

赛灵思AI引擎简介
电子说
描述
Versal ACAP 简介
Versal 自适应计算加速平台 (ACAP) 是基于 TSMC 7nm FinFET 工艺技术构建的最新一代赛灵思器件。它利用高带宽片上网络 (NoC) 将代表处理器系统 (PS) 的标量引擎、代表可编程逻辑 (PL) 的自适应引擎与智能引擎有机结合在一起。
本文将着重介绍智能引擎中所包含的 AI 引擎。
+
赛灵思 AI 引擎简介
在部分赛灵思 Versal ACAP 中包含了 AI 引擎。这些 AI 引擎可排列组合为一组与内存、数据流和级联接口相连的二维AI 引擎拼块阵列。在当前 ACAP 器件(例如,VC1902 器件)上,此阵列最多可包含 400 个拼块。此阵列中还包含AI 引擎接口(位于最后一行),以便于阵列中的其它器件(PS、PL 和 NoC)进行交互。

AI 引擎接口包含PL 和 NoC 接口拼块以及配置拼块。从 PL 到 AI 引擎阵列的连接是使用 AXI4-Stream 接口通过 PL 和 NoC 接口拼块来实现的。从 NoC 到 AI 引擎阵列的连接是使用 AXI4 存储器映射接口通过 NoC 接口拼块来实现的。

有趣的是,从中可以看到,只有在 NoC 到 AI 引擎拼块之间才存在 AXI4 存储器映射直接通信通道,在 AI 引擎拼块到 NoC 之间却并不存在。
注:PL 和 NoC 接口拼块的精确数量因器件而异。《Versal 架构和产品数据手册:简介》(DS950) 中罗列了 AI 引擎阵列的大小。
https://china.xilinx.com/support/documentation/data_sheets/ds950-versal-overview.pdf
+
AI 引擎拼块架构
现在,我们来详细了解下此阵列,看看 AI 引擎拼块的内部。
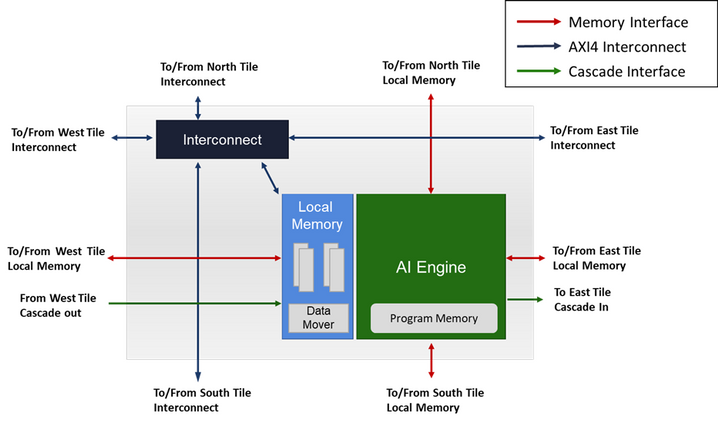
每个 AI 引擎拼块都包含:
1 个拼块互连模块,用于处理 AXI4-Stream 和存储器映射 AXI4 输入/输出
1 个存储器模块,其中包含 32 KB 数据内存,细分为 8 个内存 bank、1 个内存接口、DMA 和各种锁定。
1 个 AI 引擎
AI 引擎可访问全部 4 个方向中的多达 4 个内存模块(作为 1 个连续存储器块)。这意味着除了拼块本地的内存,AI 引擎还可以访问 3 个相邻拼块的本地内存(除非拼块位于阵列边缘)。
北侧内存模块
南侧内存模块
东侧或西侧内存模块(取决于 AI 引擎和内存模块所在的行和相对布局)。
+
AI 引擎架构
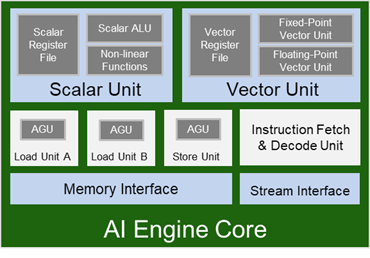
AI 引擎属于高度优化的处理器,包含下列主要特色:
32 位标量 RISC 处理器(名为 Scalar Unit)
1 个 512b SIMD 矢量单元(可提供矢量定点/整数单元)和 1 个单精度浮点 (SPFP) 矢量单元
3 个地址生成器单元 (AGU)
超长指令字 (VLIW) 功能
3 个数据内存端口(2 个负载端口,1 个存储端口)
直接流传输接口(2 个输入流,2 个输出流)
+
AI 引擎阵列编程
AI 引擎拼块按 10 或 100 为单位组成阵列。创建嵌入多项指令的单一程序用于指定并行性将是一项冗长且近乎不可能的任务。因此 AI 引擎阵列模型编程与 Kahn 处理网络 (Kahn Process Networks) 之间的共通之处在于自主计算进程通过通信边缘实现彼此互连,从而生成处理网络。
(请参阅 https://perso.ensta-paris.fr/~chapoutot/various/kahn_networks.pdf )
在 AI 引擎框架中,Graph 边缘是缓存和数据流,而计算进程则被称为内核。在Graph中,内核经过例化,彼此相连并连接到设计其余部分(NoC 或 PL)。
编程流程分为 2 个阶段:
单内核编程:
内核用于描述特定计算进程。每个内核都将在单一 AI 引擎拼块上运行。但请注意,多个内核可在同一个 AI 引擎拼块上运行,并共享处理时间。任意 C/C++ 代码均可用于对 AI 引擎进行编程。标量处理器将处理大部分代码。如果您的目标是设计高性能内核,那么应考虑采用矢量处理器,它使用称为内部函数的专用函数。这些函数专用于 AI 引擎的矢量处理器,支持您从 AI 引擎中发掘出巨大的处理性能。赛灵思将提供预构建内核(包含在库内),以供用户在其定制 Graph 中使用。
Graph 编程:
赛灵思将提供 C++ 框架以从内核创建Graph。此框架包含 Graph 节点和连接声明。这些节点可包含在 AI 引擎阵列内或可编程逻辑(HLS 内核)中。为了完全掌握内核位置,将有一系列方法可用来约束布局(内核、缓存、系统内存等)。Graph 将例化并使用缓存和数据流将内核连接在一起。它还将描述 AI 引擎阵列与其它ACAP 器件(PL 或 DDR)之间的双向往来数据传输。
赛灵思将提供预构建 Graph(包含在库内),以供用户在其应用中使用。
在运行时以及仿真期间,AI 引擎应用由 PS 进行控制。
赛灵思将根据应用的操作系统提供多种 API,如下所述。
Xilinx Run Time (XRT) 和 OpenCL,适用于 Linux 应用
裸机驱动程序
-
使用赛灵思MATLAB & Simulink Add-on插件面向Versal AI引擎设计2021-01-28 2142
-
赛灵思和戴姆勒宣布将共同开发基于Xilinx AI技术的车载系统2018-06-27 9719
-
赛灵思与戴姆勒联袂开发AI解决方案2018-06-29 4028
-
赛灵思AI引擎及其应用的详细资料说明2019-02-22 1470
-
赛灵思AI方案三大重点2019-07-25 2975
-
赛灵思分享:智能引擎中所的AI引擎技术分析2020-10-11 4255
-
使用赛灵思插件面向 Versal AI 引擎设计2022-02-08 1892
-
赛灵思AI引擎及其应用2023-09-18 598
全部0条评论

快来发表一下你的评论吧 !
