

美国公司构建新型机器学习模型,可从音频中捕捉到重大安全事故的信息
电子说
描述
在美国各大主要城市,市民一天24小时会切到数千个公共第一响应者无线电波,这些信息用于给500多万用户提供火灾、抢劫和失踪等突发事件的实时安全警报。每天人们收听音频的总时长会超过1000小时,这给需要开发新城市的公司带来了挑战。
因此,我们构建了一个机器学习模型,它可以从音频中捕捉到重大安全事故的信息。
定制的软件适用无线电(SDR)会捕捉大范围内的无线电频率(RF),将优化后的音频片段发送到ML模型进行标记。标记后的片段会被发送至操作分析员,他们将在app中记录事件,最后通知事故地点附近的用户。
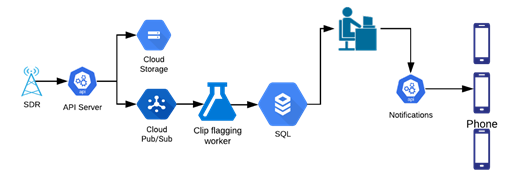
安全警报工作流程(图自作者)
为适应问题领域,调整一个公共语音转文本引擎
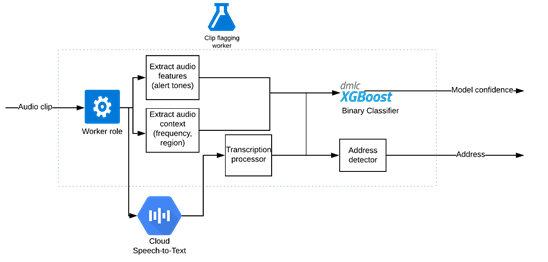
运用公共语音转文本引擎的剪辑分类器 (图自作者)
依据单词错误率(WER),我们将从一个性能最好的语音转文本引擎着手。很多警察使用的特殊代码都不是白话,例如,纽约警察局官员会发送“信号13”来请求后备部队。
我们使用语音上下文定制词汇表。为适应领域,我们还扩充了一些词汇,例如,“assault”并不通俗,但常见于领域中,模型应检测出“assault”而不是“a salt”。
调整参数之后,我们能够在一些城市获得相对准确的转录。接下来,我们要使用音频片段的转录数据,找出哪些与市民相关。
基于转录和音频特征的二值分类器
我们建立了一个二进制分类问题的模型,其中转录作为输入,置信水平作为输出,XGBoost算法为数据集提供了最好的性能。
我们从一位前执法部门工作人员处了解到,在重大事件的无线电广播之前,一些城市会发出特殊警报音以引起当地警方的注意。这个“额外”的特征使我们的模型更加可靠,尤其是在转录出错的情况下。其他一些有用的特征是警察频道和传输ID。
我们在操作流程中对ML模型进行了测试。运行了几天后,我们注意到在事件中,那些只使用带了模型标记的片段的分析员未出差错。
我们在几个城市推出了这种模式。现在一个分析师可以同时处理多个城市的音频,这在以前是不可能的。随着投入运营的闲置产能增多,我们得以开发新的城市。
超越公共语音转文本引擎
这个模型并不是解决所有问题的灵丹妙药,我们只能在少数几个音质好的城市使用它。公共语音转文本引擎是按照声学剖面不同于收音机的音素模型训练的,因此,转录的质量有时是不可靠的。对于那些非常嘈杂的老式模拟系统来说,转录是完全不可用的。
我们尝试了多个来源的多个模型,但没有一个是按照与数据集相似的声学剖面训练的,全都无法处理嘈杂的音频。
我们试着用在保证管道其他部分不变的情况下由数据训练出的语音转文本引擎,替换原语音转文本引擎。然而,为了音频,我们需要几百小时的转录数据,而生成这些数据耗时耗财。
我们还有个优化过程的选择,就是只抄写词汇表中定义为“重要”的单词,并为不相关的单词添加空格,但这仍然只是在逐步减少工作量而已。最后,我们决定为问题领域建立一个定制的语音处理管道。
用于关键词识别的卷积神经网络
因为我们只关心关键字,所以并不需要知道单词正确的顺序,由此可简化问题为关键字识别。这就简单多了,我们决定使用在数据集上训练的卷积神经网络(CNN)。
在循环神经网络(RNNs)或长短期记忆(LSTM)模型之上使用卷积神经网络(CNN)意味着我们可以更快地训练和重复。我们评估了Transformer模型,其大致相同,但需要大量硬件才能运行。
由于我们只在音频段之间寻找短期的依赖关系来检测单词,计算简单的CNN似乎优于Transformer模型,同时它能腾出硬件空间,从而可以通过超参数调整更加灵活。
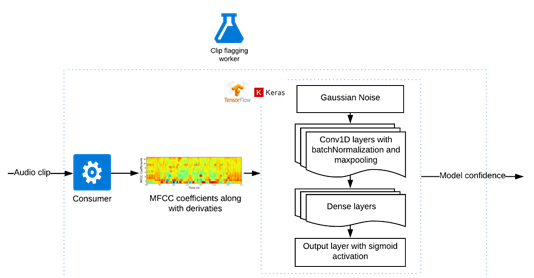
用于识别关键字并运用了卷积神经网络的剪辑标记模型(图自作者)
音频片段会被分成固定时长的子片段。如果词汇表中的一个单词出现了,该子片段会被加上一个正标签。然后,如果在某个片段中发现任何这样的子片段,该音频片段会被标记为有用。
在训练过程中,我们尝试改变子片段的时长以判断其如何影响融合性能。长的片段让模型更难确定片段的哪个部分会有用,也让模型更难调试。短片段意味着部分单词会出现在多个剪辑中,这使得模型更难识别出它们。调整这个超参数并找到一个合理的时长是能做到的。
对于每个子片段,我们将音频转换成梅尔倒谱系数(MFCC),并添加一阶和二阶导数,特征以25ms的帧大小和10ms的步幅生成。然后,通过Tensorflow后端输入到基于Keras序列模型的神经网络中。
第一层是高斯噪声,这使得模型耐得住不同无线信道之间的噪声差异。我们尝试了另一种方法,人为地将真实的噪音叠加到片段上,但这大大放缓了训练,却没有显著的性能提升。
然后,我们添加了Conv1D、BatchNormalization和MaxPooling1D三个后续层。批处理规范化有助于模型收敛,最大池化有助于使模型耐得住语音和信道噪声的细微变化。另外,我们试着增加了脱落层,但这些脱落层并未有效改进模型。
最后,添加一个密集连接的神经网络层,将其注入到一个有着sigmoid函数激活的单一输出密集层。
生成标记数据
音频剪辑的标记过程(图自作者)
为了标记训练数据,我们把问题领域的关键字列给了注释者,并要求他们如果有词汇表里的单词出现,必须为片段标记好开始和结束位置和单词标签。
为了确保注释的可靠性,我们在注释器之间有10%的重叠,并计算了它们在重叠片段上的表现。一旦有了大约50小时的标记数据就会启动训练,我们会在重复训练的过程中不断收集数据。
由于词汇表中的一些单词比另一些单词更为常见,模型针对于普通单词来说表现正常,但是对于仅有较少示例的单词却遇到了困难。
我们试图将单字发音覆盖在其他片段中,借以人为制造示例。然而,性能的提升与这些单词的实际标记量不相称。最终,模型对于常用词等会更加敏感,我们在未被标记的音频片段上运行该模型,并消除掉那些含有已习得单词的片段,这有助于减少未来标记时多余的词语。
模型的发行
经过几次重复的数据收集和超参数调整,我们已能训练出一个对词汇表里的词语具有高查全率和精准捕捉能力的模型。高查全率对于捕捉关键的安全警报非常重要。标记的片段会在发送警报之前被收听,因此误报不是一个大问题。
我们在纽约市的一些区对这个模型进行了测试,该模型能够将音频音量降低50–75%(取决于频道),它明显超越了我们在公共语音转文本引擎上训练的模型,因为纽约由于模拟系统有非常嘈杂的音频。
令人惊讶的是,尽管模型是根据纽约市的数据训练的,但它也可以很好地切换到芝加哥的音频。在收集了几个小时的芝加哥片段之后,从纽约市模型中学到的东西转移到芝加哥,该模型也表现良好。
语音处理管道与定制的深度神经网络广泛适用于来自美国主要城市的警察音频。它从音频中发现了重大的安全事故,使全国范围的市民能够迅速向城市广播,履行保护社区安全的使命。
在RNN、LSTM或Transformer中选择计算简单的CNN架构,以及简化标记过程,这些都是重大的突破,使我们能在限时限材的情况下超越公共语音转文本模型。
责编AJX
-
MCU能否捕捉到稳定的低信号电平?2024-07-02 0
-
飞凌嵌入式-ELFBOARD 解决PCB布线时无法捕捉到焊盘中心的问题2024-09-10 0
-
[转帖]信息安全事故处理急救箱2010-03-16 0
-
安全事故频发,我们手上拿的是充电宝还是手雷?2014-08-29 0
-
机器视觉与铁路安全的未来-如何减少列车事故2015-12-01 0
-
cc2541怎样扫描才能捕捉到所有的广播包?2016-03-28 0
-
请问在28027中对ECAP功能,捕捉到下降沿的同时能否自动读取某一个32位定时器的计数值?2018-10-31 0
-
电厂人员定位系统帮助电厂减少安全事故2021-10-14 0
-
逻辑分析仪捕捉到的脉冲与常见的NEC协议捕捉到的脉冲有何不同2022-02-15 0
-
建筑施工安全事故的成因及预防2009-12-24 471
-
避免煤矿安全事故的系统2020-10-14 2584
-
大型语言模型能否捕捉到它们所处理和生成的文本中的语义信息2023-05-25 684
-
机器学习构建ML模型实践2023-07-05 672
-
如何正确的观察电流探头捕捉到的电流波形2023-08-23 671
-
如何正确的观察电流探头捕捉到的电流波形?2024-05-19 957
全部0条评论

快来发表一下你的评论吧 !
