

阿里巴巴B2B在电商结构化信息挖掘和场景应用
描述
导读:发展是平台永恒的话题,以电商平台为例,在基于用户身份、历史行为挖掘偏好,以实现精准搜索和推荐结果展示之外,为了激励用户在平台进行更多采购,需要专门构建强化采购激励、拓宽采购品类的场景。本文以知识图谱为切入点,重点讲解了阿里巴巴B2B在电商结构化信息挖掘和场景应用等方面的经验。
知识图谱并不是一个全新的概念,它经历了知识工程、专家系统、语义网络等多种形式。
01
知识工程与专家系统
在1977年第五届国际人工智能会议上,美国斯坦福大学计算机科学家Edward A. Felgenbaum发表的文章The art of artificial intelligence. 1. Themes and case studies of knowledge engineering,系统性地阐述了“专家系统”的思想,并且提出了“知识工程”的概念。他认为:“知识工程利用了人工智能的原理和方法,为那些需要专家知识才能解决的应用难题提供求解的一般准则和工具。在1984年8月全国第五代计算机专家讨论会上,史忠植教授提出:“知识工程是研究知识信息处理的学科,提供开发智能系统的技术,是人工智能、数据库技术、数理逻辑、认知科学、心理学等学科交叉发展的结果。” 专家系统最成功的案例是DEC的专家配置系统XCON。1980年,XCON最初被用于DEC位于新罕布什尔州萨利姆的工厂,它拥有大约2500条规则。截至1986年,它一共处理了80 000条指令,准确率达到95%~98%。据估计,通过减少技师出错时送给客户的组件以加速组装流程和增加客户满意度,它每年为DEC节省2500万美元。 一个典型的专家系统如图1所示,其特点主要包括:
在特定领域里要具有和人一样或者超出人的高质量解决困难问题的能力;
拥有大量、全面的关于特定领域的专业知识;
采用启发的方法来指导推理过程,从而缩小解决方案的搜索范围;
能够提供对自己的推理决策结果进行解释的能力;
引入表示不同类型知识(如事实、概念和规则)的符号,专家系统在解决问题的时候用这些符号进行推理;
能够提供咨询建议、修改、更新、拓展能力,并能处理不确定和不相关的数据。
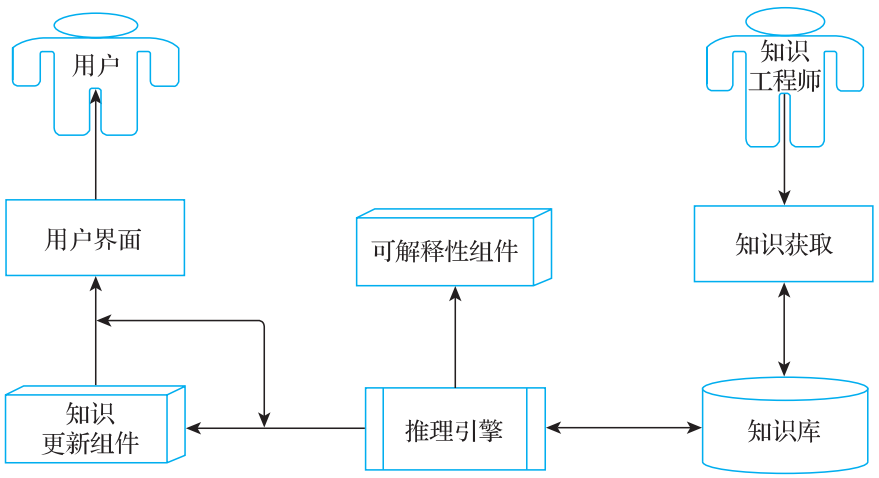
图1 专家系统架构
可以看到,专家系统大量依靠领域专家人工构建的知识库。在数据量激增、信息暴涨的当下,人工维护知识库的方式在效率和覆盖率上都难以达到令人满意的水平。另外,推理规则的增加也增加了系统的复杂度,从而导致系统非常难以维护。
02
语义网络与知识图谱
1. 语义网络伴随着Web技术的不断发展,人类先后经历了以网页的链接为主要特征的Web 1.0时代到以数据的链接(Linked Data)为主要特征的Web 2.0时代,目前Web技术正逐步朝向Web之父Berners Lee在2001年提出的基于知识互联的语义网络(semantic Web),也就是Web 3.0时代迈进。 在Web 2.0时代,互联网发展迅猛,数据的规模呈爆发式增长,基于统计的机器学习方法占据主流,并且在各个领域取得不错的成果。例如搜索引擎,搜索的流程大致可拆分为基于用户查询、召回、L2R这3个过程,一定程度提升了用户获取信息的效率。但是这种服务模式仍然是把一系列信息抛给用户,用户最终还是需要对数据进行筛选、甄别,才能拿到自己最需要的信息。因此这种服务方式在效率、准确率上都有缺陷。 语义网络的目标是构建一个人与机器都可理解的万维网,使得网络更加智能化,在解析用户查询意图的基础上,提供更加精准和快速的服务。传统的语义网络要做到这一点,就需要把所有在线文档构成的数据都进行处理并存放在一起,形成一个巨大、可用的数据库。 这么做需要强大的数据处理和Web内容智能分析能力:首先就需要对这些Web数据进行语义标注,但是由于Web数据具有体量巨大、异质异构、领域范围大等特点,所以如何自动给Web上的网页内容添加合适的标签成为技术痛点之一。另外,面对已经标注过的Web数据,机器如何进行思考和推理也是亟待解决的问题。 由于上述问题的存在,在语义网络提出后的10年间,其没有得到大规模应用,但是在对其研究的过程中,积累沉淀了成熟的本体模型建模和形式化知识表达方法,例如RDF(Resource Description Framework)和万维网本体语言(Web Ontology Language,OWL),这为后续知识图谱的出现奠定了基础。2. 知识图谱① 知识图谱概述知识图谱由Google公司于2012年5月16日第一次正式提出并应用于Google搜索中的辅助知识库。谷歌知识图谱除了显示其他网站的链接列表,还提供结构化及详细的相关主题的信息。其目标是提高搜索引擎的能力,希望用户能够使用这项功能来解决他们遇到的查询问题,从而提高搜索质量和用户体验。 知识图谱是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其之间的关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性-值对,实体间通过关系相互连接,构成网状的知识结构。随着知识图谱构建规模越来越大,复杂度越来越高,开始出现实体、类别、属性、关系等多颗粒度、多层次的语义单元,这些关联关系通过统一的知识模式(Schema)抽象层和知识实例(Instance)层共同作用构成更加复杂的知识系统。 从定义中可以看到,知识图谱是一个语义知识库,具备足够的领域知识,其最重要的组成成分是三元组。三元组通常可以表示为G=
03
知识图谱构建
知识图谱构建是一个系统工程,涵盖多种信息处理技术,用于满足图谱构建过程中的各种需要。典型的图谱构建流程主要包括:知识抽取、知识推理和知识存储。 知识表示贯穿于整个知识图谱构建和应用的过程,在不同阶段知识表示具有不同的体现形式,例如在图谱构建阶段,知识表示主要用于描述知识图谱结构,指导和展示知识抽取、知识推理过程;在应用阶段,知识表示则主要考虑上层应用期望知识图谱提供什么类型的语义信息,用以赋能上层应用的语义计算。 本节重点讲述面向应用的知识图谱表示。1. 知识抽取知识抽取是知识图谱构建的第一步,是构建大规模知识图谱的关键,其目的是在不同来源、不同结构的基础数据中进行知识信息抽取。按照知识在图谱中的组成成分,知识抽取任务可以进一步细分为实体抽取、属性抽取和关系抽取。 知识抽取的数据源有可能是结构化的(如现有的各种结构化数据库),也有可能是半结构化的(如各种百科数据的infobox)或非结构化的(如各种纯文本数据)。针对不同类型的数据源,知识抽取所需要的技术不同,技术难点也不同。通常情况下,一个知识图谱构建过程面对的数据源不会是单一类型数据源。 本节重点介绍针对非结构化文本数据进行信息抽取的技术。如上文所述,实体和属性间的界线比较模糊,故可以用一套抽取技术实现,所以下文如果不做特殊说明,实体抽取泛指实体、属性抽取。① 实体抽取实体抽取技术历史比较久远,具有成体系、成熟度高的特点。早期的实体抽取也称为命名实体识别(Named Entity Recognition,NER),指的是从原始语料中自动识别出命名实体。命名实体指的是具有特定意义的实体名词,如人名、机构名、地名等专有名词。实体是知识图谱中的最基本的元素,其性能将直接影响知识库的质量。按照NER抽取技术特点,可以将实体抽取技术分为基于规则的方法、基于统计机器学习的方法和基于深度学习的方法。
基于规则的方法:
基于规则的方法首先需要人工构建大量的实体抽取规则,然后利用这些规则在文本中进行匹配。虽然这种方法对领域知识要求较高,设计起来会非常复杂,且实现规则的全覆盖比较困难,移植性比较差,但是在启动的时候可以通过这个方法可以快速得到一批标注语料。
基于统计机器学习的方法:
既然是机器学习的方法,就需要标注语料,高质量的标注语料是通过这类方法得到好的效果的重要保障。该方法的实现过程为:在高质量的标注语料的基础上,通过人工设计的特征模板构造特征,然后通过序列标注模型,如隐马尔可夫模型(Hidden Markov Model,HMM)、最大熵模型(Maximum Entropy Model,MEM)和条件随机场模型(Conditional Random Fields,CRF)进行训练和识别。 模型特征的设计需要较强的领域知识,需要针对对应实体类型的特点进行设计。例如,在人名识别任务中,一个中文人名本身的显著特点是一般由姓和一两个汉字组成,并且人名的上下文也有一些规律,如“×××教授”“他叫×××”。在有了高质量的标注语料的基础上,合适的特征设计是得到好的序列标注模型效果的又一重要保障。 对于序列标注模型,一般我们对需要识别的目标字符串片段(实体)通过SBIEO(Single、Begin、Inside、End、Other)或者SBIO(Single、Begin、Inside、Other)标注体系进行标注。命名实体标注由实体的起始字符(B)、中间字符(I)、结束字符(E)、单独成实体的字符(S)、其他字符(O)等组成,如图2所示。

图2 命名实体标注
为了区分实体的类型,会在标注体系上带上对应的类型标签,例如ORG-B、ORG-I、ORG-E。 在实体抽取中,我们最常用的基于统计的序列标注学习模型是HMM、CRF。其中,HMM描述由隐藏的隐马尔可夫随机生成观测序列的联合分布的P(X,Y)过程,属于生成模型(Generative Model),CRF则是描述一组输入随机变量条件下另一组构成马尔可夫随机场的数据变量的条件概率分布P(Y|X),属于判别模型(Discrimination Model)。 以HMM为例,模型可形式化表示为λ= (A,B,π),设I是长度为T的状态序列,O是对应长度的观测序列,M为所有可能的观测数(对应于词典集合大小),N为所有状态数(对应标注的类别数),A是状态转移矩阵:
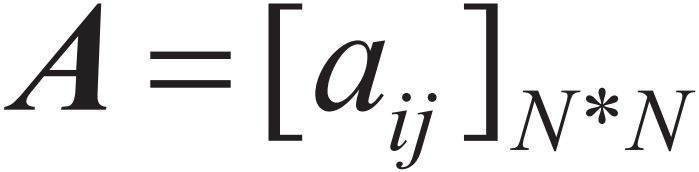
其中:
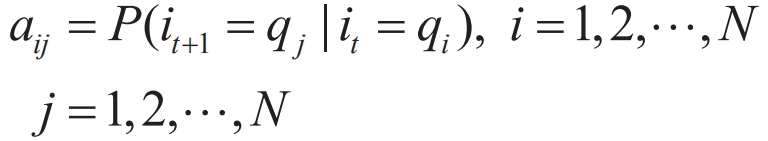
aij表示在时刻t处于qi的条件下在时刻t+1转移到qj的概率。 B是观测概率矩阵:
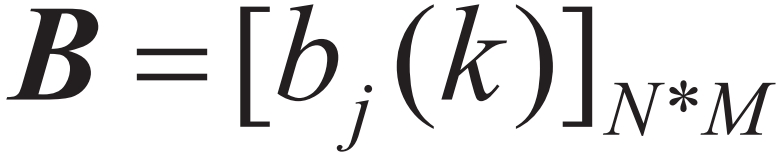
其中:
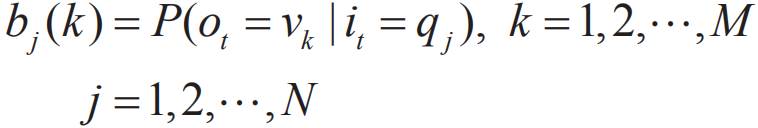
π是初始状态概率向量:
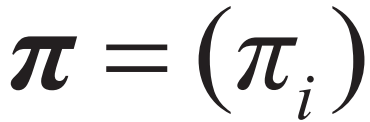
其中:
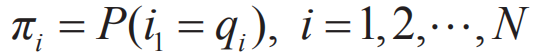
πi表示在时刻t=1处于状态qi的概率。 HMM模型的参数学习即学习上面的A,B,π矩阵,有很多实现方法,比如EM和最大似然估计。一般在语料充足的情况下,为了简化过程,采用最大似然估计,例如:
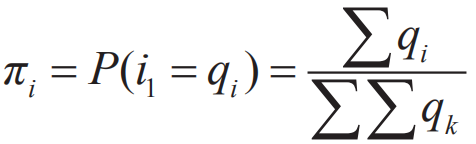
序列标注任务可以抽象为求解给定观察序列O=(o1,o2,...,oT)和模型λ=(A,B,π),也就是计算在模型λ下使给定观测序列条件概率P(I|O)最大的观测序列I=(i1,i2,...,iT),即在给定观测序列(即原始字符串文本)中求最有可能的对应的状态序列(标注结构)。一般采用维特比算法,这是一种通过动态规划方法求概率最大路径的算法,一条路径对应一个状态序列。 定义在时刻t状态为i的所有单个路径(i1,i2,…,it)中概率最大值为:
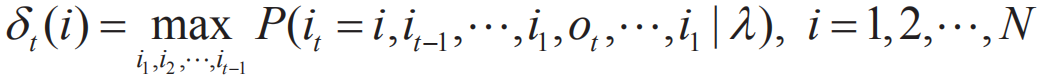
可以得到变量δ的递推公式:
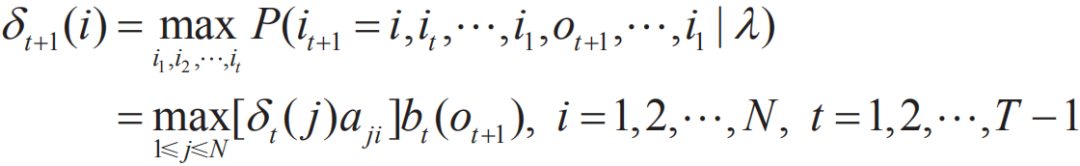
定义在时刻t状态为i的所有单个路径(i1,i2,…,it-1,i)中概率最大的路径的第t-1个节点为:
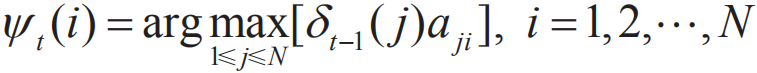
维特比算法在初始化δ1(i)=πibi(o1),Ψ1(i)=0,i=1,2,...,N之后,通过上述递推公式,得到最优序列。 CRF算法与维特比算法类似,其得到在各个位置上的非规范化概率的最大值,同时记录该路径:
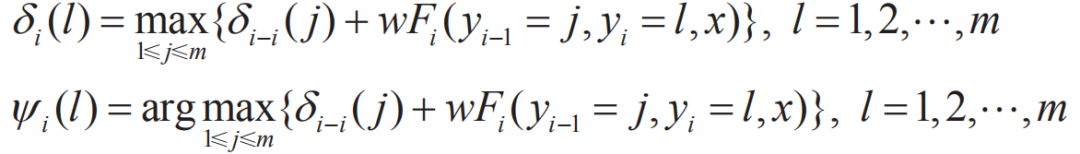
基于深度学习的方法
在上面介绍用统计机器学习的方法构造特征的时候,我们发现实体在原始文本中的上下文特征非常重要。构建上下文特征需要大量的领域知识,且要在特征工程上下不少功夫。随着深度学习的方法在自然语言处理上的广泛应用,构建上下文特征开始变得简单了。深度学习的方法直接以词/字向量作为输入,一些模型(如RNN、Transformer等)本身就能很好地学习到上下文信息,并且不需要专门设计特征来捕捉各种语义信息,相比传统的统计机器学习模型,性能都得到了显著提高。这一类模型的通用结构基本都是一个深度神经网络+CRF,如bi-LSTM-CRF、IDCNN-CRF、LSTM-CNN-CRF、Bert-biLSTM-CRF等,模型可以基于字或词输入(一般来说,基于字的模型性能更加优秀,它可以有效解决OOV问题)。这个DNN模型可以学习上下文语义特征、预测各个位置上输出各个标签的概率,然后再接入CRF层来学习各标签之间的依赖关系,得到最终的标注结果。② 关系抽取关系抽取的目标是抽取两个或者多个实体间的语义关系,从而使得知识图谱真正成为一张图。关系抽取的研究是以MUC(Message Understanding Conference)评测会议和后来取代MUC的ACE(Automatic Content Extraction)评测会议为主线进行的。ACE会议会提供测评数据,现在许多先进的算法已经被提出。 一般关系抽取的顺序是,先识别实体,再抽取实体之间可能存在的关系。其实也可以把实体抽取、关系抽取联合在一起同时完成。目前,关系抽取方法可以分为基于模板的关系抽取和基于监督学习的关系抽取两种方法。
基于模板的关系抽取
基于模板的关系抽取,即由人工设计模板,再结合语言学知识和具体关系的语料特点,采用boot-strap思路到语料里匹配并进行抽取关系。这种方法适用于小规模、特定领域任务冷启动时的关系抽取,这种场景下效果比较稳定。
基于监督学习的关系抽取
基于监督学习的关系抽取方法一般把关系抽取任务当作一系列的分类问题处理。即基于大规模的标注语料,针对实体所在的句子训练有监督的分类模型。分类模型有很多,例如统计机器学习方法SVM及深度学习方法(如CNN)等。 传统的机器学习方法重点在特征选择上,除了实体本身的词特征,还包括实体词本身、实体类型、两个实体间的词以及实体距离等特征。很多研究都引入了依存句法特征,用以引入实体间的线性依赖关系。基于深度学习的关系抽取方法则不需要人工构建各种特征,输入一般只要包括句子中的词及其位置的向量表示特征。目前基于深度学习的关系抽取方法可以分为流水线方法(Pipeline)和联合抽取方法(Jointly)。前者是将实体识别和关系抽取作为两个前后依赖的分离过程;后者则把两个方法相结合,在统一模型中同时完成,从而避免流水线方法中存在的错误累计问题。 在经典的深度学习关系抽取方法中,输入层采用的就是词、位置信息,将在Embedding层得到的向量作为模型的输入,经过一个BI-LSTM层和Attention层,输出得到各个关系的概率,如图3所示。
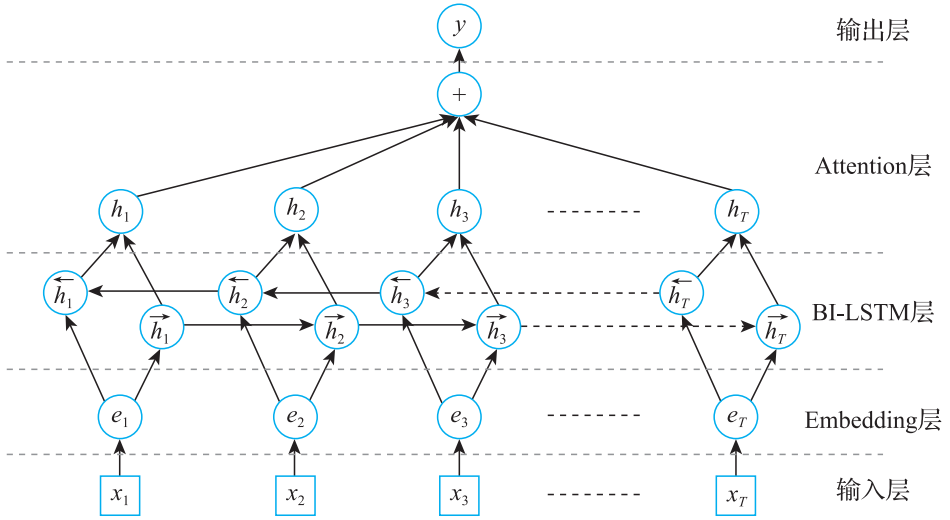
图3 经典深度学习关系抽取模型架构
③ 知识融合通过知识抽取,我们得到大量实体(属性)和关系,但是由于描述、写法的不同,结果中存在大量冗余和错误信息,有必要对这些数据进行消歧、清洗和整合处理。作为知识融合的重点技术,实体链接(Entity Linking)的目的是将在文本中抽取得到的实体对象链接到知识库中与之对应的唯一确定的实体对象,以实现实体消歧和共指消解。 实体消歧(Entity Disambiguation)专门用于解决同名实体的歧义问题,最简单的方法是通过实体的属性、周边的词构成特征向量,通过向量的余弦相似度评估两个实体的相似度。基于这个思想,我们可以有更多的基于语义的方法来表征目标实体,从而评估两个实体是否是同一个。 共指消解(Entity Resolution)是指解决多个不同写法的实体指向同一个实体的问题。一般这类问题可以参考实体消歧方法解决,也可以具体问题具体分析,通过一些规则方法解决。2. 知识推理知识推理是基于现有的知识图谱结构,进一步挖掘隐含的知识,用来补全现有知识图谱属性、关系,从而发现新的知识,拓展和丰富图谱。例如可以通过推理发现新属性,如由已知实体的出生年月属性推理出年龄;也可以发现新关系,例如,已知(A,股东,B公司)、(C,股东,B公司)可以推理得出(A,合作伙伴,C)。知识推理的方法可以分为两大类:基于逻辑的推理和基于图的推理。① 基于逻辑的推理基于逻辑的推理主要包括一阶谓词逻辑(First Order Logic)推理、描述逻辑(Description Logic)推理。一阶谓词对应着知识库里的实体对象和关系,通过谓词之间的“与”和“或”的关系来表示知识变迁从而实现推理。例如通过“妈妈是女人”“女人是人”可以推理得到“妈妈是人”。描述逻辑则是在一阶谓词的基础上,解决一阶谓词逻辑的表示能力有限的问题,通过TBox(Terminology Box)和ABox(Assertion Box),可以将知识图谱中复杂的实体关系推理转化为一致性的检验问题,从而简化推理。② 基于图的推理基于图的推理方法,主要借助图的结构特征,通过路径游走的方法,如Path Ranking算法和神经网络图向量表示方法,进行基于图的推理。Path Ranking算法的基本思想是从图谱的一个节点出发,经过边在图上游走,如果能够通过一个路径到达目标节点,则推测源节点和目标节点存在关系。神经网络图向量表示方法则是对通过向量表示后的图节点、关系进行相似度运算,推理节点之间是否存在关系。3. 知识图谱存储知识图谱中的信息可以用RDF结构表示,它的主要组成成分是三元组,主要包括实体及其属性、关系三类元素。在实际应用中,按照底层数据库的存储方式不同,可以分成基于表结构的存储和基于图结构的存储。基于表结构的存储可以理解为一般的关系型数据库,常见的如MySQL、Oracle,基于图存储的数据库常见的有Neo4j、OrientDB、GraphDB等。① 基于表结构的存储基于表结构的知识图谱存储利用二维数据表对知识图谱中的数据进行存储,有3种常见的设计方案:基于三元组的存储、基于类型表的存储和基于关系型数据库的存储。
基于三元组的存储
因为知识图谱可以由三元组描述,所以我们可以把知识图谱转化成三元组的描述方式,将其放到一张数据表中。例如可以类似表1所示的形式。

表1 三元组存储示例
这种存储的优点很明显,结构比较简单,可以通过再加一些字段来增强对关系的信息的描述,例如区分是属性还是关系。其缺点也很明显:首先,这样有很高的冗余,存储开销很大,其次,因修改、删除和更新操作带来的操作开销也很大;最后,由于所有的知识都是以一行一个三元组的方式存储的,因此所有的复杂查询都要拆分为对三元组的查找才能得到答案。
基于类型表的存储
针对上述方案存在的缺点,可以为每一种实体类型设计一张数据库表,把所有同一类型的实体都放在同一张表中,用表的字段来表示实体的属性/关系。这种方案可解决上面存储简单、冗余度高的问题,但是缺点也很明显:首先,表字段必须事先确定,所以要求穷举实体的属性/关系,且无法新增(否则需要修改表结构);其次,因为属性/关系都是存储在特定列中的,所以无法支持对不确定类型的属性和关系的查找;最后,因为数据按照类型放在对应表中,所以在查询之前就需要事先知道实体的类型。
基于关系型数据库存储
关系型数据库通过表的属性来实现对现实世界的描述。我们可以在第二种方案的基础上设计实体表(用于存储实体属性)、关系表(用于存储实体间的关系),这一定程度上可以解决表结构固定、无法新增关系的问题,因为一般我们认为实体的属性可以在Schema设计时事先枚举完。例如表7-1,可以拆分为3张表(见表2、表3和表4)。

表2 组织机构表

表3 人物表

表4 关系表
4. 基于图结构的存储知识图谱本身就是图结构的,实体可以看作图的节点,关系可以看作图的关系,基于图的方式存储知识,可以直接、准确地反映知识图谱内部结构,有利于知识的查询、游走。基于图谱的结构进行存储,可以借用图论的相关算法进行知识推理。常见的图数据库有Neo4j、OrientDB、GraphDb、GDB(阿里云)等。 Neo4j是一个开源的图数据库,它将结构化的数据以图的形式存储,基于Java实现(现在也提供Python接口),是一个具备完全事务特性的高性能数据系统,具有成熟数据库的所有特性。Neo4j分为商业版和社区版。其中社区版是开源的,是一个本地数据库;商业版则实现了分布式功能,能够将多台机器构造成数据库集群来提供服务。它采用的查询语言是cypher,可以通过Neo4j实现知识图谱节点、关系的创建(create命令)和查询(match命令)。 Neo4j在Linux上的安装非常简单,到官网上下载对应的安装包,解压后安装到bin目录,然后通过./neo4j start命令启动。我们可以在: http://localhost:7474/browser/ 访问可视化界面(见图4),可以在这个Web页面上通过cypher和图数据库进行交互。

图4 Neo4j Web可视化界面 阿里巴巴内部也研发了图数据库用于存储知识图谱数据,如GDB、iGraph等,其中GDB(Graph Database,图数据库)是由阿里云自主研发的,是一种支持Property Graph图模型、用于处理高度连接数据查询与存储的实时、可靠的在线数据库。它支持Apache TinkerPop Gremlin查询语言,可以快速构建基于高度连接的数据集的应用程序。GDB非常适合用于社交网络、欺诈检测、推荐引擎、实时图谱、网络/IT运营这类需要用到高度互连数据集的场景。目前GDB正处于公测期间,阿里巴巴内部很多知识图谱业务都基于GDB存储,它具备如下优势:
标准图查询语言:支持属性图,高度兼容Gremlin图查询语言。
高度优化的自研引擎:高度优化的自研图计算层和存储层,通过云盘多副本方案保障数据超高可靠性,支持ACID事务。
服务高可用:支持高可用实例,单节点出故障后业务会迅速转移到其他节点,从而保障了业务的连续性。
易运维:提供备份恢复、自动升级、监控告警、故障切换等丰富的运维功能,大幅降低运维成本。
04
知识表示
知识表示是指在不同的语义环境下有不同的含义,例如在图谱构建阶段,知识表示可以认为是基于RDF用三元组形式,如“<实体,属性,值>”或者“<实体,关系,实体>”(也有描述为<主语,谓词,宾语>)来表征知识图谱的语义信息的。在知识图谱接入上层应用场景后,尤其是随着深度学习方法的广泛采用,如何将知识图谱和深度学习模型融合,借助知识图谱引入领域知识来提升深度学习模型性能,引起了学术界和工业界的广泛关注。 本节将重点介绍基于知识表示的学习方法,介绍如何将知识图谱中的高度稀疏的实体、关系表示成一个低维、稠密向量。1. 距离模型结构表示(Structured Embedding,SE),将每个实体用d维的向量表示,所有实体被投影到同一个d维向量空间中,同时,为了区分关系的有向特征,为每个关系r定义了2个矩阵Mr,1,Mr,2∈Rd*d,用于三元组中头实体和尾实体的投影操作,将头实体、尾实体投影到关系r的空间中来计算两个向量的距离,公式为:
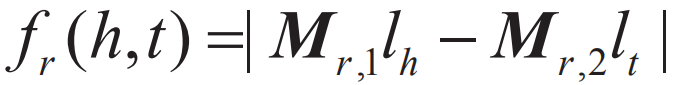
用以反映2个实体在关系r下的语义相关度,距离越小,说明这2个实体存在这种关系的可能性越大。然而该模型有一个重要缺陷,它使用头、尾两个不同的矩阵进行投影,这个矩阵相互独立没有协同,往往无法精确刻画两个实体基于关系的语义联系。为了解决这个问题,后续出现了单层神经网络模型(Single Layer Model,SLM)、语义匹配能量模型(Semantic Matching Energy,SME)等方法,如RESCAL。RESACL模型是一个基于矩阵分解的模型,在该模型中,将整个知识图谱编码为一个三维张量X,如果三元组存在,则Xhrt=1,否则为0。张量分解的目标是要将每个三元组对应的张量分解为实体和关系,使得Xhrt尽量接近lhMrlt,函数可表示为:
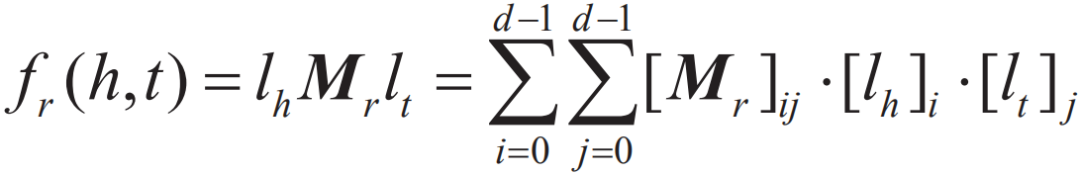
2. 翻译模型自从Mikolov等人于2013年提出word2vec模型开始,表示学习Embedding在自然语言处理领域受到广泛关注,该模型发现在词向量空间中平移(加减)不变现象,即:

其中C(w)表示w通过word2vec得到的词向量。受这类类比推理实验启发,Bordes等人提出了TransE模型,之后又出现多种衍生模型,如TransH、TransR等。TransE将知识库中的关系看作实体间的平移向量,对于每个三元组,TransE希望:
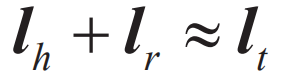
即期望头节点向量沿关系平移后,尽量和尾节点向量重合(见图5)。
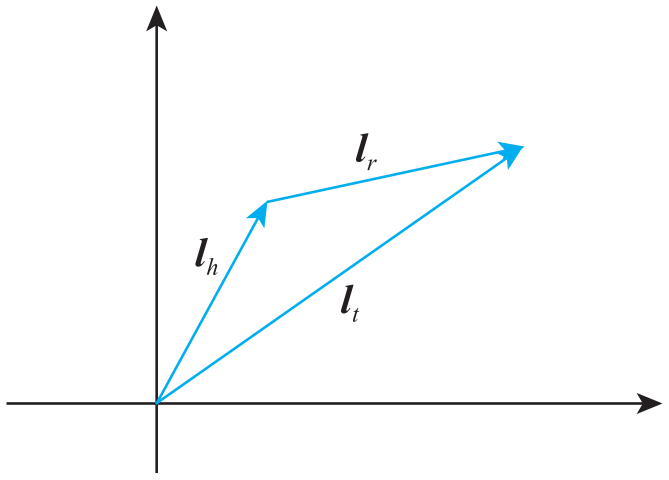
图5 TransE 模型
模型的损失函数定义如下:
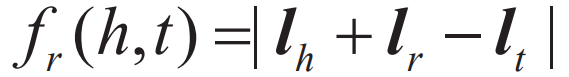
“||”表示取模运算,如L2距离。 在实际学习过程中,为了增强模型知识表示的区分能力,TransE采用了最大间隔,目标函数为:
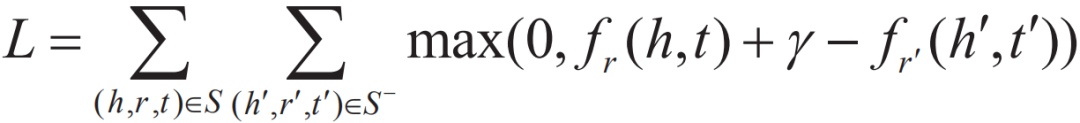
其中,S是正确的三元组集合,S-是错误的三元组集合,γ为正确三元组得分和错误三元组得分之间的间隔距离,是一个超参数。S-的产生与负样本的生成方式不同,不通过直接随机采样三元组,而是将S中每一个三元组的头实体、关系、尾实体其中之一随机替换成其他实体或关系来构造。 TransE模型简单有效,后续很多知识表示学习方法都是以此为代表进行拓展的。例如TransH模型,为了解决TransE在处理1-N、N-1、N-N复杂关系时的局限性,提出让一个实体在不同关系下拥有不同的表示。另外,虽然TransH模型使得每个实体在不同关系下拥有了不同的表示,但是它仍然假设实体和关系处于统一语义空间中,这和我们一般的认知有点不同,于是有学者提出了TransR模型。TransR模型首先通过一个投影矩阵Mr把实体投影到关系的语义空间,然后再进行关系类比推理(见图6):
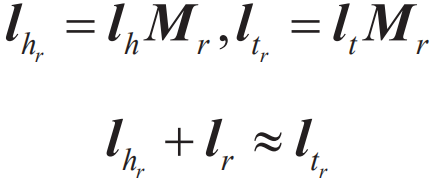
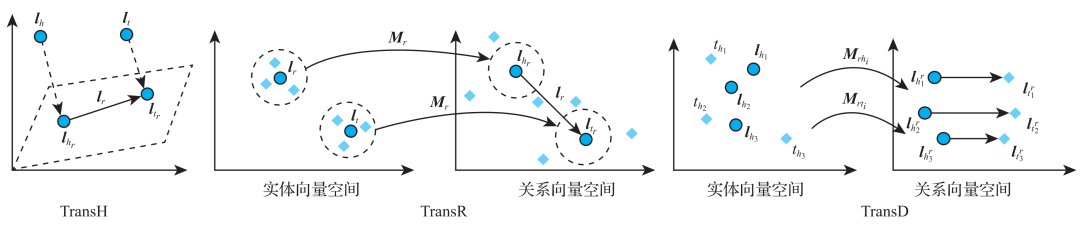
图6 各种翻译模型
05
电商知识图谱应用
知识图谱提供了一种更好的组织、管理和利用海量信息的方式,描述了现实世界中的概念、实体以及它们之间的关系。自从谷歌提出知识图谱并应用在搜索引擎中,用以提升搜索引擎使用体验,提高搜索引擎质量以后,知识图谱在各种垂直领域场景中都扮演了重要的角色。 随着消费升级,行业会场+爆款的导购模式已经无法满足消费者心智,人们对货品的需求逐渐转化为对场景的需求。通过场景重新定义货品的需求产生,场景运营平台应运而生。场景运营平台通过对商品知识的挖掘,将具有共同特征的商品通过算法模型聚合在一起,形成事实上的跨品类商品搭配。在算法端完成场景-商品知识图谱的建设后,通过当前诉求挖掘消费者深层次诉求,推荐某个场景下互相搭配的商品,给予消费者对应场景下一站式的购物体验,达到鼓励消费者跨类目购买行为及提升客单价的目的。例如在阿里电商平台,导购场景就有了很好的应用,并取得了不错的效果。 1688团队在阿里内部数据和算法基建的基础上,基于B类商品特征,构建了自己的商品知识图谱,以CPV的方式表征一个商品,具体商品表征如图7所示。

图7 商品CPV表征示意图
任何知识图谱应用的构建,整体上都要经历如下几个步骤:文本等非结构化或半结构化信息→结构化的知识图谱→知识图谱表征→特定应用场景。1688的商品知识图谱,在阿里通用的电商NLP技术的基础上,完成了半结构化信息向结构化的知识图谱转化的步骤,但是中间存在大量质量较差、语义模糊甚至错误的数据。为了优化这部分数据,阿里做了大量的工作,包括实体合并、消歧、长尾数据裁剪等。 针对初步加工过的数据,还需要大量的人工来标注清洗,以发挥数据的价值。而数据标注清洗这种累活一般是找专门的数据标注公司外包完成的。为了减少专门标注的成本,我们采用了“以战养兵”的思路,让运营直接使用这份经过初步加工的数据,通过收集运营的操作数据,快速反馈到算法模型中并不断优化结果,形成运营-数据的相互反馈,如图8所示,让工具越用越顺手,越用越好。
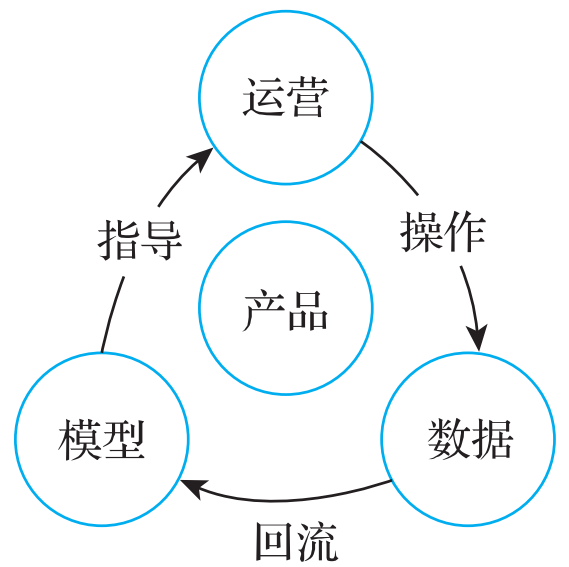
图8 主题会场搭建流程示意图
具体的主题录入方式是:运营指定一个主题场景,比如婚庆主题,在指定主题下涵盖商品的类目、属性、属性值。比如列举一组配置,可以搭配后台配置截图。通过行业运营专家的经验将主题和相应的商品图谱关联起来,我们可以明确哪些CPV数据存在业务关联,以及运营认为哪些数据是有效的。除了主题数据的人工录入,我们还配套了相关的自动化页面搭建方案。 电商经常需要做促销活动,活动会场页面的制作需要投入大量人力,常见的活动页面如图9所示。

图9 常见电商促销活动页面图
这种活动类导购页面的搭建,核心是站在买家的角度帮助他们发现和选择商品,如图10所示。其中,什么商品、如何挑选、怎样呈现就是导购页面包含的核心要素和业务流程。映射到技术领域,则会涉及建立页面、数据分析、投放策略的三个方面。
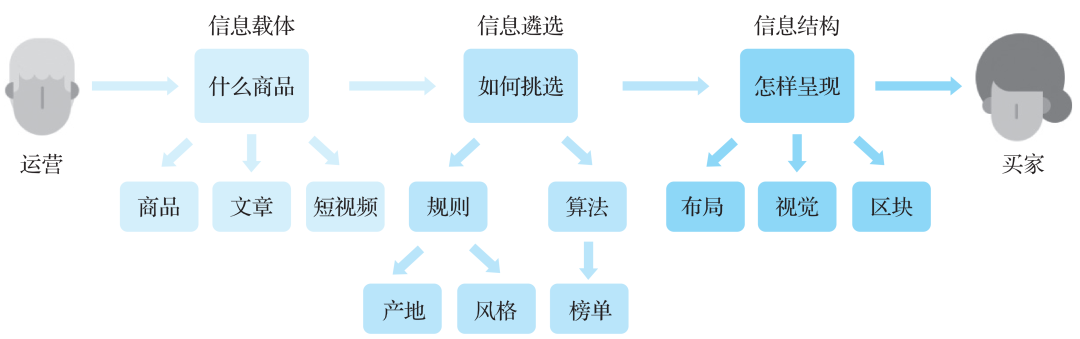
图10 活动类导购页面搭建流程示意图
1688在活动页面制作方面沉淀多年,有众多实用的技术和工具供运营使用,如页面组件化搭建产品(积木盒子、奇美拉)、指标选品工具(选品库)、商品排序投放产品(投放平台)等。这些产品都有各自的细分业务域,运营通常需要跳转到多个平台进行配置,才能完成一张活动页面的搭建,整体流程如图11所示。
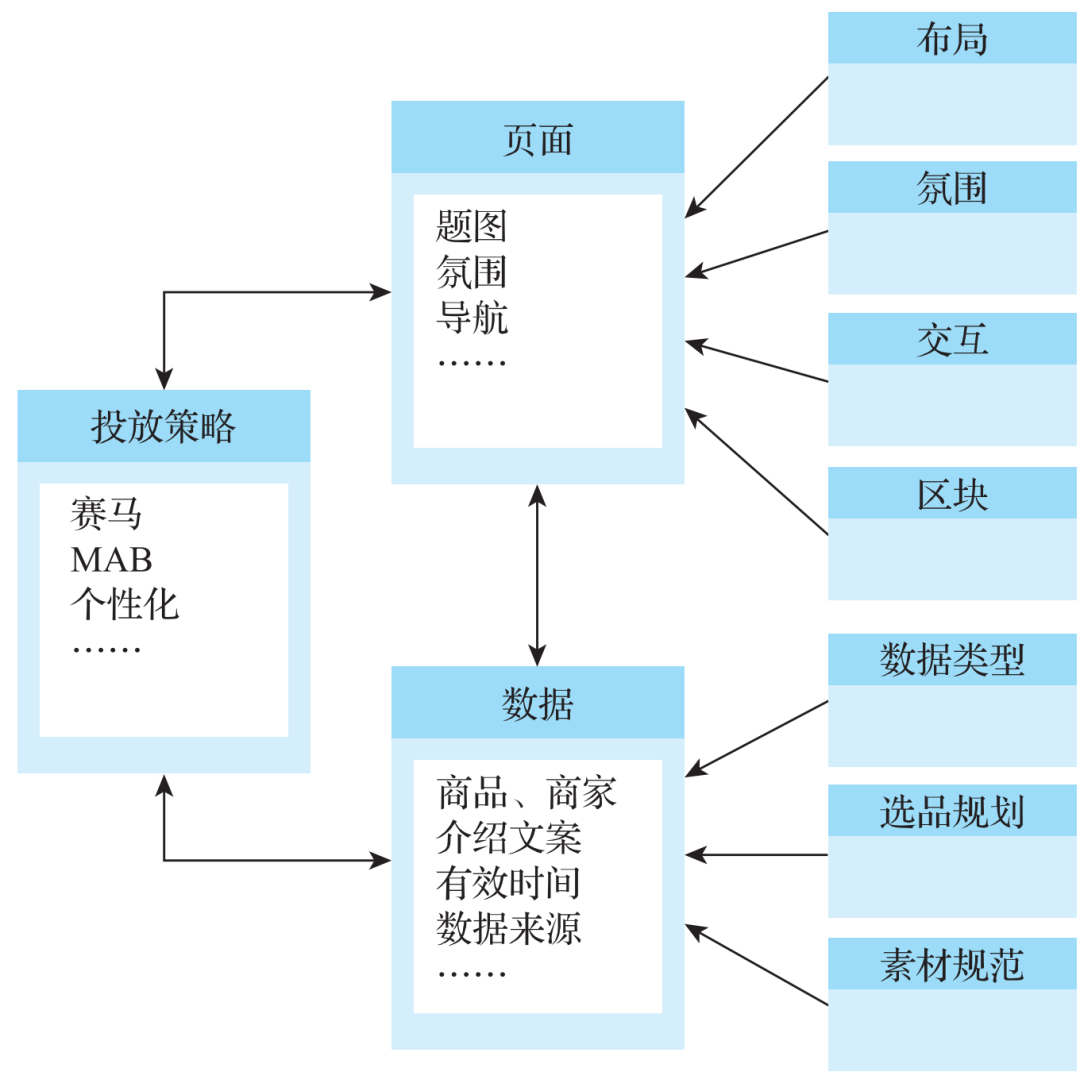
图11 活动页面搭建平台示意图
这就像是办证件,A窗口让你去B窗口登记,B窗口让你去C窗口填表。我们都围着一个个的“窗口”转,这是一种以资源为中心的工作方式。以前让用户围绕着资源转,是为了最大化资源的使用效率,但是在今天这个人力成本高的时代,需要从资源视角转向用户视角,让资源围着用户转,这样可以最大化价值流动效率。 我们通过几个月的努力,将十余个系统打通,实现了数据源标准化方案、数据页面绑定方案、页面自动多端搭建方案、投放自动化方案等,形成了如图12所示的产品体系。
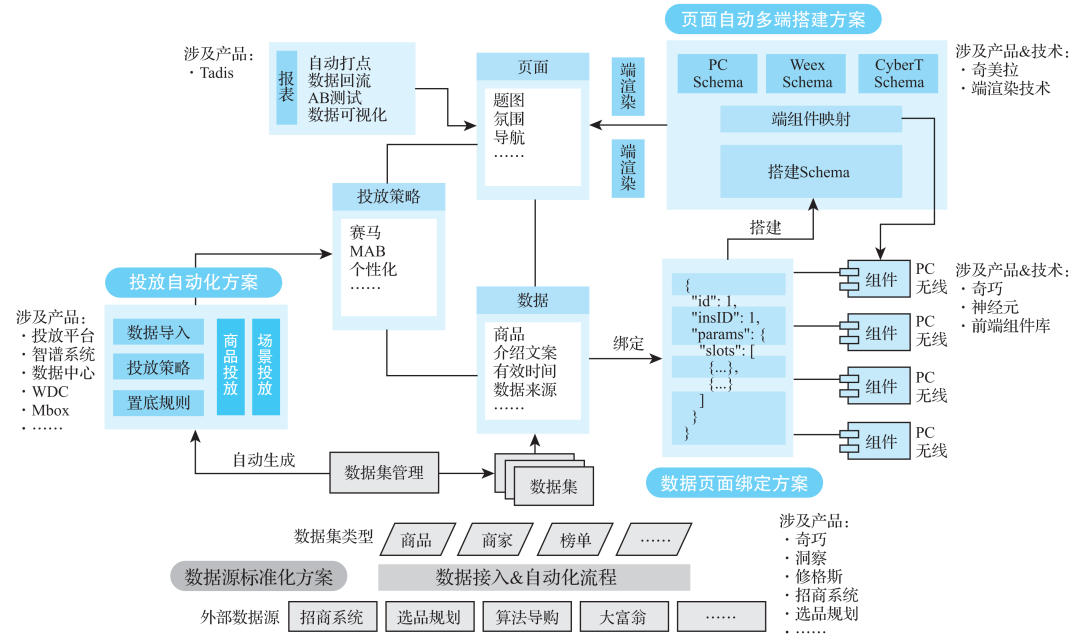
图12 会场搭建产品体系示意图
通过将系统打通,使得运营搭建一个页面的配置工作量减少了83.2%。而在剩余的16.8%的工作里,有87%是选品工作。借助主题会场,我们希望将运营选品的工作量也降低50%以上,并借助数据和算法,实现智能选品、智能搭建、智能投放。今天的分享就到这里,谢谢大家。
-
荣邦佳业有阿里巴巴啦2014-04-15 2568
-
业界可考虑如何从阿里巴巴赚200亿了2014-09-20 2746
-
2015年中国B2B行业预测:渴望春天2015-01-21 2415
-
阿里巴巴敏捷研发的探索与实践2018-03-07 4192
-
b2b是什么意思2009-05-31 15305
-
B2B电商的春天来了,元件分销要如何借到这股东风?2017-05-10 1168
-
印度电商市场大局已定,阿里巴巴在印度市场的前景未来会如何?2018-05-21 7362
-
阿里巴巴机器翻译在跨境电商场景下的应用和实践2018-07-31 806
-
印度电商市场两强相争,阿里巴巴支持Paytm mall2018-10-18 4156
-
安富利与阿里巴巴携手合作 拓展中国电商市场2019-09-26 4957
-
为什么开展跨境电商B2B出口改革,它的好处是什么2020-11-10 4978
-
TUV莱茵与阿里国际站扩大合作范围,助力欧洲中小企业B2B贸易发展2023-03-04 1221
-
B2B平台方案|药品制造业B2B电商平台解决方案2023-06-26 2048
-
阿里巴巴重返中国顶级电商轨道2024-02-27 1710
全部0条评论

快来发表一下你的评论吧 !
