

简单介绍ACL 2020中有关对象级情感分析的三篇文章
描述
引言
情感分析是文本分类的一种,主要方法是提取文本的表示特征,并基于这些特征进行分类。情感分析根据研究对象的粒度不同可分为文本级、句子级、对象级等,分别对相应单位的文本进行情感倾向分析。其中,较细粒度的情感分析为对象级情感分析(Aspect-level Sentiment Analysis, ASA),任务输入为一段文本和指定的待分析对象,输出为针对该对象的情感倾向。
对象级情感分析任务的难点在于,文本中表示情感判断的词汇与对应对象的关系是不确定的,分析工具需要挖掘语意特征和句法结构特征,正确提取制定对象的情感词汇,排除其他情感词汇的干扰;另一方面,情感分析在应用中要求工具能解释做出判断的依据,这对模型的可解释性提出了要求。
ACL 2020中有关情感分析的文章主要集中在Sentiment Analysis, Stylistic Analysis, and Argument Mining论坛中,内容涵盖了情感分析相关的数据构建、基本方法、上下游等任务。本文将简单介绍ACL 2020中有关对象级情感分析的三篇文章。
文章概览
基于文档级情感倾向的对象级情感分类模型(Aspect Sentiment Classification with Document-level Sentiment Preference Modeling)
论文地址:https://www.aclweb.org/anthology/2020.acl-main.338.pdf
本文构建了句子之间的相关网络,其他句子为所预测句子的情感分析任务提供了支持信息。这一方法的假设是短文本(如商品评价)中针对同一问题的情感表述较为一致,甚至整个文本的情感基调都较连贯,因此其他句子的信息可以提供有益的指导。
面向对象情感分析的对象导向型结构化注意力网络(Target-Guided Structured Attention Network for Target-Dependent Sentiment Analysis)
论文地址:https://www.mitpressjournals.org/doi/pdf/10.1162/tacl_a_00308
不同于以往将单词作为基本分析单元的研究,本文提出模型分析(如注意力机制)的基本单位应该是语义群(片段)而非单词,并基于这个想法构建了针对对象的语义群注意力机制。最终的结果也表明这样的方法尤其在复杂句子中能更准确地捕捉情感信息。
应用上下文及句法特征的对象级情感分类(Modelling Context and Syntactical Features for Aspect-based Sentiment Analysis)
论文地址:https://www.aclweb.org/anthology/2020.acl-main.293.pdf
本文指出,无论是从应用还是理论角度看,对象级情感分析都不应单独进行,而要与对象抽取任务结合起来进行。该文章构建了这样的一体化工具,能充分利用上下文和句法信息,有效地提升了对象级情感分类成绩。
论文细节
1

简介
来自苏州大学和阿里巴巴的几位研究者提出了参考文档级情感倾向信息的对象级情感分类方法。作者认为,之前的对象级情感分类工作都将其视为基于句子的独立任务,没有充分利用文本隐含的情感信息。而实际上,无论是微博等社交文本还是购物平台的评价文本,句子都不是单独出现,而是几句含义较为集中、情感较为一致的句子共同出现。另一方面,这些场合下句子构成往往较随意,有时句子本身无法提供足够的信息,必需参考其他句子的内容甚至情感倾向才能理解本句的情绪。
由此,本文提出了一种联合图注意力网络(Cooperative Graph Attention Network)方法,分别在对象内和跨对象两个层级收集情感信息(依次称为情感一致性和情感倾向性),并将这两种情感信息在图注意力网络上优化,在联合分析后得出针对对象的情感倾向。
模型

如上图所示,包含相同对象的不同句子之间可以互相参照,因文本对该对象的情感应具有一定的一致性。具体而言,本文构建了对象内一致性模型(Intra-Aspect Consistency Modeling),其中包含注意力网络,即句子Sentence与对象Aspect之间关联性的网络;对句子和对象, 注意力权重的计算公式如下:
于是句子的对象内(情感一致性)表示的计算公式为
.

类似地,如上图所示,本文还构建了跨对象倾向性模型(Inter-Aspect Tendency Modeling);其中注意力网络为,即句子与之间关联性,其注意力权重的计算公式如下:
跨对象(情感倾向性)表示的计算公式为:.
随后需要将两种表示合并:不同于直接将二者简单拼合,本文使用了一种融合机制,包括金字塔形隐藏层设计和适应性层融合技术,以此使两种表示之间存在沟通渠道。具体而言,金字塔隐藏层设计中,每一层向量的长度都比上一层缩小一倍,即,其中为当前层数;而适应性层融合技术是指将上述金字塔隐藏层的各层表示拼接起来,并经过线性变换和激活从而得到最终的句子表示向量。
模型的整体架构请见下图:
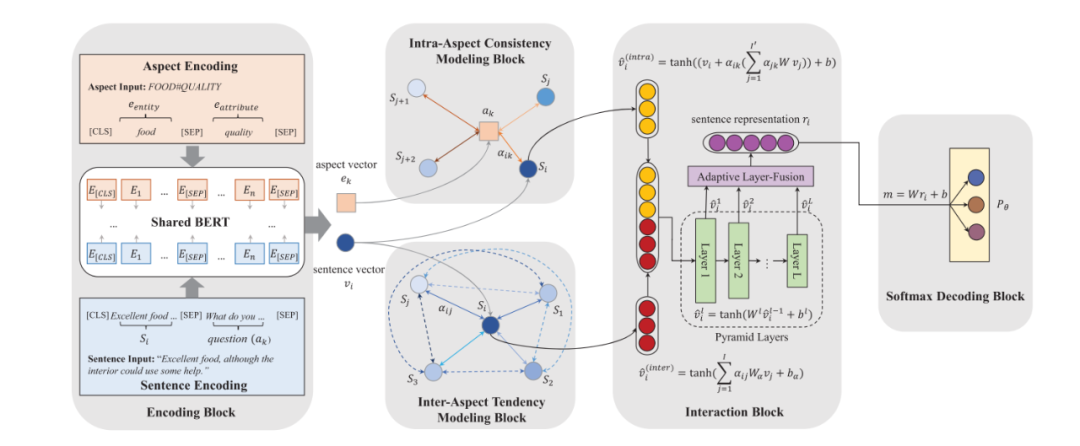
实验
在SemEval-2015 Task12和SemEval-2016 Task5的数据集上,本文所用的模型都得到了明显优于其他模型的结果。
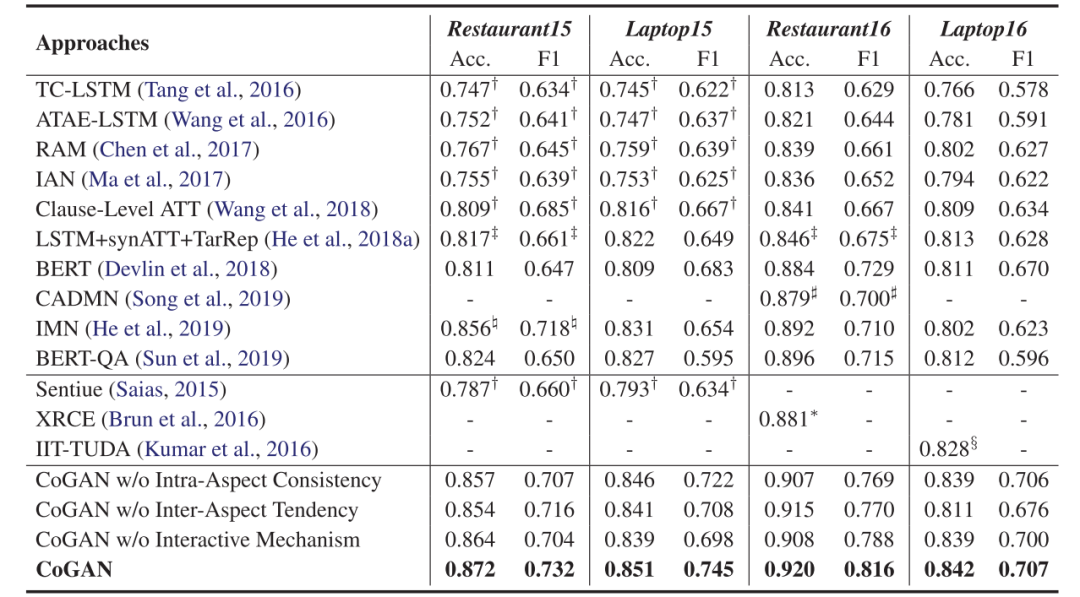
更重要的是,作者随后做了Case Study,在句内含义较为隐晦时,对象内情感一致性可以通过其他句子给出正确的判断;而在更为隐晦而难以判断的文本中,跨对象情感倾向性可以发挥作用,通过整体的情感判断给出某个对象的情感。
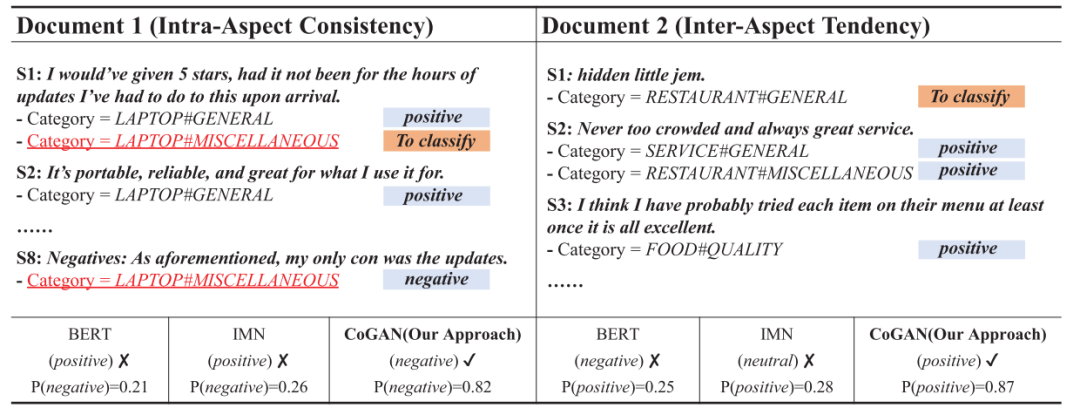
2

简介
来自Wisers AI Lab的几位研究者认为,对象级情感分类任务的重点在于挖掘对象词汇和上下文词汇的关系,而既有研究都将词汇看作单独的语意单元;本文作者提出,这样的假设忽略了句子其实是由若干语意区块构成的,在语意区块(片段)中几个单词联合表达一个含义,是不同语意片段(而非单词)在对对象产生着影响。如下图(a)所示,如果关注语义片段的作用,在预测“waiting”的情感倾向时,“so good and so popular”的重要性将整体低于“a nightmare”;但若以单词为分析单位,因为距离和词性不同,“popular”等词会获得比“nightmare”更多的注意力,因此得出相反(也是错误的)判断。因此本文试图挖掘句中表达特定含义的上下文片段,并将这些片段根据与对象的关系进行融合。

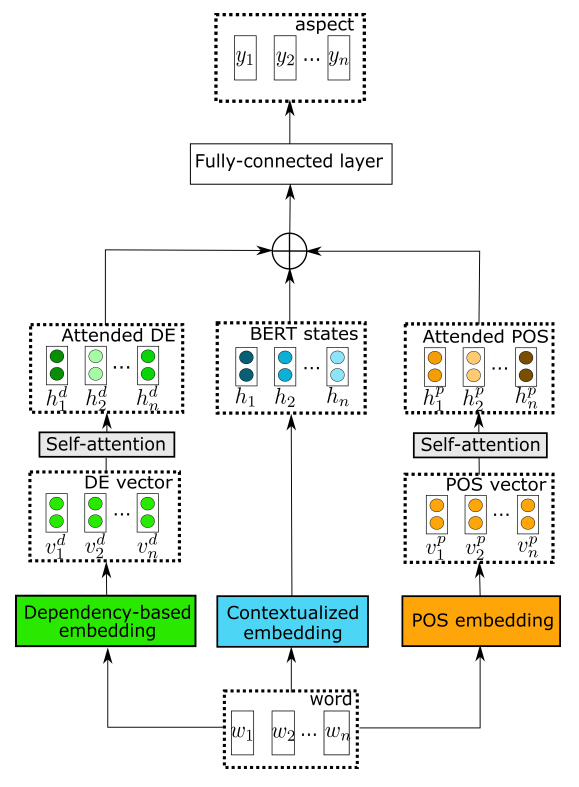
本文构建的模型为对象导向的结构性注意力网络(Target-Guided Structured Attention Network, TG-SAN),包括两个核心单元,其一是结构性上下文抽取单元(Structured Context Extraction Unit, SCU),其二是上下文融合单元(Context Fusion Unit, CFU),分别承担为语意群编码和将它们(根据与对象的关系)进行合并的任务。
模型
首先本文使用Bi_LSTM构建了对象和上下文的记忆力表示。随后,SCU模块的主要任务是根据给出的对象和上下文的记忆表示,抽取出对象相关的上下文片段。这分为三个步骤:第一,结构化对象表示,使用自注意力机制,将对象的记忆单元转为其表示,其公式为和. 其中,为权重矩阵,为对象的嵌入表示矩阵,和是两个用于自注意力机制的可学习参数矩阵。第二,对象导向的上下文提取,其公式为和. 其中,用来表示对象和上下文的相关程度;是上下文矩阵,其每一行可被视为基于对象的语义片段;是可学习的参数矩阵。最后,将上述表示进行变换从而得到结构化上下文表示:,. 其中两个和均为可学习的参数。
之后是上下文融合单元。该模块的目的是学习被抽取出的上下文关于对象的贡献度,使用的工具为自注意力机制。所用到的计算公式为:
本文模型的整体架构请见下图:
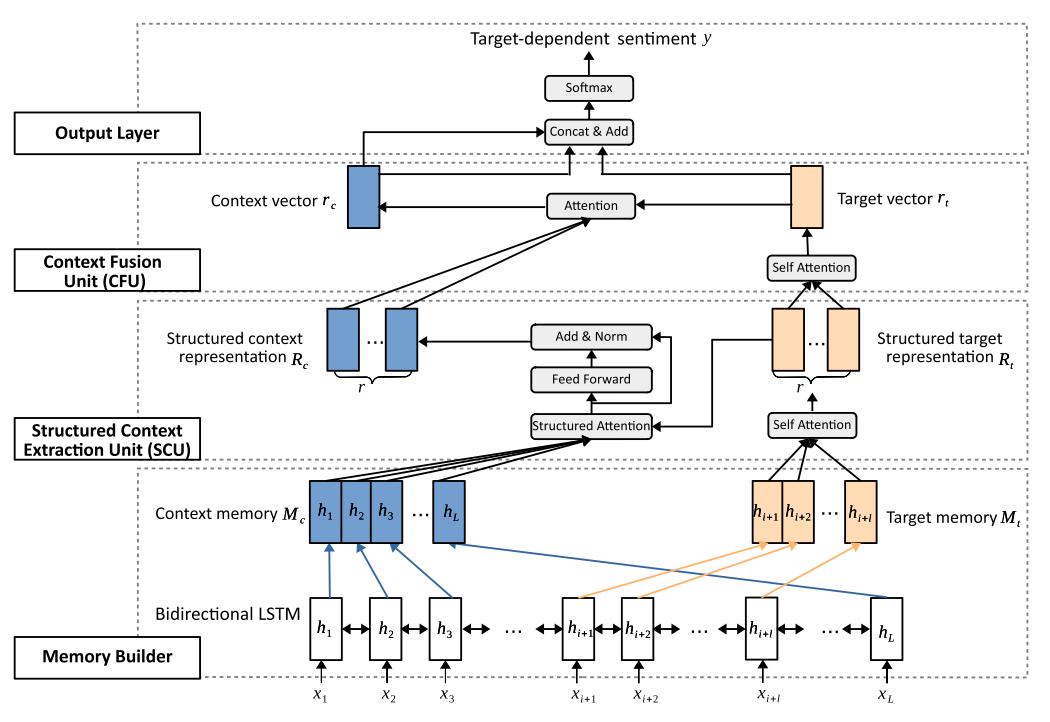
实验
在推特数据集和SemEval-2014的笔记本电脑、餐馆数据集上,本文的模型都取得了较好的成果,且销熔实验也证明两个核心模块都对实验结果有一定的提升。在Case Study部分,作者分别针对多对象、同对象多次出现、单对象的句子做了分析,发现本文的方法不但能比基线方法的判断正确率更高,且能准确定位到做出判断的词汇,权重分配较鲜明,证明该方法能学习到句中有关情感判断的知识。
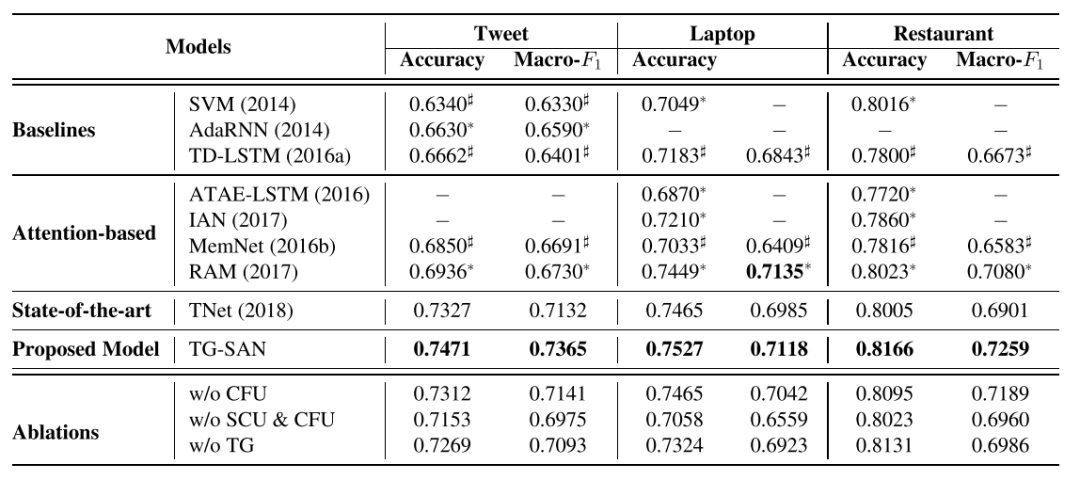
3

简介
来自伍伦贡大学的两位研究者提出,从流程上看,对象级情感分析任务(Aspect-based Sentiment Analysis,ABSA)其实包括两个部分,即对象抽取和情感分类;既有的研究大都将二者分离开,隐藏在句法结构中的信息就无法被充分利用。针对这个问题,本文构建了一种端到端的对象级情感分析方法,可以充分利用语法信息,并使用自注意力机制充分挖掘句法结构。在操作上,本文使用了part-of-speech表示、依存表示和上下文嵌入(如BERT,RoBERTa),还使用了句法距离来降低非相关单词的影响力。
在实际的应用任务(例如商品评价分析)中,文本中的对象并不是可使用数据,而需要研究者同时完成对象抽取(Aspect Extraction,AE)和细粒度的对象级情感分类(Aspect Sentiment Classification,ASC)任务。当前研究将二者分离开,这就丢失了很多上下文的句法信息,既不现实也不经济。而本文的方法将句法信息整合到上下文表示中,最终形成了包括对象抽取和情感分类的对象级情感分类工具(AE+ASC=ABSA)。
方法
本文的构建的方法包括两个核心单元,其一是对象抽取(AE),该单元的主要目标是标识句中每一个单词是否属于对象词汇。本文的对象抽取模块称为“基于句法的结构化对象抽取器”(contextualized syntax-based aspect extraction,CSAE),包含part-of-speech表示、依存表示和上下文嵌入(如BERT,RoBERTa),其中前两者还加入了自注意力机制。具体而言,POS标签来自Universal POS tags工具,之后有自注意力层负责抽取整个句子的语法依存关系。依存表示模块使用了基于句法关系的依存表示,首先要对每个目标词汇及其修饰词建立上下文集合,随后的依存关系学习可以延伸到距离较远的上下文,还能将不相关词汇(即使距离很近)的重要性降低。该单元的架构图如下所示:
另一个核心单元负责对象级情感分析(ASC),将挖掘局部上下文注意力的信息,负责将上文得到的上下文表示和对象术语转换为情感分类标签,具体思路是将相关性较小的信息的权重降低。该单元主要有两个组成部分,其一是局部上下文特征,通过将局部上下文向量送入上下文特征权重动态遮罩工具和动态调整工具,分别可以调整距离对象较远的词汇的权重(去除和降低):在特征权重动态遮罩工具中,若当前词的相对距离大于预设的阈值,重要性矩阵对应该词的一列为,否则该列为,即全0或全1向量;在特征权重动态调整工具中,若当前词的相对距离大于预设的阈值,重要性矩阵对应该词的一列为;否则,该列为。另一组成部分为全局上下文特征。该单元的架构图如下所示:
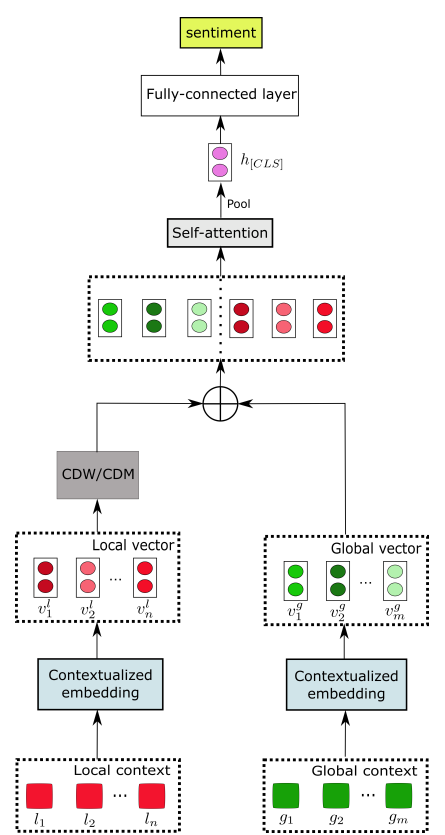
实验
在SemEval-2014 Task4数据集上,本文的方法取得了较好的结果,且销熔实验也证明各部分都有一定的增益。首先是对象抽取任务,作者比较了本文的模型和其他模型的表现,发现本文模型能取得最好或接近最好的成绩;之后又从单纯RoBERTa开始进行销熔实验,发现模型各组件都有一定的效果。具体结果请见下表:
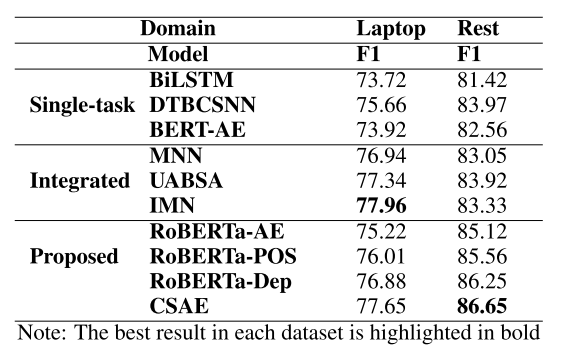
在对象级情感分类任务上,本文的方法均取得了最佳效果,且没有使用外部词库。结果证明本文的设想的确有足够的合理性。具体结果请见下表:
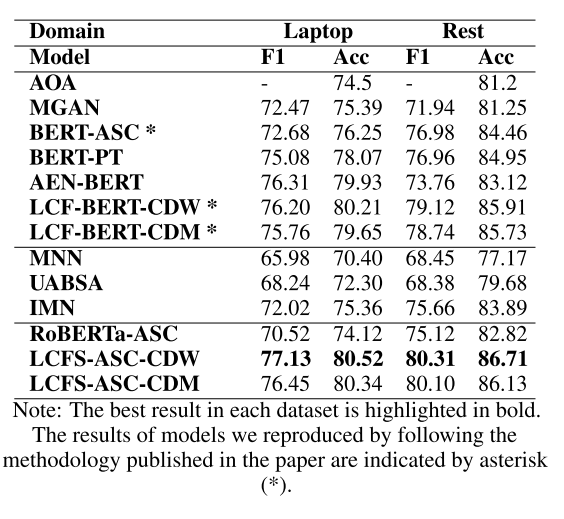
-
pyhanlp文本分类与情感分析2019-02-20 3290
-
LSTM的情感识别在鹅漫电商评论分析中的实践与应用2020-06-02 1441
-
面向对象编程介绍2021-12-13 2178
-
Protel中有关PCB工艺的条目简介2010-03-15 1280
-
双目标函数支持向量机在情感分析中的应用2017-01-03 814
-
基于CNN的图文融合媒体的情感分析方法2017-12-23 1340
-
主题种子词的情感分析方法2018-01-04 1355
-
将对话中的情感分类任务建模为序列标注 并对情感一致性进行建模2021-01-18 3850
-
绍华为云在细粒度情感分析方面的实践2021-03-08 2391
-
面向用户评论的方面级情感分析技术综述2021-05-29 853
-
图模型在方面级情感分析任务中的应用2022-11-24 2935
-
ACL、RBAC、ABAC三大权限管理模型,到底怎么选?2023-04-24 10517
-
华为企业交换机ACL设置案例分析2023-08-14 1761
-
工业级POE交换机的ACL2024-04-17 1041
-
基于LSTM神经网络的情感分析方法2024-11-13 1687
全部0条评论

快来发表一下你的评论吧 !
