

Linux kernel内存管理模块结构分析
存储技术
描述
1. 前言
内存(memory)在Linux系统中是一种牵涉面极广的资源,上至应用程序、下至kernel和driver,无不为之魂牵梦绕。加上它天然的稀缺性,导致内存管理(Memory Management,简称MM)是linux kernel中非常重要又非常复杂的一个子系统。
重要性就不多说了,Kernel自有分寸。关于复杂性(鉴于Linux kernel优秀的抽象能力),应该不会被普通人(Linux系统的使用者、应用工程师、驱动工程师、轻量级的内核工程师)感知到才对。事实确实如此,Kernel屏蔽掉了大多数的实现细节,尽量以简单、易用的方式向其它模块提供memory服务。
不过呢,这个世界上没有完美的存在,kernel的内存管理也是如此,由于两方面的原因:一、众口难调,内存管理有关的需求实在太复杂了;二、CPU、Device和Memory之间纠结的三角恋(参考下面图片),导致它也(不得不)提供了很多啰里啰唆的、不易理解的功能(困扰了很多从入门级到资深级的linux软件工程师)。
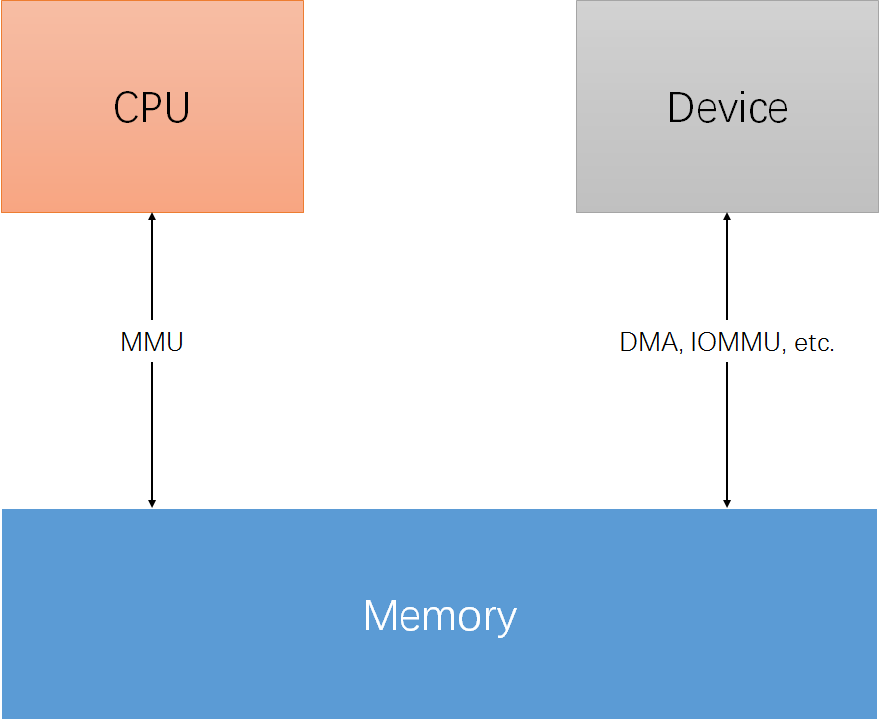
图片1 CPU, Device and Memory
基于上面的原因,本站内存管理子系统发布了很多分析文章,以帮助大家理解内存管理有关的概念。不过到目前为止,还缺少一篇索引类的文章,从整体出发,理解Kernel内存管理所需要面对的软硬件局面、所要解决的问题,以及各个内存管理子模块的功能和意义。这就是本文的目的。
2. 内存有关的需求总结
在嵌入式系统中,从需求的角度看内存,是非常简单的,可以总结为两大类(参考上面的图片1):
1)CPU有访问内存的需求,包括从内存中取指、从内存中取数据、向内存中写数据。相应的数据流为:
CPU<-------------->MMU(Optional)<----------->Memory
2)其它外部设备有访问内存的需求,包括从内存“读取”数据、向内存“写入”数据。这里的“读取”和“写入”加了引号,是因为在大部分情况下,设备不像CPU那样有智能,不具备直接访问内存的能力。总结来说,设备有三种途径访问内存:
a)由CPU从中中转,数据流如下(本质上是CPU访问内存):
Device<---------------->CPU<--------------------Memoryb)由第三方具有智能的模块(如DMA控制器)中转,数据流如下:
Device<----------->DMA Controller<--------->Memoryc)直接访问内存,数据流如下:
Device<---------->IOMMU(Optional)--------->Memory
那么Linux kernel的内存管理模块怎么理解并满足上面的需求呢?接下来我们将一一梳理。
3. 软件(Linux kernel内存管理模块)的角度看内存
3.1 CPU视角
我们先从CPU的需求说起(以当前具有MMU功能的嵌入式Linux平台为例),看看会向kernel的内存管理模块提出哪些需求。
⬛ 看到内存
关于内存以及内存管理,最初始的需求是:Linux kernel的核心代码(主要包括启动和内存管理),要能看到物理内存。
在MMU使能之前,该需求很容易满足。
但MMU使能之后、Kernel的内存管理机制ready之前,Kernel看到的是虚拟地址,此时需要一些简单且有效的机制,建立虚拟内存到物理内存的映射(可以是部分的映射,但要能够满足kenrel此时的需要)。
⬛ 管理内存
看到内存之后,下一步就是将它们管理起来。根据不同的内存形态(在物理地址上是否连续、是否具有NUMA内存、是否具有可拔插的内存、等等),可能有不同的管理模型和管理方法。
⬛ 向内核线程/用户进程提供服务
将内存管理起来之后,就可以向其它人(kernel的其它模块、内核线程、用户空间进程、等等)提供服务了,主要包括:
✓ 以虚拟地址(VA)的形式,为应用程序提供远大于物理内存的虚拟地址空间(Virtual Address Space)
✓ 每个进程都有独立的虚拟地址空间,不会相互影响,进而可提供非常好的内存保护(memory protection)
✓ 提供内存映射(Memory Mapping)机制,以便把物理内存、I/O空间、Kernel Image、文件等对象映射到相应进程的地址空间中,方便进程的访问
✓ 提供公平、高效的物理内存分配(Physical Memory Allocation)算法
✓ 提供进程间内存共享的方法(以虚拟内存的形式),也称作Shared Virtual Memory
✓ 等等
⬛ 更为高级的内存管理需求
欲望是无止境的,在内存管理模块提供了基础的内存服务之后,Linux系统(包括kernel线程和用户进程)已经可以正常work了,更为高级的需求也产生了,例如:
✓ 内存的热拔插(memory hotplug)
✓ 内存的size超过了虚拟地址可寻址的空间怎么办(high memory)
✓ 超大页(hugetlbpage)的支持
✓ 利用磁盘作为交换页以扩大可用内存(各种swap机制和算法)
✓ 在NUMA系统中通过移动物理页面位置的方法提升内存的访问效率(Page migration)
✓ 内存泄漏的检查
✓ 内存碎片的整理
✓ 内存不足时的处理(oom kill机制)
✓ 等等
3.2 Device视角
正常情况下,当软件活动只需要CPU参与时(例如简单的数学运算、图像处理等),上面3.1 所涉及内容已经足够了,无论是用户空间程序,还是内核空间程序,都可以欢快的运行了。
不过,当软件操作一些特殊的、可以以自己的方式访问memory的硬件设备的时候,麻烦就出现了:软件通过CPU视角获得memory,并不能直接被这些硬件设备访问。于是这些硬件设备就提出了需求:
内存管理模块需要为这些设备提供一些特殊的获取内存的接口,这些接口可以按照设备所期望的形式组织内存(因而可以被设备访问),也可以重新映射成CPU视角的形式,以便CPU可以访问。
这就是我们在编写设备驱动的时候会经常遇到的DMA mapping功能,其中DMA是Direct Memory Access的所需,表示(memory)可以被设备直接访问。
另外,在某些应用场景下,内存数据可能会在多个设备间流动,为了提高效率,不能为每个设备都提供一份拷贝,因此内存管理模块需要提供设备间内存共享(以及相互转换)的功能。
4. 软件结构
基于上面章节的需求,Linux kernel从虚拟内存(VM)、DMA mapping以及DMA buffer sharing三个角度,对内存进行管理,如下图所示:
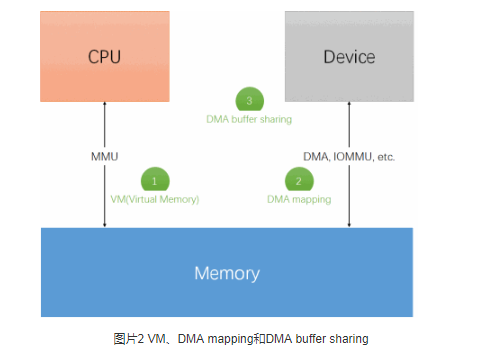
其中VM是内存管理的主要模块,也是我们通常意义上所讲的狭义“内存管理”,代码主要分布在mm/以及arch/xxx/mm/两个目录下,其中arch/xxx/mm/*提供平台相关部分的实现,mm/*提供平台无关部分的实现。
DMA mapping是内存管理的辅助模块,注要提供dma_alloc_xxx(申请可供设备直接访问的内存----dma_addr)和dma_map_xxx(是在CPU视角的虚拟内存和dma_addr之间转换)两类接口。该模块的具体实现依赖于设备访问内存的方式,代码主要分别在drivers/base/*(通用实现)以及arch/xxx/mm/(平台相关的实现)。
最后是DMA buffer sharing的机制,用于在不同设备之间共享内存,一般包括两种方法:
传统的、利用CPU虚拟地址中转的方法,例如scatterlist;
dma buffer sharing framework,位于drivers/dma-buf/dma-buf.c中。
有关这些模块的具体描述,本文后续的文章将会一一展开(有些已经有了),这里就先结束吧.
-
Linux 内存管理总结2023-11-10 1575
-
Linux中内存管理子系统开发必知的3个结构概念2023-08-28 1900
-
Linux内核的物理内存组织结构详解2023-08-21 1324
-
关于Linux内存管理的详细介绍2023-03-06 1540
-
走进Linux内存系统探寻内存管理的机制和奥秘2023-01-05 2626
-
深度解析Linux的内存管理体系2022-08-06 2524
-
基于RK3399的Linux kernel中CPU时钟管理介绍2022-06-21 4381
-
Linux的内存管理是什么,Linux的内存管理详解2022-05-11 7604
-
Linux内核结构详解2019-07-11 2205
-
你知道linux kernel内存碎片防治技术?2019-05-10 1451
-
U-boot传递RAM和Linux kernel读取RAM参数的解析2018-02-06 6632
-
linux内存管理2017-10-24 828
-
linux内存管理机制浅析2011-12-19 1068
-
Linux内存管理导读2011-11-03 732
全部0条评论

快来发表一下你的评论吧 !
