

构建算法的推荐步骤
描述
一、构建算法的推荐步骤
当我们遇到一个问题,比如预测房价,我们想要用机器学习算法来更好的解决这个问题,推荐的步骤如下:
1.1 实现一个简单的算法
建议先花点时间实现一个简单能用的算法,比如线性回归预测房价,不需要一开始就花很多时间设计复杂的算法(在软件开发中叫避免过早优化)
你可以先实现能用的算法,然后利用上篇文章从 0 开始机器学习 - 机器学习算法诊断中的学习曲线等诊断法来分析算法的优化方向,这样一个简单的算法就成为了优化问题的好工具!
1.2 分析学习曲线
有个简单的算法后,我们就可以画出学习曲线了,然后就可以决定下一步到底要往哪个方向做优化:
获得更多的训练样本
尝试减少特征的数量
尝试获得更多的特征
尝试增加多项式特征
尝试减少正则化程度
尝试增加正则化程度
...
1.3 误差分析
假如我们有多个方向可以作为优化的方向,比如以下的方向都可以解决模型的高方差问题:
获得更多的训练样本 - 适用于高方差的模型
尝试减少特征的数量 - 适用于高方差的模型
尝试增加正则化程度 - 适用于高方差的模型
那我们又如何来评估每种方法的性能到底提升多少呢?或者说有没有一种直接的指标来告诉我,使用了这样一种优化措施后我的算法性能到底提高了多少百分比?
今天就来看看如何分析机器学习算法的误差。
二、机器学习算法误差分析
2.1 偏斜类问题
在介绍误差分析指标前,先来了解一个偏斜类问题:
训练集中有非常多同一类的样本,只有很少或者没有其他类的样本,这样的训练样本称为偏斜类。
比如预测癌症是否恶性的 100 个样本中:95 个是良性的肿瘤,5 个恶性的肿瘤,假设我们在这个样本上对比以下 2 种分类算法的百分比准确度,即分类错误的百分比:
普通非机器学习算法:人为把所有的样本都预测为良性,则分错了 5 个恶性的样本,错误率为 5 / 100 = 0.05 = 5%
神经网络算法:训练后预测 100 个样本,把 10 个良性的样本误分类为恶性的样本,错误率为 10 / 100 = 10%
如果仅仅从错误率大小来判断算法的优劣是不合适的,因为第一种人为设置样本都为良性的算法不会在实际项目中使用,但是通过指标却发现效果比神经网络还要好,这肯定是有问题的。
正是因为存在这么一种偏斜类的训练样本,所以我们需要用一个更加一般性的算法准确度评价指标,以此适用与任何类型的样本,解决上面那种荒唐的结论。
2.2 查准率与查全率
为了解决这个问题,使用查准率(Precision)和查全率(Recall)这 2 个误差指标,为了计算这 2 者,我们需要把算法预测的结果分为以下 4 种:
正确肯定(True Positive,TP):预测为真,实际为真
正确否定(True Negative,TN):预测为假,实际为假
错误肯定(False Positive,FP):预测为真,实际为假
错误否定(False Negative,FN):预测为假,实际为真
把这 4 个写到表格里面:
| Positive | Negative | |
| Positive | TP | FN |
| Negative | FP | TN |
| 实际值 预测值 |
|---|
然后我们就可以定义这 2 个指标啦:
查准率 = TP / (TP + FP):预测为真(恶性肿瘤)的情况中,实际为真(恶性肿瘤)的比例,越高越好
查全率 = TP / (TP + FN):实际为真(恶性肿瘤)的情况中,预测为真(恶性肿瘤)的比例,越高越好
有了这 2 个指标我们再来分析下上面的算法性能,第一个人为的算法认为所有的肿瘤都是良性的,也就等价于原样本中 5 个恶性的肿瘤样本一个都没有预测成功,也即所有恶性肿瘤样本,该算法成功预测恶性肿瘤的比例为 0,所以查全率为 0,这说明该算法的效果并不好。
2.3 查准率与查全率的整合
在实际的使用中,查准率和查全率往往不能很好的权衡,要想保持两者都很高不太容易,通过使用以下的公式来整合这 2 个评价指标可以帮助我们直接看出一个算法的性能优劣:
以后评价一个算法的性能直接比较 F1 Score 即可,这就大大方便了我们对比算法的性能。
三、机器学习的样本规模
除了评价指标,还有一个要关心的问题就是样本的规模,在机器学习领域有一句话:「取得成功的人不是拥有最好算法的人,而是拥有最多数据的人」
这句话的意思就是说当我们拥有非常多的数据时,选择什么样的算法不是最最重要的,一些在小样本上表现不好的算法,经过大样本的训练往往也能表现良好。
比如下面这 4 种算法在很大样本上训练后的效果相差不是很大,但是在小样本时有挺大差距:
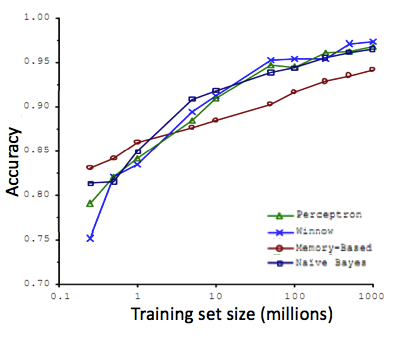
但在实际的机器学习算法中,为了能够使得训练数据发挥最大效用,我们往往会选一个比较好的模型(不太容易欠拟合,比如神经网络),再加上很多的样本数据(防止过拟合)
通过这 2 者就可以让一个算法变的很强大,所以以后当你设计机器学习算法的时候一定要考虑自己的样本规模,选择合适的模型适应你的数据,如果你有很多很多的数据,那么可以选择复杂一点的模型,不能白白浪费你的数据!
-
使用SSR构建React应用的步骤2024-11-18 1529
-
EEMD方法的原理与算法实现步骤2023-10-23 740
-
介绍从一组可重用的验证组件中构建测试平台所需的步骤2023-06-13 1364
-
有什么方法可以添加闪存前和闪存后构建步骤吗?2023-03-02 530
-
TensorRT构建具有动态形状的引擎的步骤2022-05-13 4341
-
OpenHarmony Dev-Board-SIG专场:搭建编译构建主要步骤2021-12-28 1552
-
PID算法调试步骤2021-11-30 1351
-
怎么将#define值传递给后期构建步骤?2019-10-08 1400
-
六大步骤学习贝叶斯算法2019-07-16 2333
-
MAKEFILE条件预构建步骤2019-01-30 1484
-
RNN算法的三个关键步骤2018-12-28 3633
-
WSN中能量有效的连通支配集构建算法2018-03-06 943
-
基于设备性能的蓝牙散列网构建算法2009-03-29 532
全部0条评论

快来发表一下你的评论吧 !
