

MySQL数据库:如何操作禁止重复插入数据
电子说
描述
在MySQL进行数据插入操作时,总是会考虑是否会插入重复数据,之前的操作都是先根据主键或者唯一约束条件进行查询,有就进行更新没有就进行插入。代码反复效率低下。
新建表格

添加三条数据如下:
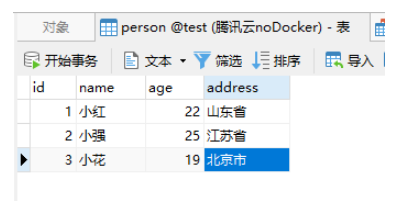
我们这边可以根据插入方式进行规避:
1. insert ignore
insert ignore 会自动忽略数据库已经存在的数据(根据主键或者唯一索引判断),如果没有数据就插入数据,如果有数据就跳过插入这条数据。
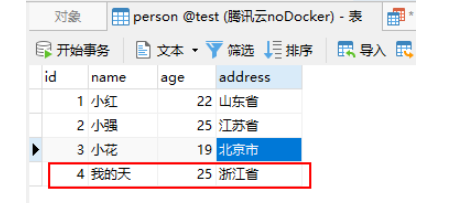
插入SQL如下: insert ignore into person (id,name,age,address) values(3,‘那谁’,23,‘甘肃省’),(4,‘我的天’,25,‘浙江省’);
再次查看数据库就会发现仅插入id为4的数据,由于数据库中存在id为3的数据所以被忽略。
2. replace into
replace into 首先尝试插入数据到表中, 1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据。
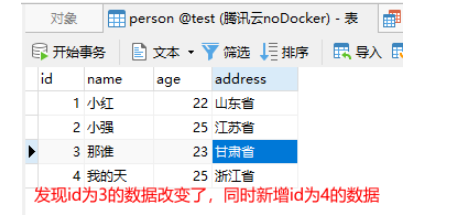
插入SQL如下: replace into person (id,name,age,address) values(3,‘那谁’,23,‘甘肃省’),(4,‘我的天’,25,‘浙江省’);
首先我们将表中数据恢复,然后进行插入操作后发现id为3的数据发生了改变同时新增了id为4的数据。
3. insert on duplicate key update
insert on duplicate key update 如果在insert into语句的末尾指定了on duplicate key update + 字段更新,则会在出现重复数据(根据主键或者唯一索引判断)的时候按照后面字段更新的描述对该信息进行更新操作。
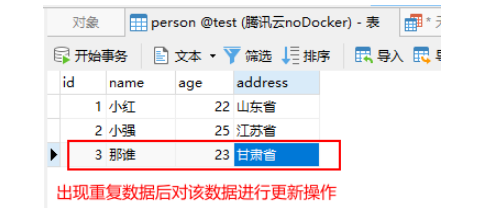
插入SQL如下: insert into person (id,name,age,address) values(3,‘那谁’,23,‘甘肃省’) on duplicate key update name=‘那谁’, age=23, address=‘甘肃省’;
首先我们将表中数据恢复,然后在进行插入操作时,发现id为3的数据发生了改变,进行了更新操作。
我们可以根据自己的业务需求进行方法的选择。
责编AJX
-
MySQL数据库的安装2025-01-14 1421
-
数据库数据恢复—Mysql数据库表记录丢失的数据恢复流程2024-12-16 1485
-
数据库数据恢复—MYSQL数据库ibdata1文件损坏的数据恢复案例2024-12-09 1523
-
数据库数据恢复—未开启binlog的Mysql数据库数据恢复案例2023-12-08 2330
-
mysql数据库基础命令2023-12-06 1672
-
mysql是一个什么类型的数据库2023-11-16 3300
-
MySQL数据库管理与应用2023-08-28 2059
-
有哪些不同的MySQL数据库引擎?2023-04-03 2386
-
华为云数据库-RDS for MySQL数据库2022-10-27 2604
-
LabVIEW操作MySQL数据库编程实例2022-10-13 1224
-
数据库插入查询删除操作教程2021-12-07 824
-
Mysql数据库的基本操作2020-06-08 2139
-
labview插入数据MySQL数据库2019-12-26 5528
-
MySQL数据库使用2019-10-24 1530
全部0条评论

快来发表一下你的评论吧 !
