

匿名和去识别化在数据隐私保护方面的重要性
电子说
描述
匿名化是为了确保数据的隐私性,公司用它来保护敏感数据。这类数据包括:
私人数据
业务信息,如财务信息或商业秘密
机密信息,如军事机密或政府信息
匿名化为遵循个人数据相关隐私条例提供了范例,个人数据和业务数据的重合之处就是客户信息所在。但并非所有的业务数据都受监管,本文将重点讨论个人数据的保护。
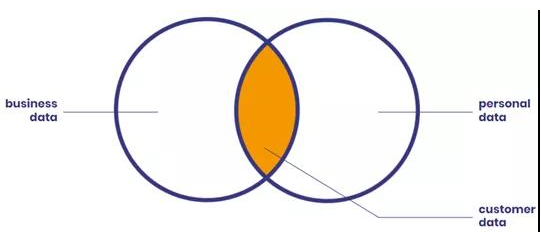
敏感数据类型示例
在欧洲,监管机构将任何与某人(如你的名字)有关的信息定义为“个人数据”。不论形式,任何关联到此人的信息都符合上述定义。从上世纪起,个人数据收集逐渐民主化,数据匿名化问题开始出现。随着隐私条例在世界各地开始生效,这件事尤显重要。
什么是数据匿名化,为何要关注它?
我们从经典定义开始。欧盟的《通用数据保护条例》(GDPR)是这样定义对匿名信息的:“与识别或可识别自然人无关的信息,或以数据主体不能或不再可识别的方式匿名提供的个人信息。”
其中,“可识别”和“不再”至关重要。这不仅意味着你的名字不应再出现在数据中,也意味着不能从剩余数据中发现你是谁,这与再认同(有时也叫去匿名化)过程有关。
同样,GDPR(契约中)陈述了一个重要事实:“……因此,数据保护不应适用于匿名信息”。所以,若你设法匿名数据,就不再受GDPR数据保护法的约束。
你可以执行任何处理操作,如分析或数据货币化。这带来了大量机会:
出售数据显然是首选用途。在世界各地,隐私保护法正在限制个人数据交易,而匿名数据为公司提供了另一种选择。
它带来了合作机会。许多公司为了创新或研究而共享数据,匿名数据有助于降低风险。
它还为数据分析和机器学习创造了机会。在保持兼容性的同时运行敏感数据的操作正变得越来越复杂,匿名数据为统计分析和模型训练提供了安全的原材料,前景一片光明。但实际上真正的匿名数据往往并不如愿。
数据隐私保护机制的范围
数据的隐私保护有一个范围。多年来,专家们研发了一系列集方法、机制和工具为一体的技术。这些技术生成了具有不同的匿名级别和不同再识别风险等级的数据。可以说,其范围涵盖了个人可识别数据乃至真正的匿名数据。
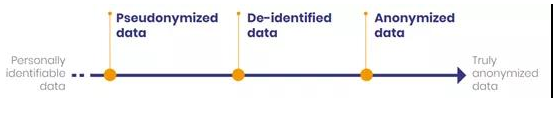
数据隐私的范围
左端,有包含直接个人识别码的数据。通过这些元素,可以识别你的姓名、地址或电话号码。另一端,则是GDPR引用的匿名数据。
如你所见,这些数据有一个中间范畴。它处于可识别数据和匿名数据之间,即假名数据和去识别数据。请注意,其界定仍有争议。有些报告认为假名化是去识别化的一部分, 而另一些报告则将其排除在外。
生成这种“中间数据”的技术本身并无问题。它们能有效地将数据最小化。根据用例需求,它们将彼此关联,发挥用处。但切记,它们无法生成真正的匿名数据,它们的机制无法保证阻止再识别,所以将其生成的数据称为“匿名数据”是一种误导。
匿名和“匿名”
假名化和去识别化确实能在某些方面保护数据隐私。但根据GDPR的定义,它们无法生成匿名数据。
假名化技术从数据中删除或替换直接个人标识码,例如,从数据集中删除所有名称和电子邮件,你无法直接从假名数据中识别某人,不过可以间接识别。实际上,剩余数据通常会保留间接识别码,组合这些信息后,就能创建直接识别码,如出生日期,邮编,性别等。
就此而言,假名化在GDPR框架中有一个单独定义:“……以以下方式处理个人数据,即在不使用附加信息的情况下,数据不再可以归因于特定数据主体”。与匿名数据相反,假名数据符合GDPR的要求。
去识别化技术从数据中去除直接和间接的个人身份识别码。理论上,去识别化数据和匿名化数据之间的界限很简单。最新消息表明:有技术可保障永远无法再识别数据。这是一种“疑罪从无”的情况,去识别化数据在未识别之前是匿名的。每当专家设法重新识别那些最初未识别出的数据时,他们都进一步推动了发展。
数据重新识别不断重新定义匿名
上述机制类型对隐私保护没有同等效力,因此如何处理这些数据很重要。公司定期发布或出售他们声称“匿名”的数据,但当他们使用的方法不能保证“匿名”时,就会带来隐患。
众多事件表明,假名化数据这种隐私保护机制仍有缺陷。数据中的间接识别码会带来巨大的再识别风险。随着可用数据量的增长,相互参照数据集的机会也在增加:
1990年,麻省理工学院的研究生从去识别化医疗数据中重新确认了马萨诸塞州州长的身份,她将这些信息与公用人口普查数据相互参照来确定患者身份。
2006年,作为研究计划的一部分,美国在线公司(AOL)共享了去识别化搜索数据,研究人员能够将搜索查询与背后的个人联系起来。
2009年,作为比赛的一部分,网飞(Netflix)发布了一个匿名电影评级数据集,德克萨斯州的研究人员成功重新识别了用户。
同是2009年,研究人员仅利用公开信息就能预测出一个人的社会保险号。
最近研究表明,去识别化数据实际上可以被重新识别。比利时新鲁汶大学和伦敦帝国理工学院的研究人员发现:“使用15个人口统计属性,在任何数据集中,99.98%的美国人都能被正确地重新识别。”
另一项针对匿名手机数据的研究表明:“四个时空点就足以唯一识别95%的个体用户”。
技术日益进步,更多的数据正在被创建,研究人员正在努力划定去识别化数据和匿名数据之间的界限。2017年,研究人员发表论文称:“网络浏览历史只能通过公开数据链接到社交媒体上的个人资料。”
另一个令人担忧的问题是个人资料的泄露,越来越多的个人信息遭到泄露。ForgeRock消费者身份泄露报告预测,2020年的信息泄露数量将超过去年,仅美国,2020年第一季度就有超过16亿的客户记录被泄露。
分开处理的数据集无法重新识别,但与泄露数据结合起来,它会造成更大的威胁。哈佛大学的学生能够利用泄露的数据重新识别去识别化数据。
总之,那些我们所认为的“匿名数据”往往并不是真正的匿名数据。并非所有的数据净化方法都会生成真正的匿名数据。事事都各有优点,但没有一种能提供与匿名同等级别的隐私。随着数据量的不断增长,创建真正的匿名数据也越来越难,公司发布潜在可重新识别的个人数据的风险也在增加。
责编AJX
-
深度自然匿名化:隐私保护与视觉完整性并存的未来!2025-01-15 5205
-
康谋分享 | 数据隐私和匿名化:PIPL与GDPR下,如何确保数据合规?(二)2024-10-30 2699
-
蓝牙模块的安全性与隐私保护2024-06-14 2148
-
POE浪涌保护的重要性是什么?2022-01-14 2587
-
Python语言在AI、大数据方面的重要性2021-09-02 1208
-
基于节点分类的改进k度匿名隐私保护方法2021-05-26 917
-
欠压保护的重要性2021-03-03 4483
-
数据匿名化对隐私可以起保护作用吗2019-08-02 3089
-
移动轨迹数据去匿名化攻击方法2018-03-20 1223
-
多种社会网络图匿名化技术2018-01-10 919
-
匿名云存储隐私保护方案2018-01-08 1132
-
一种社交网络高效高精度去匿名化算法2017-12-18 1211
-
基于差分隐私的数据匿名化隐私保护模型2017-12-11 1377
-
基于模糊集的隐私保护模型2017-11-29 1167
全部0条评论

快来发表一下你的评论吧 !
