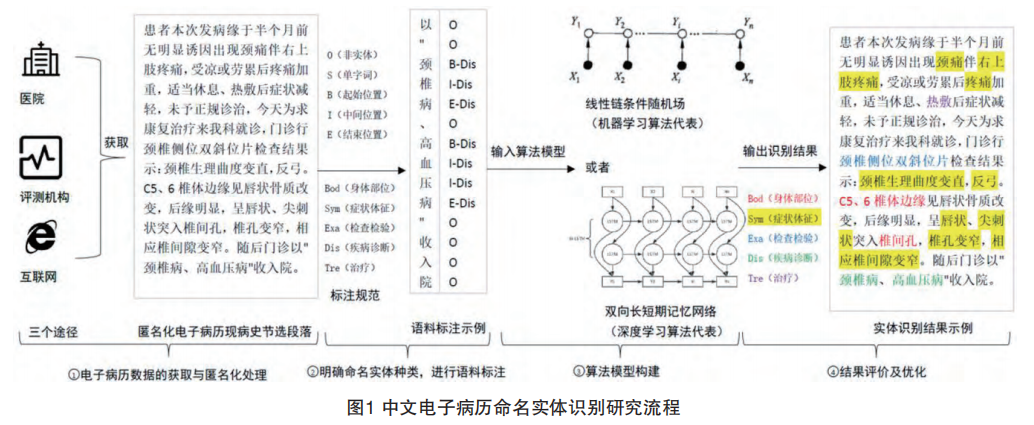
从上述四个任务出发,我们继续进行探讨。
1
电子病历数据集的获取
中文电子病历数据的获取途径通常包括:
①与医院建立合作关系,如曲春燕等通过与某医科大学附属医院建立合作关系获取到该院35个大科室、87个小科室的992份电子病历。同时,相关医务人员也全程参与数据标注,为数据集的质量提供了保障。
②开放获取的学术评测语料,如CCKS2020学术评测任务三开放了用于命名实体识别评测任务的已标注匿名化电子病历1500份和未标注的电子病历1000份,在电子病历语料资源匮乏的现状下,全国知识图谱与语义计算大 会无疑为行业发展作出了巨大贡献。 ③网络发布的电子病历资源。 当前,大多数研究采用第1种方式获取电子病历的研究数据,并邀请医务人员参与语料数据的标注工作;而第2、3种获取方式具有很大的不确定性,并且电子病历的数据标注工作过程控制和质量控制均存在不确定性。
2
数据标注的相关工作
曲春燕等参照i2b2 2010的标注规范制定了中文电子病历的标注规范,进而在两名临床医生的全程参与下,对病历文本分为前后共计4轮标注,并进行了一致性检验。杨锦锋等在曲春燕等人的工作基础上,对相同的病历文本资源,进行了命名实体和实体关系的标注语料构建工作。He等在曲春燕、杨锦锋等人的工作基础上,新增了电子病历文本的分词、词性标注、断言、关系抽取等自然语言处理常见任务的语料标注工作,并对标注结果进行了一致性检验。 上述学者的延续性标注工作,对今后研究的语料标注工作具有一定的指导意义。然而,与临床医生长期从事语料建设和维护的难以实现。一方面,临床医生用于语料标注的时间有限;另一方面,邀请临床医生标注语料成本更高。因此,医学数据标注团队建设和专业人员培养的可行性值得探讨。
3
主要的命名实体识别算法模型
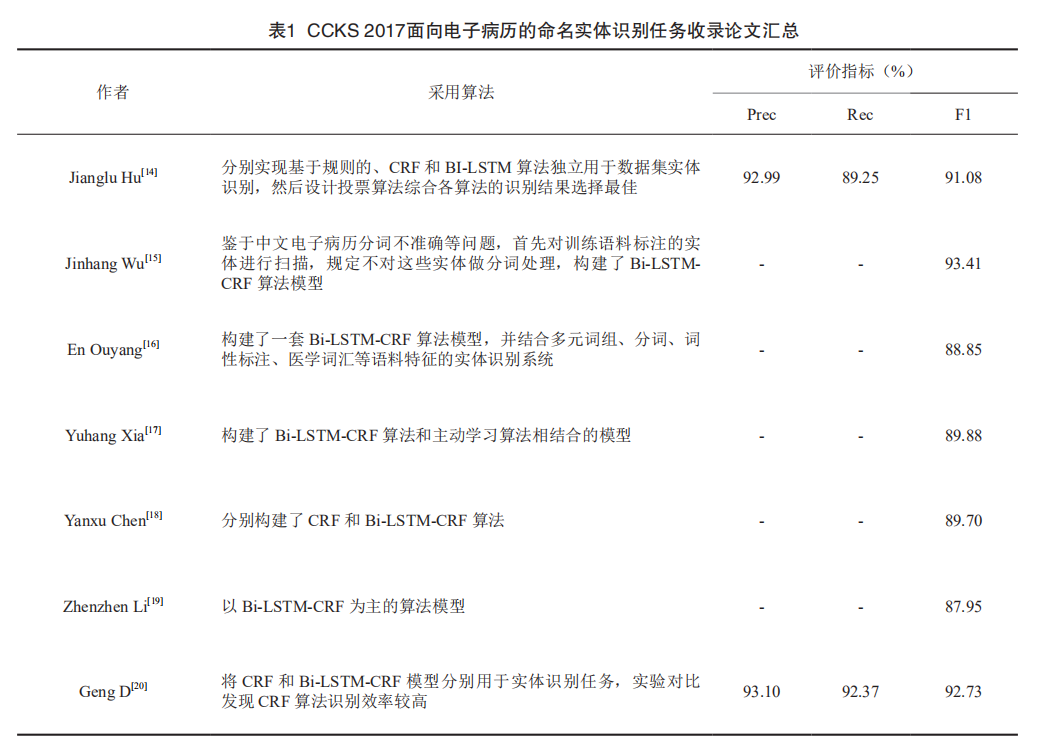
中文命名实体识别的主要研究算法为条件随机场(CRF)和双向长短期记忆网络模型条件随机场(Bi-LSTM-CRF)。 Liu等设计不同特征模板和上下文窗口进行条件随机场的学习训练,进行模型实体识别效率的比对分析,以寻找最佳的电子病历特征模板和上下文窗口。Liu等在i2b2 2010,2012和2014语料上实验对比了Bi-LSTM-CRF与传统的CRF实体识别算法的性能,结果表明Bi-LSTM-CRF性能较好。CCKS 2017学术评测任务二:面向电子病历的命名实体识别,共收录了7篇论文,研究内容和测评结果等见表1。总体上看,7篇论文均有对Bi-LSTM-CRF(或Bi-LSTM)算法模型的实现;均采用“字粒度”模型使用word2vec工具将输入文本特征向量化表示。Zhang等利用CCKS 2017开放的电子病历语料,分别采用CRFs和Bi-LSTM-CRF两种统计机器学习算法从电子病历数据集中识别疾病、身体部位和治疗等信息,并对两种方法进行了对比分析,发现后者性能较好。Qiu等为提高循环神经网络模型的训练速度,提出了残差卷积神经网络条件随机场模型(RD-CNN-CRF)在CCKS 2017开放测试语料上获得了较Bi-LSTM-CRF更高的训练速度和F1值。CCKS 2018学术评测任务一:面向中文电子病历的命名实体识别,共收录论文2篇,分别是Yang等将词嵌套、词性、偏旁部首、拼音、词典和规则特征作为条件随机场(CRFs)的学习特征,实验F1值为89.26%;Luo等基于多特征(如标点符号、分词和词典等特征)融合,整合CNN-CRF, Bi-LSTM-CRF, Bi-LSTM-CNN-CRF, Bi-LSTM+CNN-CRF和Lattice LSTM五种神经网络模型,实验F1值最高达到了88.63%(表1)。
4
结果评价及优化
随着中文电子病历命名实体识别的研究逐步深入以及相关算法框架的逐渐成熟,基于中文电子病历的命名实体识别算法构成了临床电子病历系统、专病科研数据提取、临床辅助决策系统的重要组成部分。 电子病历命名实体识别结果评价指标说明如下图:

袁冬生为解决出院小结文档中普遍存在的信息不准确、无效信息、信息缺失等问题,设计开发了一套基于命名实体识别的出院小结错误检测系统。李山为提高住院病历录入的交互性和可操作性,降低书写的繁杂度,减轻医生负荷,提高工作效率,使用条件随机场算法,进行电子病历命名实体识别,提取病历中重要的诊疗信息,并将其应用在住院病历录入辅助中,以优化和改善病历录入方式。Su等则基于中文电子病历命名实体标注规范构建了一个可用于识别心血管疾病危险因素的语料库。
展望
.....
针对电子病历的语义特征的量化分析与研究,对于提升算法特征工程质量有积极意义;近两年来,针对电子病历语料标注的成本问题,很多研究聚焦于半监督和无监督的算法来实现基于少量标注语料或完全基于非标注原始语料进行实体识别,是一个重要的研究方向。
-
什么是嵌套实体识别2022-09-30 3001
-
关于边界检测增强的中文命名实体识别2021-09-22 4208
-
基于神经网络的中文命名实体识别方法2021-06-03 905
-
基于字语言模型的中文命名实体识别系统2021-04-08 1002
-
一种中文电子病历医疗实体关系识别方法2021-04-02 1101
-
新型中文旅游文本命名实体识别设计方案2021-03-11 1362
-
思必驰中文命名实体识别任务助力AI落地应用2021-02-22 2911
-
深度学习:四种利用少量标注数据进行命名实体识别的方法2021-01-03 11867
-
HanLP-命名实体识别总结2019-07-31 2277
-
自然语言基础技术之命名实体识别相对全面的介绍2019-04-17 5815
-
基于结构化感知机的词性标注与命名实体识别框架2019-04-08 2111
-
HanLP分词命名实体提取详解2019-01-11 3560
-
基于神经网络结构在命名实体识别中应用的分析与总结2018-01-18 5383
-
薄膜锂电池的研究进展2011-03-11 3178
全部0条评论

快来发表一下你的评论吧 !
