

使用知识图谱作为输入的表征,研究一个端到端的graph-to-text生成系统
描述
背景
生成表达复杂含义的多句文本需要结构化的表征作为输入,本文使用知识图谱作为输入的表征,研究一个端到端的graph-to-text生成系统,并将其应用到科技类文本写作领域。作者使用一个科技类文章数据集的摘要部分,使用一个IE来为每个摘要提取信息,再将其重构成知识图谱的形式。作者通过实验表明,将IE抽取到知识用图来表示会比直接使用实体有更好的生成效果。
graph-to-text的一个重要任务是从 Abstract Meaning Representation (AMR) graph生成内容,其中图的编码方法主要有graph convolution encoder,graph attention encoder,graph LSTM,本文的模型是graph attention encoder的一个延伸。
数据集
作者构建了一个Abstract GENeration Dataset(AGENDA),该数据包含40k个AI会议的论文标题和摘要。对于数据集中的每篇摘要,首先使用SciIE来获取摘要中的命名实体及实体之间的关系(Compare, Used-for, Feature-of, Hyponymof,Evaluate-for, and Conjunction),随后将得到的这些组织成无连接带标签图的形式。
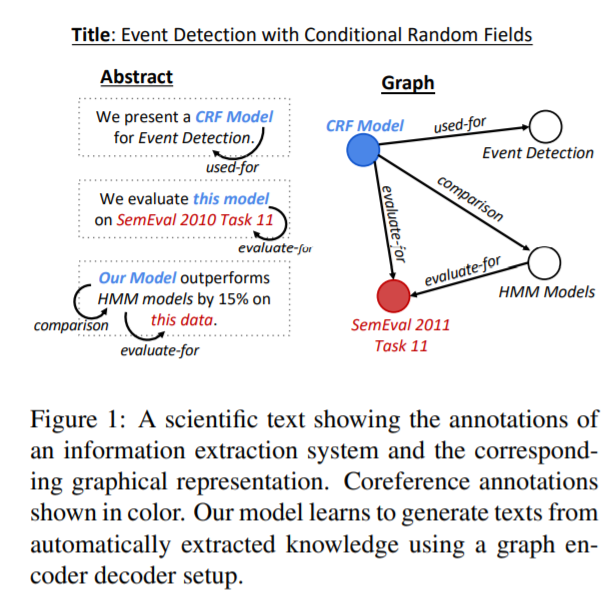
模型
GraphWriter模型总览

编码器
构建图
将之前数据集中的无连接带标签图,转化为有连接无标签图,具体做法为:原图中的每个表示关系的边用两个节点替代,一个表示正向的关系,一个表示反向的关系;增加一个与所有实体节点连接全局向量节点,该向量将会被用来作为解码器的初始输入。下图中表示实体节点,表示关系,表示全局向量节点

最终得到的有连接,无标签图为G=(V,E),其中V表示实体/关系/全局向量节点,E表示连接矩阵(注意这里的G和V区别上述图中的G和v)。
Graph Transformer

Graph Transformer由L个Block Network叠加构成,在每个Block内,节点的嵌入首先送入Graph Attention模块。这里使用多头自注意力机制,每个节点表征通过与其连接的节点使用注意力,来得到上下文相关的表征。得到的表征随后再送入正则化层和一个两层的前馈神经网络层。最后一层的得到的即表示上下文后的实体,关系,全局向量节点。

解码器
在每个时间步t使用隐藏状态来计算图和标题的上下文向量 和,其中 通过 使用多头注意力得到,

也通过类似的方式得到,最终的上下文向量是两者的叠加。随后使用类似pointer-network的方法来生成一个新词或复制一个词,
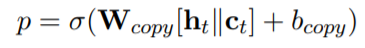

实验
实验包含自动和人工评估,在自动评估中,GraphWriter代表本篇文章的模型,GAT中将Graph Transformer encoder使用一个Graph Attention Network替换,Entity Writer仅使用到了实体和标题没有图的关系信息,Rewriter仅仅使用了文章的标题,

从上图可以看到,使用标题,实体,关系的模型(GraphWriter和GAT)的表现要显著好于使用更少信息的模型。在人工评估中,使用Best-Worst Scaling,

- 相关推荐
- 热点推荐
- 数据集
- Transformer
- 知识图谱
-
知识图谱:知识图谱的典型应用2022-10-18 3674
-
知识图谱Knowledge Graph构建与应用2022-09-17 1227
-
知识图谱是什么,它在安全领域的应用分析2021-12-04 2627
-
Fudan DISC实验室将分享三篇关于知识图谱嵌入模型的论文2021-04-15 4186
-
知识图谱与训练模型相结合和命名实体识别的研究工作2021-03-29 5487
-
知识图谱划分的相关算法及研究2021-03-18 1414
-
一文带你读懂知识图谱2020-12-26 5531
-
知识图谱的三种特性评析2019-12-13 2973
-
KGB知识图谱技术能够解决哪些行业痛点?2019-10-30 2446
-
KGB知识图谱基于传统知识工程的突破分析2019-10-22 3301
-
如何使用知识图谱对图像语义进行分析技术及应用研究2018-11-21 1951
-
知识图谱是什么?与传统知识表示的区别2018-10-29 28939
-
各种知识图谱精化方法,为国内同行介绍本领域的最新研究成果2018-09-23 7671
-
知识图谱在推荐系统中可能的应用价值2018-06-06 6800
全部0条评论

快来发表一下你的评论吧 !
