

关于编程的那些事
描述
来自公众号:Java建设者
为什么这本书叫做 龙书(Dragon book)?
这本书很有意思,它的书名是 《Compilers: Principles, Techniques, and Tools》,也就是编译器的原则、技术和工具。但它却画出了一个恐龙和骑士,恐龙身上写的是 Complexity of Compiler Design,也就是复杂的编译器设计,骑士的盾上写的是 Syntax Directed Granslation,也就是语法翻译。骑士的剑上看的不是很清楚,我猜测应该是优秀的编译器的意思。这是征服复杂性的隐喻。优秀的编译器会直接征服复杂的编译,复杂的编译设计永远无法攻破语法翻译。
什么是编译原理
计算机是只认识二进制的,但是我们平常开发中根本不会使用二进制进行开发,我们使用的都是 Java、C 这类的高级语言,每种语言都会经过一系列的转换才能被计算机识别,那么到底是谁做的这项工作呢?一个被称为 编译器(compiler) 的大佬出场了。
语言处理器
首先考虑一下一个例子,你如何才能和老外对话?你是不是需要学英语?我们有一些同学可能认为英语难学,经常会在英语书上做一些汉语标记方便理解。
那么,谁做了由英语到方便记忆 的英语之间的转换呢?答案是你的大脑。所以,我们可以归纳一下这个过程。
因为我们懂汉语(自己的一套语法规则),我们把英语(需要学习的语言)转换为我们便于理解的汉语(大脑翻译规则),我们才能学会英语和老外对话(转换为目标语言)。
这里我说一点:昨天晚上外出遛狗有个老黑和中国女生对话,中国女生竟然讲英文??????这可是中国本土好么,为什么外国人来到中国不讲汉语偏要中国人讲英文???你去外国旅游你会讲中文吗???这是一个基本认知问题,别怪我偏执。我认为外国人要来我们国家最基本的一点就是:你要学中文,千万不要抱着英语为上的心态,汉语不输任何语言。
回到正题,我们上面举出的这个学英语的例子,其实就是一个由原程序经过某种机制转换,把它变成目标语言的过程。也就是
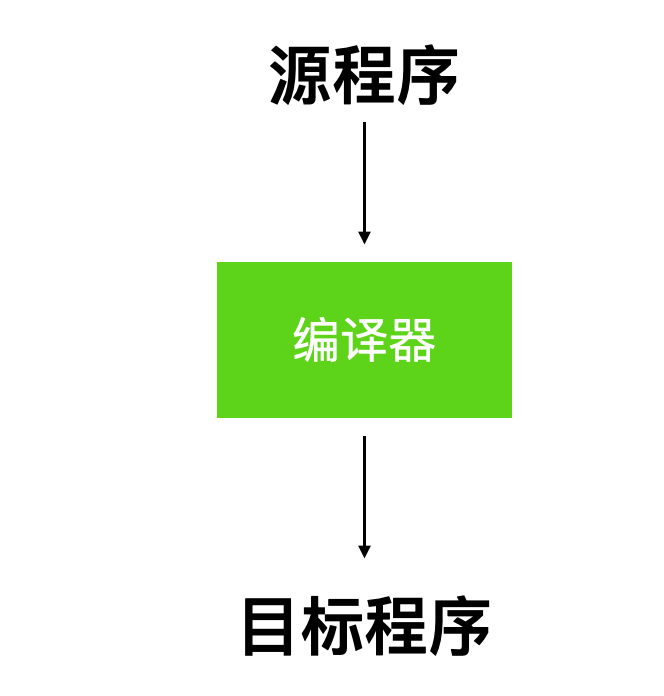
编译器就是一个翻译官的角色,它负责把源程序的语法翻译成目标程序能够理解的语法。
回到计算机中,我们肯定需要目标程序来做一些事情的。
也就是,我们通过某个渠道获得的输入信息,会经过编译器的转换,变为输出信息进行展示。

除了编译器之外,还有一种称为 解释器(interpreter) 的语言处理器,它不是做翻译工作的,而是把用户提供的输入执行源程序中指定的操作。

我们熟知的 Java 语言,就结合了编译和解释的过程,我们写的 Java 源文件首先被编译成 字节码(bytecode),字节码是一种中间码,它通常被看成是可执行的二进制文件。然后再由 Java 虚拟机对字节码解释执行。这样,在一台机器上编译的字节码就能够在其他机器上解释执行,这种体现了 Java 语言的平台无关性。

为了提高编译速度,Java 中有一种 just-in-time,JIT 即时编译器会一边编译一边执行。
一个源文件程序可能被划分为多个模块,并存放在多个文件中,还需要把文件链接在一起,所以,除了编译器之外,还需要一种能链接文件的部件参与,预处理器(preprossor) 是做这件事情的。如下图所示
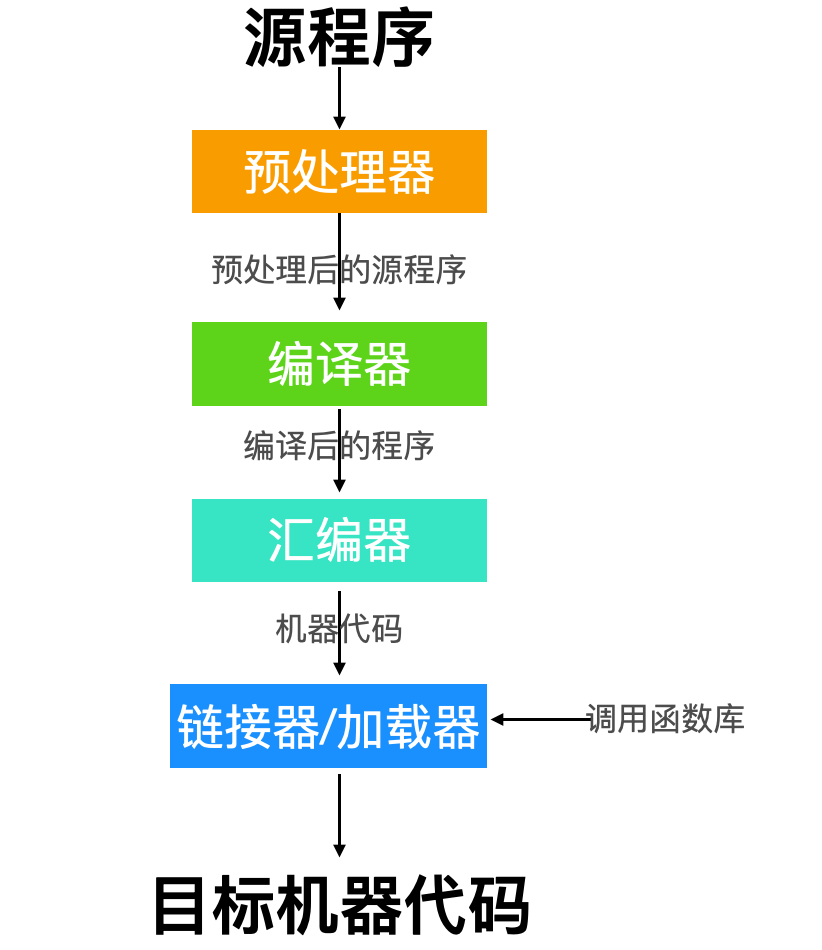
预处理器经过预处理后会作为输入传递给编译器,编译器对源程序进行编译,编译完成后生成汇编代码,作为汇编器的输入传递给汇编器,汇编器进行汇编处理转换为机器代码,注意这个时候还不是目标代码,还要经过链接器与系统库函数进行链接,最后由加载器把目标代码加载到内存中执行
编译器的结构
我们上面大概了解了一下语言的处理过程,下面我们就来了解一下编译器的内部结构,编译器内部其实具有两种结构:分析(analysis)部分和 整合(synthesis) 部分。
分析过程相当于是把源程序分成多个结构,每个结构都有特定的语法格式进行校验,在经由每个校验后,如果不满足指定的语法格式则进行提醒,使用户进行修改。分析部分还会收集有关源程序的信息,会把收集到的信息存放在一个被称为 符号表(symbol table) 的数据结构中。符号表和中间表示形式一起传给整合部分。
整合过程是根据分析过程传递的信息来构造用户期待的目标程序。分析和整合统称为 前端(front end) 和 后端(back end) ,哈哈哈哈。
这里你需要知道符号表(Symbol Table) 的概念:符号表是编译器使用和维护的数据结构,由标识符和类型组成。符号表的主要作用是帮助编译器快速定位。
下面是一个编译器的典型结构

下面我们就针对编译器结构的每一层进行描述和讨论
词法分析
词法分析(Lexical Analyzer)是编译器的第一个步骤,它也被称为 扫描(scanning)。词法分析器通过读入外部的字符流对其进行扫描,并且把它们组成有意义的词素(lexeme)序列,对于每个词素,词法分析器都会产生词法单元(token) 作为输出。这个词法单元会传递给下一个步骤,也就是语法分析。
这里需要解释一下 Token 、词素和词法分析器的概念
我们常用的编程语言就是具有词素的单词和符号的集合,比如 C 语言中有 (),-> 等等。关键字 if...while...,变量或函数名称以及数字和字符串常量也被视为词素。并不是所有的自负都属于词素,例如空格和注释就不属于。
词法分析器用来分析词素有两个规则
跳过不能以字母开头的字符
然后找到剩余的最长前缀,也就是词素
这两句话比较抽象,举个例子来说明一下
比如 C 语言中有这么一个语句
ifx = 20*30;
那么第一个词素就是 ifx,为什么不是 if 呢?因为 if 不是最长的前缀。然后后面的词素依次是 =,20,*,30和;。
词素、词法分析器、token 的关系如下
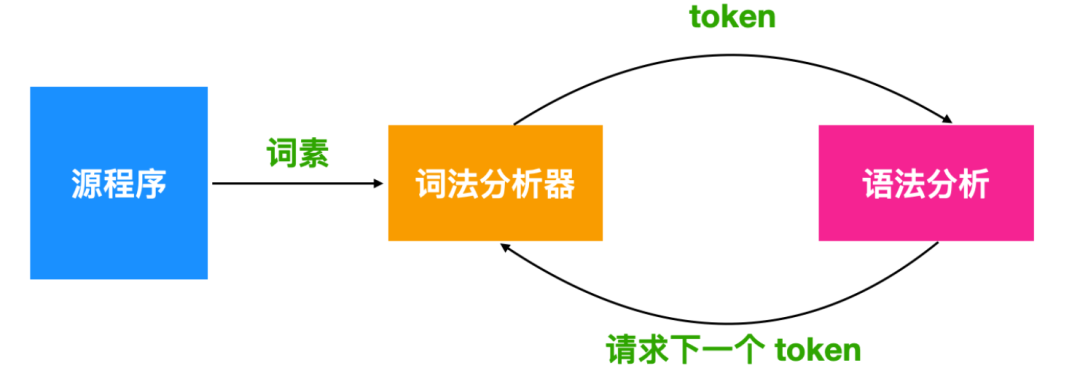
词素是 Token 的实例,词法分析器的主要任务就是从源程序中读取字符并产生 token。token 也是有结构的,一般结构如下

在词法分析生成的 token 中,第一个词 token-name 是语法分析期间使用的抽象符号,第二个词 attribute-value 指向的是符号表中关于这个词法单元的条目数。
我们举个例子来看一下词法分析的拆解过程。
比如现在源程序中有一个赋值语句
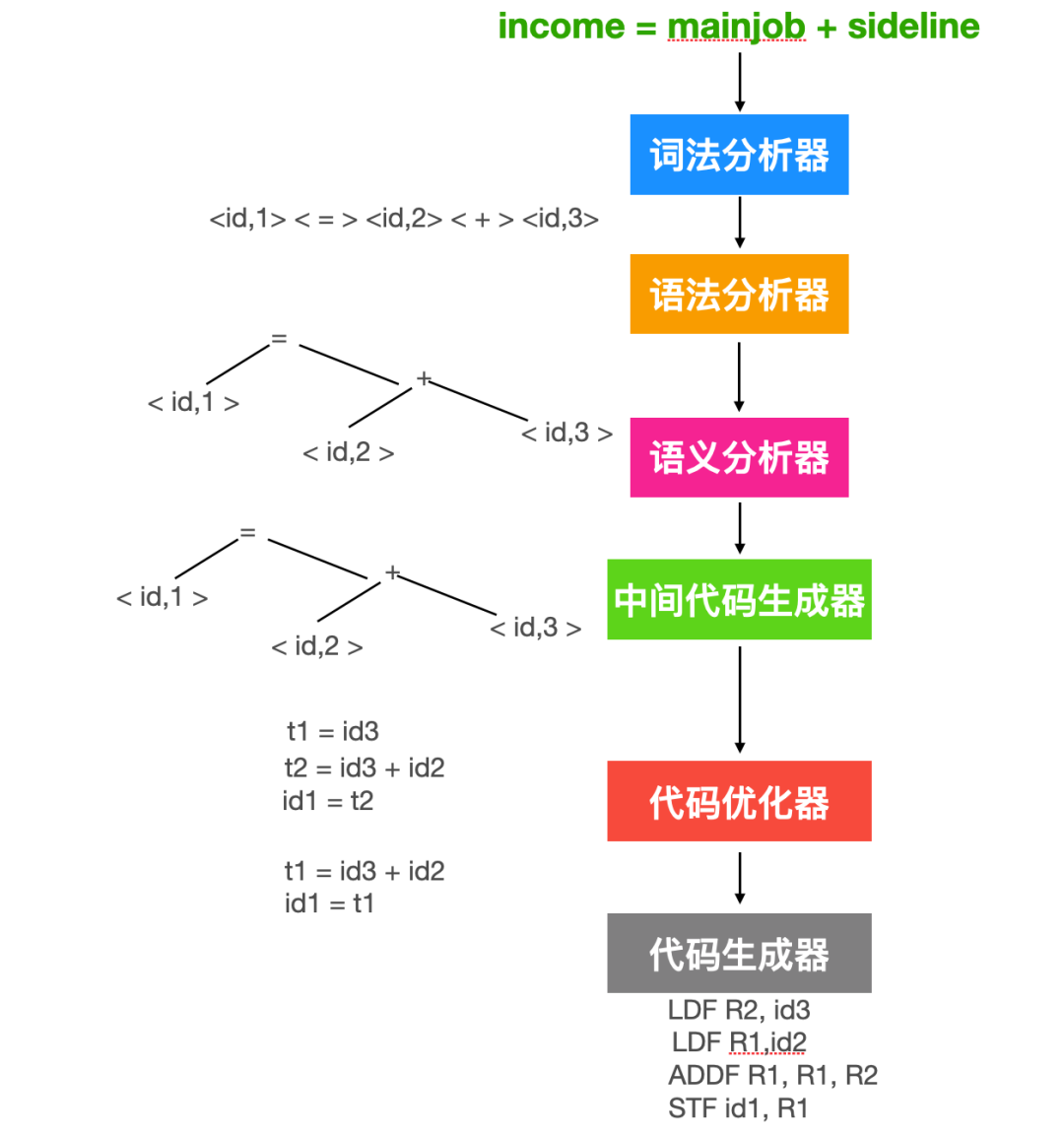
income = mainjob + sideline // 收入 = 主业 + 副业
这个赋值语句中的字符可以组合成如下词素,并转换成为 token,并传递给语法分析阶段。
首先,income 是一个词素,它会被映射为
然后是赋值符号 = ,它也是一个词素,被映射称为 token 中的 < = >。这个 token 不需要属性值,所以没有第二个词。
mainjob 是一个词素,它被映射成为 token 中的
+也是一个词素,它被映射称为 < + >,没有条目数
sideline 是一个词素,它被映射称为 token 中的
所以,经过词法分析后,上面的源程序会变为
在上面的表达式中, = 和 + 分别表示赋值和加法运算符的抽象符号。用图来表示的话就是
语法分析
编译器的第二个步骤是 语法分析(syntax analysis) 或者称为 解析(parsing)。语法分析器使用由词法分析器生成的各个词法单元的第一个分量来创建树形的中间表示。常用的方法就是 语法树(syntax tree)。编译器的后续步骤都会使用这个语法结构来帮助分析源程序,并生成目标程序。
语义分析
语义分析是由 语义分析器(semantic analyzer) 完成的,它使用语法树和符号表中的信息来检查源程序是否和语言定义的语义一致。语义分析器也收集类型信息,并把这些信息放在语法树或者符号表中,以便后续的中间代码生成器使用。
语义分析会进行类型检查(type checking),这是语义分析器的一个最重要的功能。编译器会检查每个运算符是否具有匹配的运算分量。举个例子比如设计语言要求一个数组的下标是整数,如果你用浮点数作为下标,编译器就会出错。
某些程序设计语言比如 Java 会允许自动类型转换(coercion)。如果整数和浮点数进行运算,编译器会把整数转换为浮点数。
中间代码生成
在源程序的语法分析和语义分析完成后,很多编译器生成一个明确的低级类机器语言的中间表示。我们可以把中间表示形式看作是抽象,中间形式的代码应该具有两个重要的性质:易于生成,并且能够轻松的被翻译。一般常用的一种是 三地址指令(three-address instructions)的中间表示形式。我们后面会细说。
代码优化
代码优化会试图改进代码以便生成更好的目标代码。更好通常情况下意味着更快,但是也可能会有其他目标,比如更短或能耗更低的目标代码。
代码生成
代码生成通过中间代码作为输入,并把它映射为目标语言。如果目标语言是机器代码的话,那么必须要为每个变量分配寄存器或内存位置。解释一下上面的运行结果。

每个指令的第一个运算分量指定了一个目标地址,各个指令中的 F 告诉我们它处理的是 浮点数, 上面代码首先把 id3 装载进 R2 寄存器中,然后把 id2 装载进 R1 寄存器中,再对 R1 目标进行 R1 和 R2 寄存器相加的操作。最后把寄存器 R1 的值存放到 id1 的地址中。
符号表管理
我们上面提到了符号表的概念,它是一个编译器很重要的功能。符号表能够记录源程序中使用变量的名称,并收集和每个名称相关的属性信息。它相当于一个秘书的作用。符号表还记录了每个变量名字的条目。后面我们会详细的介绍符号表。
编译器构造工具
和软件开发一样,写编译器的人可以充分利用现代的软件开发环境进行开发。通常也有 语言编辑器、调试工具、版本管理、测试工具等。除此之外,还需要一些更专业的工具来实现编辑器不同阶段的代码生成。
一些常用的编译器构造工具有
语法分析器生成器:可以根据程序设计语言的语法描述自动生成语法分析器
扫描器生成器:可以根据一个语言的语法单元的正则描述生成词法分析器
语法制导的翻译引擎:用于生成一组遍历分析树并生成中间代码
代码生成器:用于把中间代码转换为目标代码
数据流分析引擎:用于分析输入是如何传递到另一部分的
编译器构造工具:提供用于构造编译器不同阶段的例程
程序设计语言的发展历程
计算机从 20 世纪 40 年代创建至今都只能理解二进制语言,亘古不变。这个 0 、 1 组成的序列能够告诉计算机以什么样的顺序执行怎样的运算。运算本身是很底层的:比如把一个数据从一个位置进行移动;把两个寄存器的内容进行相加、比较两个值,为了避免如此枯燥的运算,我们开发了各种各样的编程语言,但是计算机底层的计算方式一直没变,所以学习哪个技术性价比高,明白了吗?下面我们就来一起认识一下程序设计语言的历程。
高级设计语言
首先被开发出来的是 20 世纪 50 年代的汇编语言,5 年后发生了重要的进步,用于科学计算的 Fortran 被开发出来,用于商业处理的 Cobol 语言和用于符号计算的 Lisp 语言被开发出来;然后接下来的时间,慢慢很多编程语言被开发出来,比如 C、C++、Java、JavaScript、Python 等。后面还有用于数据处理的 SQL 语言。

语言分类
说到给这些编程语言分类,那可是有太多了,不过我们专注一下高频的分类。
如何完成计算任务的语言称为 强制式(imperative)语言,而把程序中指明要进行哪些计算的语言称为 声明式(declarative)语言。C、C++、Java 这些都是强制式语言,它们能够改变程序的状态;声明式比如 HTML Prolog 等。
冯·诺伊曼 语言指的是以冯·诺伊曼计算机体系为基础的编程语言,今天很多编程语言都是冯·诺伊曼语言
面向对象语言(object-oriented language) 是一种描述对象的语言,比如 C、C++、Java
脚本语言(scripting language) 是具有高层次的解释型语言,它通常把多个过程粘在一起,比如 JavaScript、Perl、PHP、Python 等。
程序设计语言基础
下面我们主要探讨程序设计语言的研究中最重要的术语和它们的区别,假设读者已经了解过 C、C++、C#、Java 中任意一种语言。
静态和动态的区别
编译器需要能够对程序作出判定,如果语言能够让编译器静态(非运行)时候决定某个问题,那么我们说这个语言使用了一种 静态(static) 策略,或者说能够在 编译时刻(compile time) 决定。如果让编译器在运行时决定某个策略,那么就是动态策略(dynamic policy),或者被认为是 运行时决定(run time) 。
还有一个问题是声明的作用域(scope),如果能够通过阅读程序就能确定一个声明的作用域,那么这个语言就是静态作用域(static scope),或者说是 词法作用域(lexical scope)。否则这个语言使用的是 动态作用域(dynamic scope)。动态作用域的指向对象是几个声明中的一个,并不惟一。
C 和 Java 都使用了静态作用域,比如 Java 中的 static 关键字,下面是一段代码示例
public static int x;
这段代码在创建完成后就能够确定它的作用域,因为 static 声明的变量是类变量,类变量的实例能确保只有一个个(不太清楚的小伙伴可以参考我的这篇文章 都说变量有七八种,到底谁是 Java 的亲儿子)
如果你去掉了 static ,那么这个变量的作用域和在内存中的分配就无法确定,编译器无法在运行之前确定所有这些位置。
静态绑定和动态绑定
同样的,名字到位置也区分静态绑定和动态绑定,如果能在非运行条件下唯一确定名字到位置,那么就是静态绑定,如果要在程序运行时才能确定名字和位置的绑定,那么就是动态绑定。
静态作用域和块结构
大多数编程语言都提供了作用域这么一个结构,比如 Java 中的 private,protected,public 等关键字的使用,提供了有效的作用域控制。
块结构也是一种作用域,使用块结构表示的含义是在块内部(block) 作用范围有效,块使用 {} 来界定一个块。
这种语法允许在任意函数或者方法的内部嵌入一个块,这种嵌套结构也被称为 块结构(block structure)。
参数传递机制
参数传递机制主要描述的是形式参数和实际参数的关联。大多数编程语言都支持两种调用:值传递和 引用传递
值传递
在值传递(call-by-value) 中,会对实参求值或拷贝,这些值被放在属于被调用的形式参数的内存位置上,这种调用方式在 C 和 Java 中都会使用,值调用的结果是,实参本身不会改变。但是在 C 中,我们可以传递一个指针,使得变量的值能够被修改。
引用传递
在 引用传递(call-by-reference) 中,实际参数的地址作为相应的形式参数的值被传递给调用者。在被调用者的代码中使用形式参数,实现方法是沿着这个指针找到调用者指明的内存位置。因此,改变实际参数相当于改变了形式参数。
原文标题:为什么编译原理被称为龙书?
文章出处:【微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
-
关于MOS管应用的那些事2014-10-08 29146
-
关于色温不同“性格”的那些事2017-05-06 3708
-
pH计和电导率仪那些事2018-11-05 14630
-
半导体材料那些事2019-07-29 6681
-
关于CPU那些你不得不知道事2021-03-08 1645
-
自动焊锡机那些你不知道的事2021-05-11 2313
-
关于GPS定位的那些事不看肯定后悔2021-09-26 6539
-
深入了解电路噪声的那些事2016-09-27 1102
-
关于 STM32 时钟配置的那些坑2020-03-08 7411
-
关于DPU的那些事2021-10-13 4241
-
舵机控制那些事(附STM32代码!!!)2021-12-08 1160
-
小科普|聊聊网线那些事2023-07-26 2673
-
说说EEPROM和FLASH的那些事2023-08-10 2018
-
有关于MLCC(多层陶瓷电容)替代Film Cap (薄膜电容)的那些事2023-12-04 4583
-
京准时钟科普:关于北斗卫星同步时钟的那些事?2024-10-29 1489
全部0条评论

快来发表一下你的评论吧 !
