

如何利用卫星图像对储油罐的体积进行估计
电子说
描述
在1957年以前,地球上只有一颗天然卫星:月球。1957年10月4日,苏联发射了世界上第一颗人造卫星,从那时起,来自40多个国家大约有8900颗卫星发射升空。
这些卫星可以帮助我们进行监视、通信、导航等等。国家可以利用卫星监视另一个国家的土地及其动向,估计其经济和实力,然而所有的国家都互相隐瞒着他们的信息。同理,全球石油市场也并非完全透明,几乎所有的产油国都在努力隐藏着自己的总产量、消费量和储存量,各国这样做是为了间接地向外界隐瞒其实际经济,并增强其国防系统的能力,这种做法可能会对其他国家造成威胁。出于这个原因,许多初创公司,如Planet和Orbital Insight,都通过卫星图像来关注各国的此类活动。通过收集储油罐的卫星图像来估算石油储量。但问题是,如何仅凭卫星图像来估计储油罐的体积呢?首先第一个条件是储油罐为浮顶油罐,因为只有这样,卫星才能检测到。这种特殊类型的油罐是专门为储存大量石油产品而设计的,如原油或凝析油,它由顶盖组成,直接位于油的顶部,随着油箱中油量的增加或下降,并在其周围形成两个阴影。如下图所示,阴影位于北侧

(外部阴影)是指储罐的总高度,而储罐内的阴影(内部阴影)表示浮顶的深度,体积可估计计算为1-(内部阴影区域/外部阴影区域)。在本文,我们将使用Tensorflow2.x框架,在卫星图像的帮助下,使用python从零开始实现一个完整的模型来估计储油罐的占用量。GitHub仓库本文的所有内容和整个代码都可以在这个github存储库中找到https://github.com/mdmub0587/Oil-Storage-Tank-s-Volume-Occupancy以下是本文目录。我们会逐一探索。目录
问题陈述、数据集和评估指标
现有方法
相关研究工作
有用的博客和研究论文
我们的贡献
探索性数据分析(EDA)
数据扩充
数据预处理、扩充和TFRecords
基于YoloV3的目标检测
储量估算
结果
结论
今后的工作
参考引用
1.问题陈述、数据集和评估指标
问题陈述:利用卫星图像进行浮顶油罐的检测和储油量的估算,然后将图像块重新组合成具有储油量估计的全图像。数据集:数据集链接:https://www.kaggle.com/towardsentropy/oil-storage-tanks该数据集包含一个带注释的边界框,卫星图像是从谷歌地球(google earth)拍摄的,它包含有世界各地的工业区。数据集中有2个文件夹和3个文件,让我们逐一看看。large_images: 这是一个文件夹,包含100个卫星原始图像,每个大小为4800x4800,所有图像都以id_large.jpg格式命名。Image_patches: Image_patches目录包含从大图像生成的512x512大小的子图,每个大的图像被分割成100个512x512大小的子图,两个轴上的子图之间有37个像素的重叠,生成图像子图的程序以id_row_column.jpg格式命名**labels.json:**它包含所有图像的标签。标签存储为字典列表,每个图像对应一个字典,不包含任何浮顶罐的图像将被标记为“skip”,边界框标签的格式为边界框四个角的(x,y)坐标。labels_coco.json: 它包含与前一个文件相同的标签的COCO标签格式。在这里,边界框的格式为[x_min, y_min, width, height].**large_image_data.csv:**它包含大型图像文件的元数据,包括每个图像的中心坐标和海拔高度。评估指标:对于储油罐的检测,我们将使用每种储油罐的平均精度(Average Precision,AP)和各种储油罐的mAP(Mean Average Precision,平均精度)来作为评估指标。浮顶罐的估计容积没有度量标准。mAP 是目标检测模型的标准评估指标。mAP 的详细说明可以在下面的youtube播放列表中找到https://www.youtube.com/watch?list=PL1GQaVhO4f_jE5pnXU_Q4MSrIQx4wpFLM&v=e4G9H18VYmA
2.现有方法
Karl Keyer [1]在他的存储库中使用RetinaNet来完成储油罐探测任务。他从头开始创建模型,并将生成的锚框应用于该数据集,他的研究使得浮顶罐的平均精度(AP)达到76.3%,然后他应用阴影增强和像素阈值法来计算它的体积。据我所知,这是互联网上唯一可用的方法。
3.相关研究工作
Estimating the Volume of Oil Tanks Based on High-Resolution Remote Sensing Images [2]:这篇文章提出了一种基于卫星图像的油罐容量/容积估算方法。为了计算一个储油罐的总容积,他们需要储油罐的高度和半径。为了计算高度,他们使用了与投影阴影长度的几何关系,但是计算阴影的长度并不容易,为了突出阴影使用了HSV(即色调饱和度值)颜色空间,因为通常阴影在HSV颜色空间中具有高饱和度,然后采用基于亚像素细分定位(sub-pixel subdivision positioning)的中值法来计算阴影长度,最后利用Hough变换算法得到油罐半径。在本文的相关工作中,提出了基于卫星图像的建筑物高度计算方法。
4.有用的博客和研究论文
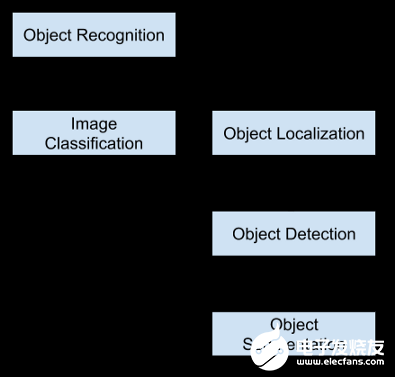
A Beginner’s Guide To Calculating Oil Storage Tank Occupancy With Help Of Satellite Imagery [3]:本博客作者为TankerTracker.com,其中的一项工作是利用卫星图像跟踪几个感兴趣的地理位置的原油储存情况。在这篇博客中,他们详细描述了储油罐的外部和内部阴影如何帮助我们估计其中的石油含量,还比较了卫星在特定时间和一个月后拍摄的图像,显示了一个月来储油罐的变化。这个博客给了我们一个直观的知识,即如何估计量。A Gentle Introduction to Object Recognition With Deep Learning [4] :本文会介绍对象检测初学者头脑中出现的最令人困惑的概念。首先,描述了目标分类、目标定位、目标识别和目标检测之间的区别,然后讨论了一些最新的深度学习算法来展开目标识别任务。对象分类是指将标签分配给包含单个对象的图像,而对象定位是指在图像中的一个或多个对象周围绘制一个边界框,目标检测任务结合了目标分类和定位。这意味着这是一个更具挑战性/复杂的任务,首先通过本地化技术在感兴趣对象(OI)周围绘制一个边界框,然后借助分类为每个OI分配一个标签。目标识别是上述所有任务的集合(即分类、定位和检测)。
最后,本文还讨论了两种主要的目标检测算法/模型:Region-Based Convolutional Neural Networks (R-CNN)和You Only Look Once (YOLO)。Selective Search for Object Recognition [5]:在目标检测任务中,最关键的部分是目标定位,因为目标分类是在此基础上进行的,它依赖于定位所输出的目标区域(简称区域建议)。更完美的定位可以实现更完美的目标检测。选择性搜索是一种新兴的算法,在一些物体识别模型中被用于物体定位,如R-CNN和Fast-R-CNN。该算法首先使用高效的基于图的图像分割方法生成输入图像的子段,然后使用贪婪算法将较小的相似区域合并为较大的相似区域。分段相似性基于颜色、纹理、大小和填充四个属性。
Region Proposal Network — A detailed view[6]:RPN(Region-proposition Network)由于其比传统选择性搜索算法更快而被广泛地应用于目标定位,它从特征图中学习目标的最佳位置,就像CNN从特征图中学习分类一样。它负责三个主要任务,首先生成锚定框(每个特征映射点生成9个不同形状的锚定框),然后将每个锚定框分类为前景或背景(即是否包含对象),最后学习锚定框的形状偏移量以使其适合对象。Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[7]:Faster R-CNN模型解决了前两个相关模型(R-CNN和Fast R-CNN)的所有问题,并使用RPN作为区域建议生成器。它的架构与Fast R-CNN完全相同,只是它使用了RPN而不是选择性搜索,这使得它比Fast R-CNN快34倍。

Real-time Object Detection with YOLO, YOLOv2, and now YOLOv3 [8]:在介绍Yolo系列模型之前,让我们先看一下首席研究员约瑟夫·雷德曼在Ted演讲上的演讲。https://youtu.be/Cgxsv1riJhI这个模型在对象检测模型列表中占据首位的原因有很多,然而,最主要的原因是它的牢固性,它的推理时间非常短,这是为什么它很容易匹配视频的正常速度(即25fps)并应用于实时数据的原因。
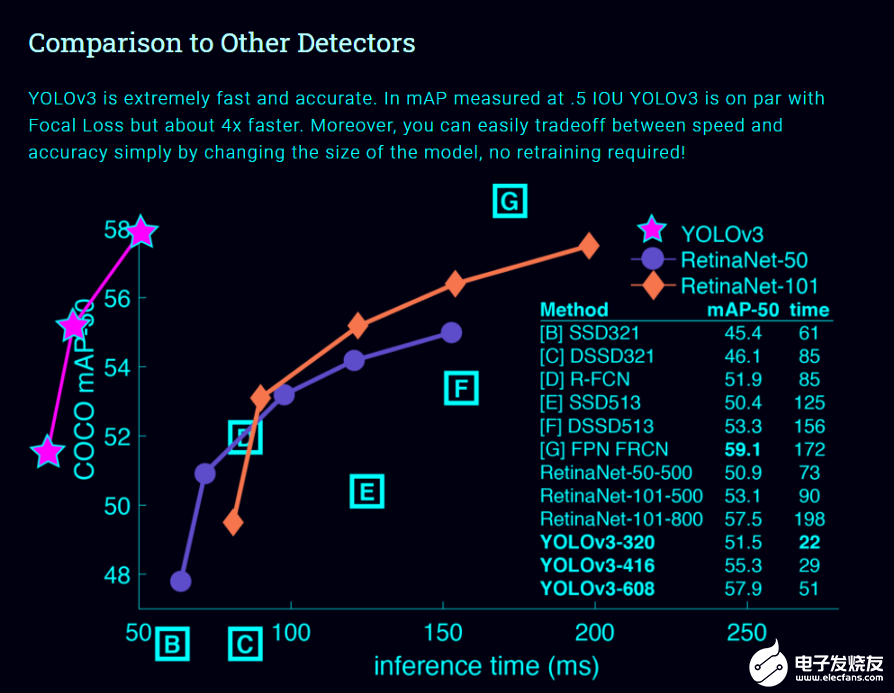
与其他对象检测模型不同,Yolo模型具有以下特性。单神经网络模型(即分类和定位任务都将从同一个模型中执行):以一张照片作为输入,直接预测每个边界框的边界框和类标签,这意味着它只看一次图像。由于它对整个图像而不是图像的一部分执行卷积,因此它产生的背景错误非常少。YOLO学习对象的一般化表示。在对自然图像进行训练和艺术品测试时,YOLO的性能远远超过DPM和R-CNN等顶级检测方法。由于YOLO具有高度的通用性,所以当应用于新的域或意外的输入时,它不太可能崩溃。是什么让YoloV3比Yolov2更好。如果你仔细看一下yolov2论文的标题,那就是“YOLO9000: Better, Faster, Stronger”。yolov3比yolov2更好吗?答案是肯定的,它更好,但不是更快更强,因为体系的复杂性增加了。Yolov2使用了19层DarkNet架构,没有任何残差块、skip连接和上采样,因此它很难检测到小对象,然而在Yolov3中,这些特性被添加了,并且使用了在Imagenet上训练的53层DarkNet网络,除此之外,还堆积了53个卷积层,形成了106个卷积层结构。
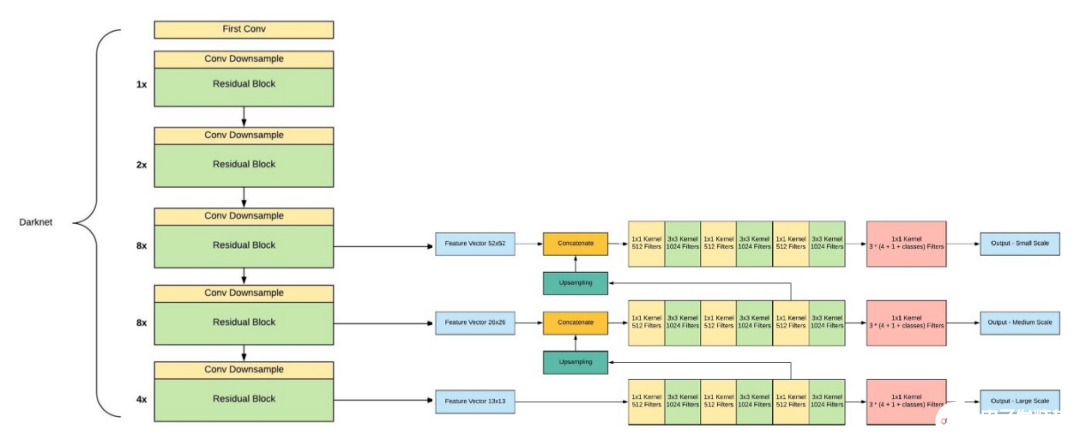
Yolov3在三种不同的尺度上进行预测,首先是大对象的13X13网格,其次是中等对象的26X26网格,最后是小对象的52X52网格。YoloV3总共使用9个锚箱,每个标度3个,用K均值聚类法选出最佳锚盒。Yolov3可以对图像中检测到的对象执行多标签分类,通过logistic回归预测对象置信度和类预测。
5.我们的贡献
我们的问题陈述包括两个任务,第一个是浮顶罐的检测,另一个是阴影的提取和已识别罐容积的估计。第一个任务是基于目标检测,第二个任务是基于计算机视觉技术。让我们描述一下解决每个任务的方法。储罐检测:我们的目标是估算浮顶罐的容积。我们可以为一个类建立目标检测模型,但是为了减少一个模型与另一种储油罐(即其他类型储油罐)的混淆,并使其具有鲁棒性,我们提出了三个类别的目标检测模型。使用带有转移学习的YoloV3进行目标检测是因为它更容易在机器上训练,此外为了提高度量分值,还采用了数据增强的方法。阴影提取和体积估计:阴影提取涉及许多计算机视觉技术,由于RGB颜色方案对阴影不敏感,必须先将其转换成HSV和LAB颜色空间,我们使用(l1+l3)/(V+1) (其中l1是LAB颜色空间的第一个通道值)的比值图像来增强阴影部分。然后,通过阈值0.5×t1+0.4×t2(其中t1是最小像素值,t2是平均值)来过滤增强图像,再对阈值图像进行形态学处理(即去除噪声、清晰轮廓等)。最后,提取出两个储油罐的阴影轮廓,然后根据上述公式估算出所占用的体积。这些想法摘自以下Notebook。https://www.kaggle.com/towardsentropy/oil-tank-volume-estimation遵循整个流程来解决这个案例研究如下所示。
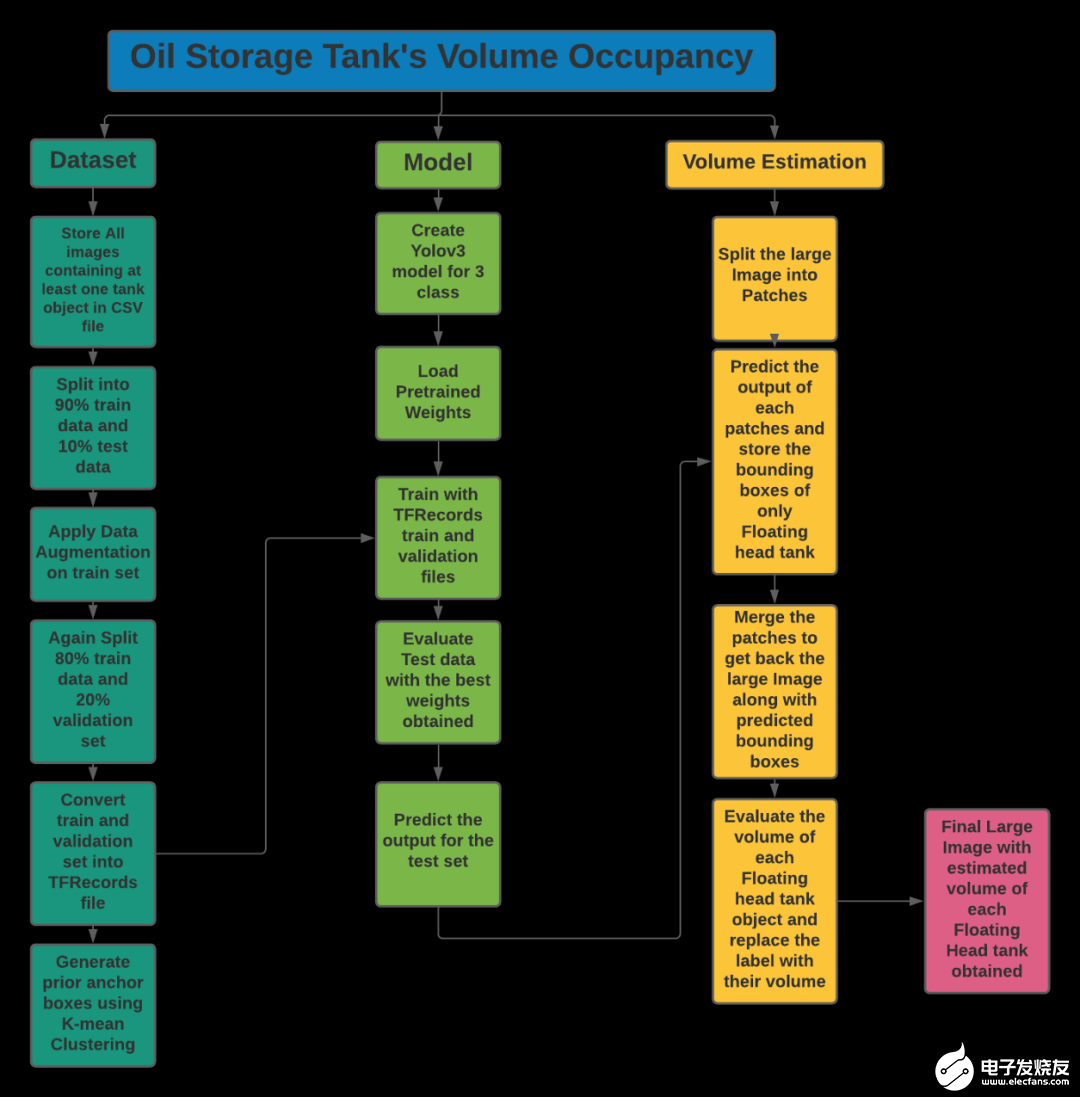
让我们从数据集的探索性数据分析EDA开始吧!!
6.探索性数据分析(EDA)
探索Labels.json文件:json_labels = json.load(open(os.path.join('data','labels.json')))
print('Number of Images: ',len(json_labels))
json_labels[25:30]
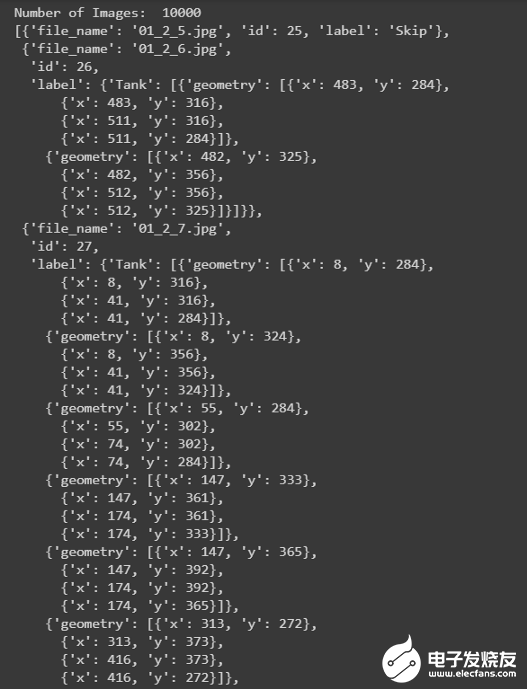
所有的标签都存储在字典列表中,总共有10万张图片。不包含任何储罐的图像将标记为Skip,而包含储罐的图像将标记为tank、tank Cluster或Floating Head tank,每个tank对象都有字典格式的四个角点的边界框坐标。计数:
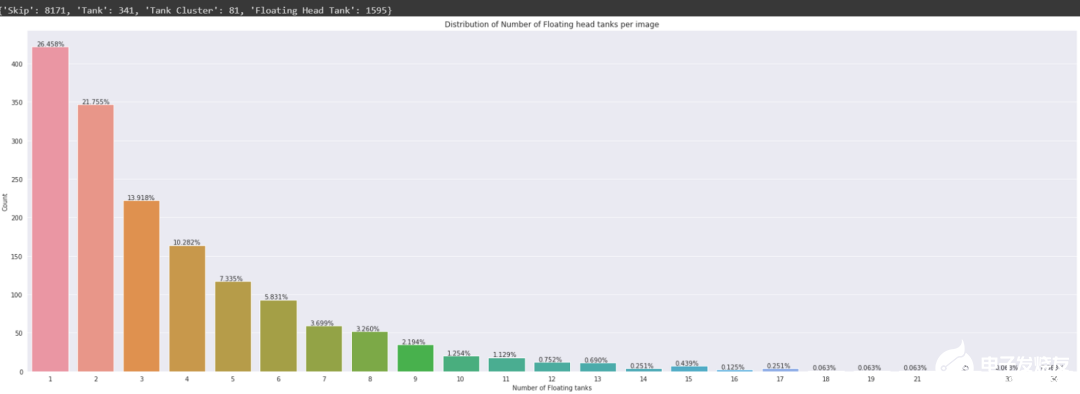
在10K个图像中,8187个图像没有标签(即它们不包含任何储油罐对象,此外有81个图像包含至少一个储油罐簇对象,1595个图像包含至少一个浮顶储油罐。在条形图中,可以观察到,在包含图像的1595个浮顶罐中,26.45%的图像仅包含一个浮顶罐对象,单个图像中浮顶储罐对象的最高数量为34。探索labels_coco.json文件:json_labels_coco = json.load(open(os.path.join('data','labels_coco.json')))
print('Number of Floating tanks: ',len(json_labels_coco['annotations']))
no_unique_img_id = set()
for ann in json_labels_coco['annotations']:
no_unique_img_id.add(ann['image_id'])
print('Number of Images that contains Floating head tank: ', len(no_unique_img_id))
json_labels_coco['annotations'][:8]
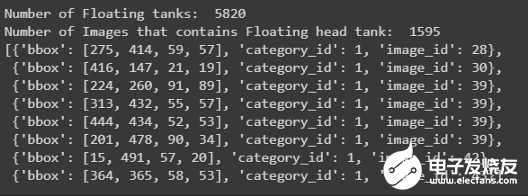
此文件仅包含浮顶罐的边界框及其在字典格式列表中的image_id打印边界框:
储油罐有三种:Tank(T 油罐)Tank Cluster(TC 油罐组),Floating Head Tank(FHT,浮顶罐)
7.数据扩充
在EDA中,人们观察到10000幅图像中有8171幅是无用的,因为它们不包含任何对象,此外1595个图像包含至少一个浮顶罐对象。众所周知,所有的深度学习模型都需要大量的数据,没有足够的数据会导致性能的下降。因此,我们先进行数据扩充,然后将获得的扩充数据拟合到Yolov3目标检测模型中。
8.数据预处理、扩充和TFRecords
数据预处理:对象的注释是以Jason格式给出的,其中有4个角点,首先,从这些角点提取左上角点和右下角点,然后属于单个图像的所有注释及其对应的标签都保存在CSV文件的一行列表中。从角点提取左上角点和右下角点的代码def conv_bbox(box_dict):
"""
input: box_dict-> 字典中有4个角点
Function: 获取左上方和右下方的点
output: tuple(ymin, xmin, ymax, xmax)
"""
xs = np.array(list(set([i['x'] for i in box_dict])))
ys = np.array(list(set([i['y'] for i in box_dict])))
x_min = xs.min()
x_max = xs.max()
y_min = ys.min()
y_max = ys.max()
return y_min, x_min, y_max, x_max
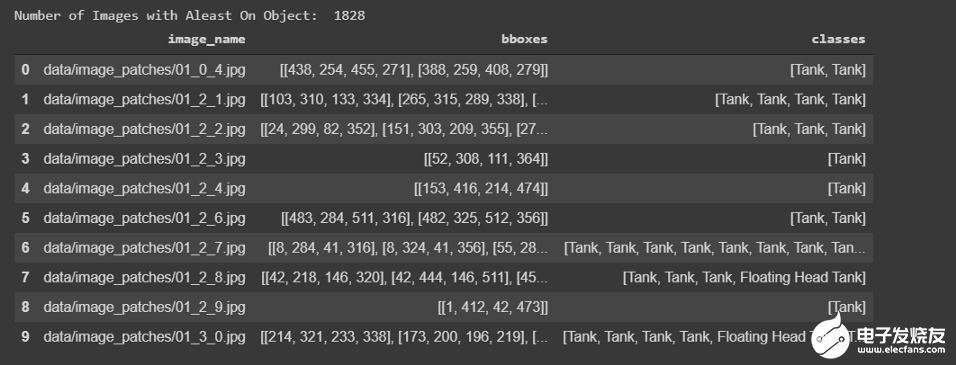
CSV文件将如下所示
为了评估模型,我们将保留10%的图像作为测试集。# 训练和测试划分
df_train, df_test= model_selection.train_test_split(
df, #CSV文件注释
test_size=0.1,
random_state=42,
shuffle=True,
)
df_train.shape, df_test.shape
数据扩充:我们知道目标检测需要大量的数据,但是我们只有1645幅图像用于训练,这是非常少的,为了增加数据,我们必须执行数据扩充。我们通过翻转和旋转原始图像来生成新图像。我们转到下面的GitHub存储库,从中提取代码进行扩充https://blog.paperspace.com/data-augmentation-for-bounding-boxes/通过执行以下操作从单个原始图像生成7个新图像:水平翻转旋转90度旋转180度旋转270度水平翻转和90度旋转水平翻转和180度旋转水平翻转和270度旋转示例如下所示
TFRecords:TFRecords是TensorFlow自己的二进制存储格式。当数据集太大时,它通常很有用。它以二进制格式存储数据,并对训练模型的性能产生显著影响。二进制数据复制所需的时间更少,而且由于在训练时只加载了一个batch数据,所以占用的空间也更少。你可以在下面的博客中找到它的详细描述。https://medium.com/mostly-ai/tensorflow-records-what-they-are-and-how-to-use-them-c46bc4bbb564也可以查看下面的Tensorflow文档。https://www.tensorflow.org/tutorials/load_data/tfrecord我们的数据集已转换成RFRecords格式,但是我们没有必要执行此任务,因为我们的数据集不是很大,如果你感兴趣,可以在我的GitHub存储库中找到代码。
9.基于YoloV3的目标检测
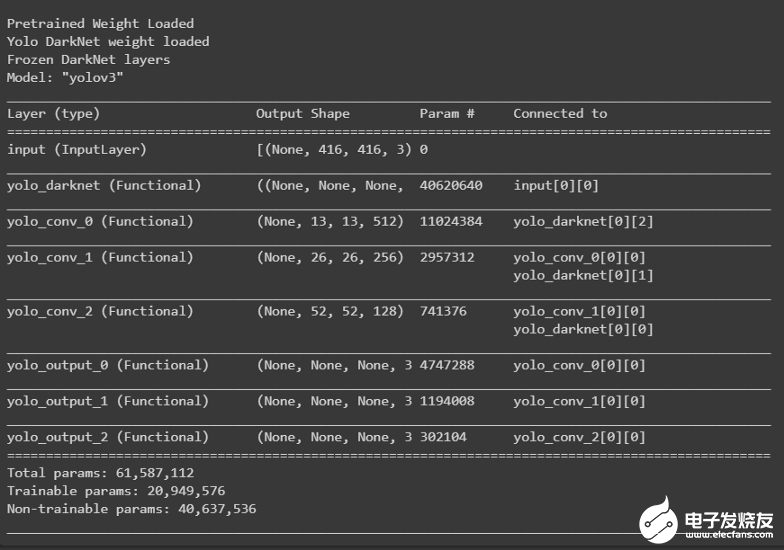
训练:为了训练yolov3模型,采用了迁移学习。第一步包括加载DarkNet网络的权重,并在训练期间冻结它以保持权重不变。def create_model():
tf.keras.backend.clear_session()
pret_model = YoloV3(size, channels, classes=80)
load_darknet_weights(pret_model, 'Pretrained_Model/yolov3.weights')
print('Pretrained Weight Loaded')
model = YoloV3(size, channels, classes=3)
model.get_layer('yolo_darknet').set_weights(
pret_model.get_layer('yolo_darknet').get_weights())
print('Yolo DarkNet weight loaded')
freeze_all(model.get_layer('yolo_darknet'))
print('Frozen DarkNet layers')
return model
model = create_model()
model.summary()
我们使用adam优化器(初始学习率=0.001)来训练我们的模型,并根据epoch应用余弦衰减来降低学习速率。在训练过程中使用模型检查点保存最佳权重,训练结束后保存最后一个权重。tf.keras.backend.clear_session()
epochs = 100
learning_rate=1e-3
optimizer = get_optimizer(
optim_type = 'adam',
learning_rate=1e-3,
decay_type='cosine',
decay_steps=10*600
)
loss = [YoloLoss(yolo_anchors[mask], classes=3) for mask in yolo_anchor_masks]
model = create_model()
model.compile(optimizer=optimizer, loss=loss)
# Tensorbaord
! rm -rf ./logs/
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
%tensorboard --logdir $logdir
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
callbacks = [
EarlyStopping(monitor='val_loss', min_delta=0, patience=15, verbose=1),
ModelCheckpoint('Weights/Best_weight.hdf5', verbose=1, save_best_only=True),
tensorboard_callback,
]
history = model.fit(train_dataset,
epochs=epochs,
callbacks=callbacks,
validation_data=valid_dataset)
model.save('Weights/Last_weight.hdf5')
损失函数:
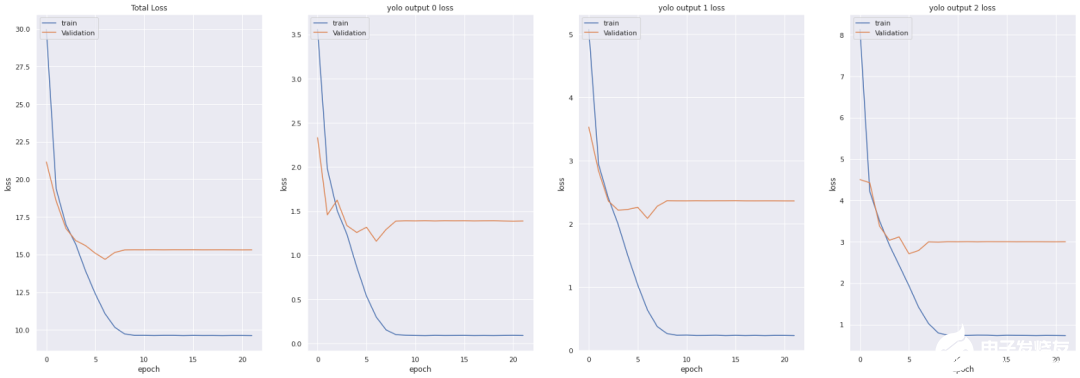
YOLO损失函数:Yolov3模型训练中所用的损失函数相当复杂。Yolo在三个不同的尺度上计算三个不同的损失,并对反向传播进行总结(正如你在上面的代码单元中看到的,最终损失是三个不同损失的列表),每个loss都通过4个子函数来计算检测损失和分类损失。中心(x,y) 的MSE损失.边界框的宽度和高度的均方误差(MSE)边界框的二元交叉熵得分与无目标得分边界框多类预测的二元交叉熵或稀疏范畴交叉熵让我们看看Yolov2中使用的损失公式
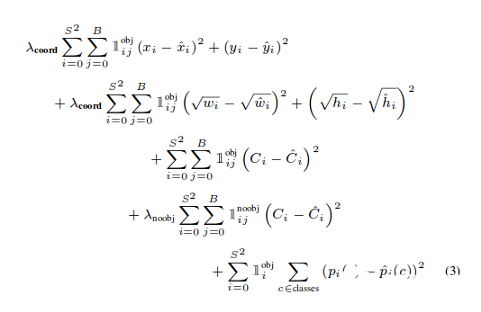
Yolov2中的最后三项是平方误差,而在Yolov3中,它们被交叉熵误差项所取代,换句话说,Yolov3中的对象置信度和类预测现在通过logistic回归来进行预测。看看Yolov3损失函数的实现def YoloLoss(anchors, classes=3, ignore_thresh=0.5):
def yolo_loss(y_true, y_pred):
# 1. 转换所有预测输出
# y_pred: (batch_size, grid, grid, anchors, (x, y, w, h, obj, ...cls))
pred_box, pred_obj, pred_class, pred_xywh = yolo_boxes(
y_pred, anchors, classes)
# predicted (tx, ty, tw, th)
pred_xy = pred_xywh[..., 0:2] #x,y of last channel
pred_wh = pred_xywh[..., 2:4] #w,h of last channel
# 2. 转换所有真实输出
# y_true: (batch_size, grid, grid, anchors, (x1, y1, x2, y2, obj, cls))
true_box, true_obj, true_class_idx = tf.split(
y_true, (4, 1, 1), axis=-1)
#转换 x1, y1, x2, y2 to x, y, w, h
# x,y = (x2 - x1)/2, (y2-y1)/2
# w, h = (x2- x1), (y2 - y1)
true_xy = (true_box[..., 0:2] + true_box[..., 2:4]) / 2
true_wh = true_box[..., 2:4] - true_box[..., 0:2]
# 小的box要更高权重
#shape-> (batch_size, grid, grid, anchors)
box_loss_scale = 2 - true_wh[..., 0] * true_wh[..., 1]
# 3. 对pred box进行反向
# 把 (bx, by, bw, bh) 变为 (tx, ty, tw, th)
grid_size = tf.shape(y_true)[1]
grid = tf.meshgrid(tf.range(grid_size), tf.range(grid_size))
grid = tf.expand_dims(tf.stack(grid, axis=-1), axis=2)
true_xy = true_xy * tf.cast(grid_size, tf.float32) - tf.cast(grid, tf.float32)
true_wh = tf.math.log(true_wh / anchors)
true_wh = tf.where(tf.logical_or(tf.math.is_inf(true_wh),
tf.math.is_nan(true_wh)),
tf.zeros_like(true_wh), true_wh)
# 4. 计算所有掩码
#从张量的形状中去除尺寸为1的维度。
#obj_mask: (batch_size, grid, grid, anchors)
obj_mask = tf.squeeze(true_obj, -1)
#当iou超过临界值时,忽略假正例
#best_iou: (batch_size, grid, grid, anchors)
best_iou = tf.map_fn(
lambda x: tf.reduce_max(broadcast_iou(x[0], tf.boolean_mask(
x[1], tf.cast(x[2], tf.bool))), axis=-1),
(pred_box, true_box, obj_mask),
tf.float32)
ignore_mask = tf.cast(best_iou < ignore_thresh, tf.float32)
# 5.计算所有损失
xy_loss = obj_mask * box_loss_scale *
tf.reduce_sum(tf.square(true_xy - pred_xy), axis=-1)
wh_loss = obj_mask * box_loss_scale *
tf.reduce_sum(tf.square(true_wh - pred_wh), axis=-1)
obj_loss = binary_crossentropy(true_obj, pred_obj)
obj_loss = obj_mask * obj_loss +
(1 - obj_mask) * ignore_mask * obj_loss
#TODO:使用binary_crossentropy代替
class_loss = obj_mask * sparse_categorical_crossentropy(
true_class_idx, pred_class)
# 6. 在(batch, gridx, gridy, anchors)求和得到 => (batch, 1)
xy_loss = tf.reduce_sum(xy_loss, axis=(1, 2, 3))
wh_loss = tf.reduce_sum(wh_loss, axis=(1, 2, 3))
obj_loss = tf.reduce_sum(obj_loss, axis=(1, 2, 3))
class_loss = tf.reduce_sum(class_loss, axis=(1, 2, 3))
return xy_loss + wh_loss + obj_loss + class_loss
return yolo_loss
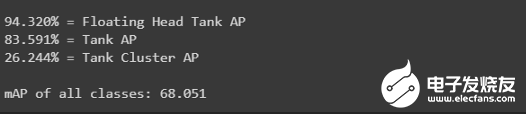
分数:为了评估我们的模型,我们使用了AP和mAP来评估训练和测试数据测试集分数get_mAP(model, 'data/test.csv')

训练集分数get_mAP(model, 'data/train.csv')
推理:让我们看看这个模型是如何执行的
10.储量估算
体积估算是本案例研究的主要内容。虽然没有评估估计容积的标准,但我们试图找到图像的最佳阈值像素值,以便能够在很大程度上检测阴影区域(通过计算像素数)。我们将使用卫星拍摄到的4800X4800形状的大图像,并将其分割成100个512x512的子图,两个轴上的子图之间重叠37像素。图像修补程序在id_row_column.jpg命名。每个生成的子图预测都将存储在一个CSV文件中,然后再估计每个浮顶储油罐的体积(代码和解释以Notebook格式在我的GitHub存储库中提供)。最后,将所有的图像块和边界框与标签合并,输出估计的体积,形成一个大的图像。你可以看看下面的例子:
11.结果
测试集上浮顶罐的AP分数为0.874,训练集上的AP分数为0.942。
12.结论
只需有限的图像就可以得到相当好的结果。数据增强工作得很到位。在本例中,与RetinaNet模型的现有方法相比,yolov3表现得很好。
13.今后的工作
浮顶罐的AP值为87.4%,得分较高,但我们可以尝试在更大程度上提高分数。我们将尝试生成的更多数据来训练这个模型。我们将尝试训练另一个更精确的模型,如yolov4,yolov5(非官方)。
责任编辑:gt
-
卫星图像智能合成系统全面解析2025-08-27 791
-
基于卫星图像的智能定位系统软件2025-04-01 1289
-
基于卫星图像的智能定位系统全面解析2025-03-31 1199
-
基于DTU储油罐在线监测系统,防患于未然2022-07-29 1384
-
储油罐液位/温度在线监测系统介绍2021-08-09 2323
-
储油罐监测系统的主要功能特点及应用设计2020-12-22 2405
-
基于YoloV3对卫星图像进行储油罐容积占用率的研究2020-12-10 1095
-
将Web技术与现场总线技术结合实现网络储油罐群远程监控系统的设计2018-12-07 3467
-
油罐液位高精度网络测量系统2011-03-09 2624
-
储油罐罐底板全面腐蚀控制方法2010-03-20 930
-
超声波液位计在原油储油罐中的应用2010-01-11 1029
-
如何巧判半地下储油罐接地装置断开故障2009-08-08 1012
-
基于Web的网络储油罐群远程监控系统研究2009-06-29 606
-
储油罐液位测控系统设计2009-02-10 1702
全部0条评论

快来发表一下你的评论吧 !
