

通过利用数字信号处理器的体系结构特性提高编码效率
处理器/DSP
描述
作者:David Katz,Tomasz Lukasiak,Rick Gentile
数字信号处理器(DSP)在性能、外设、功耗和价格上已经结合得非常好了,许多系统工程师希望利用DSP的优势,取代传统设计方案中使用的处理器,但一个潜在难题是设计工程师已经为他们的应用开发了大量C和C++代码。很明显,工程师都愿意在DSP平台上利用现有的高级代码,同时利用DSP的体系结构特性以获得更好的性能。
HLL与汇编语言
当开发基于DSP的软件时,必须要做的一项工作就是确定使用哪一种程序设计方法学,通常是在汇编语言和高级语言(HLL)(例如C或C++语言)之间进行选择。
C和C++的优点包括模块性、便携性以及可重复利用性。
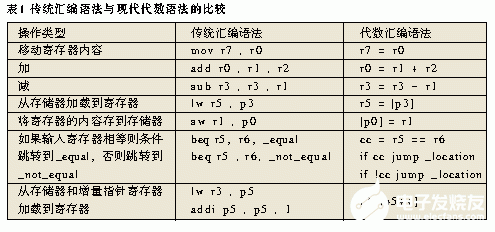
传统的汇编语言由于其语法和缩写难以理解和使用,长期以来不被人们所看好。目前的“代数语法”体系结构有了很大改进。表1是使用传统风格和使用代数格式的典型DSP指令实例,很显然后者的结构更加直观。在所提供的实例中,r寄存器是数据寄存器,p寄存器是指针寄存器。
用汇编语言编程困难的一个原因是由于其数据流集中在DSP实际寄存器组、计算单元和存储器之间。用C或C++语言编程,这种操作通常通过使用变量和函数,或过程调用出现在更加抽象的处理等级之间,从而使得代码更容易跟随。
为提高DSP执行效率,工具开发商会使用汇编语言对重要的数据密集代码模块进行优化。HLL编译优化转换可以很好地完成该项工作,而且对DSP数据流和计算的直接控制能力是极为出色的。这就是为什么设计工程师通常结合使用C/C++和汇编语言。HLL适合于控制和基本的数据操作,而汇编语言适合于高效的数字计算。
适合高效编程的体系结构的特性
为了使汇编语言程序员能够有效地完成工作,需要了解处理器的结构类型,以便能够区分不适合高速数字计算的那些DSP处理器。这些适合高效编程的体系结构结构特性包括:
● 专用寻址模式
● 硬件环路结构
● 高速缓冲存储器
● 每周期多次操作
● 互锁流水线
● 灵活的数据寄存器文挡
专用寻址模式
允许处理器在单周期内访问多个数据字需要灵活的地址产生方式。除了需要更大的以DSP为中心的16bit和32bit边界的访问尺寸外,还需要字节寻址以达到最有效的处理。这是非常重要的,因为一些普通应用(例如许多基于视频的系统)都是按照8bit数据操作。当处理器访问限制在单一边界内时,处理器可能需要额外的周期来掩蔽掉相关的位。
另外一种有利的寻址能力是“循环缓冲”。该特性必须直接由处理器支持,无须专门的软件管理开销。循环缓冲允许程序员定义存储器中的缓冲器,并且自动跨越它们。一旦缓冲器设置好,则无须专门的软件交互操作数据。地址发生器处理非同式跨幅,更重要的是可以处理图1所示的“环绕式”特性。如果没有这种自动地址产生功能,程序员必须手动跟踪缓冲器,从而浪费了宝贵的处理周期。
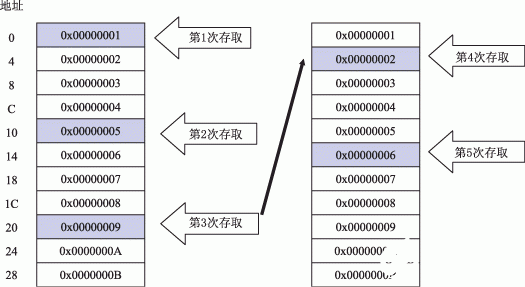
图1 环绕式缓冲的例子
在此例中,基地址和起始索引地址=0x0;索引地址寄存器I0指向地址0x0;缓冲器长度L=44(11个数据元素×4字节/元素);修改寄存器M0=16(4个数据元素×4字节/元素)
实例代码:
R0 = [I0++M0]; //R0 = 1,I0在代码执行后指向0x10
R1 = [I0++M0]; //R1 = 5,I0在代码执行后指向0x20
R2 = [I0++M0]; //R2 = 9,I0在代码执行后指向0x04
R3 = [I0++M0]; //R3 = 2,I0在代码执行后指向0x14
R4 = [I0++M0]; //R4 = 6,I0在代码执行后指向0x24
用于高效信号处理运算(例如快速傅立叶变换(FFT)和离散余弦变换(DCT))的一种重要寻址模式是比特翻转。顾名思义,“比特翻转”就是将二进制地址中的比特翻转,也就是说将权值最小的比特与权值最大的比特交换位置。由基为2的蝶形所要求的数据顺序是“已翻转比特”的顺序,因此比特翻转索引用来组合FFT级。可以计算软件中的这些比特翻转索引,但是这样做的效率非常低。图2所示是比特翻转地址流实例。
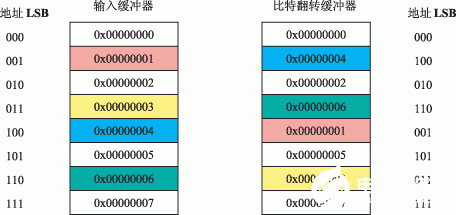
图2 硬件比特翻转机理
实例代码:
LSETUP(起始, 终止)LC0=P0; //循环数P0=8
起始:R0 = [I0] || I0 += M0(BREV); //I0指向输入缓冲器,在比特翻转过程中自动增加
终止:[I2++] = R0; ; //I2指向比特翻转缓冲器
硬件循环结构
循环在通信处理算法中是一项很重要的特性。有两个与循环有关的关键特性能够改进多种算法的性能。第一个特性称作“零开销硬件循环”。随着寻址能力的提高,循环结构可以在硬件中实现。此外,当该项功能用软件实现时,相关的开销可减小到实时处理预算。零开销循环允许程序员通过设置计数值并且定义循环边界初始化循环。处理器将继续执行循环直到计数结束。
零开销循环是大多数处理器必不可少的一部分,但“硬件循环缓冲器”实际上可以提高循环结构的性能。它们用作循环中所执行指令的一种高速缓冲存储器。例如,在第一次执行完一个循环之后,可将该指令保存在循环缓冲器中,从而无须在每一次循环都反复重取相同指令。通过将循环指令保存在能够在单周期内访问的缓冲器中,能够节省大量的周期数。该特性不需要程序员进行额外的设置,但是需要知道循环缓冲器的尺寸以合理地选择循环大小。
高速缓冲存储器
通常典型的DSP具有少量的快速、内置存储器。MCU通常可以访问大量的外部存储器。分层存储器体系结构将这两种方案的优点结合在一起,从而可提供几种等级具有不同性能的存储器。对于需要最高性能应用,可以在单个核心时钟周期内访问内置SRAM。对于具有大代码尺寸的系统,可提供大量、较长等待延迟的片内和片外存储器。
这种分层存储器体系结构本身仅仅是发挥一定的作用,由于现在的高性能处理器常常运行在较低的时钟频率下,因此大的应用程序只能装在较慢的外部存储器中。此外,程序员被迫手动将关键代码移入和移出内部SRAM。但是,通过将数据和指令高速缓冲存储器加到该体系结构中后,外部存储器更易于管理,高速缓冲存储器可以减少将指令和数据移入处理器内核的手工操作。由于不需要考虑进入内核的数据和指令流管理,可以大大简化编程模式。
指令高速缓存通常采用了某种类型的最近最少使用(LRU)算法,从而确保更常用的指令代替较少使用的指令。将一些内置数据存储器配置为高速缓存和部分SRAM的能力可以优化性能。直接存储器访问(DMA)控制器能够直接控制内核,同时当需要表中数据时将其读入数据高速缓存。一旦高速缓存允许并且DMA控制器配置完毕,则程序员即可集中精力于内核算法的开发。
每周期多次操作
通常以每秒执行多少百万条指令(MIPS)来衡量处理器。曾经被保留用在高成本并行处理器中的多发布指令目前也可用在低成本、定点处理器中。除了在每个核心处理器周期内完成多条ALU或MAC操作外,在相同周期内还可完成额外的数据处理和数据存储。存储器通常划分为子若干个存储器组,这些存储器组可以被内核双向访问并且被DMA控制器随机访问。鉴于上述的基于硬件的寻址算法的分解方法,很明显其可以在单个周期内完成许多操作。
图3示出多操作指令的一个实例。如图3所示,在一个周期内除了完成两条独立的MAC操作外,在相同的处理器时钟周期内还完成了数据读取和数据存储。
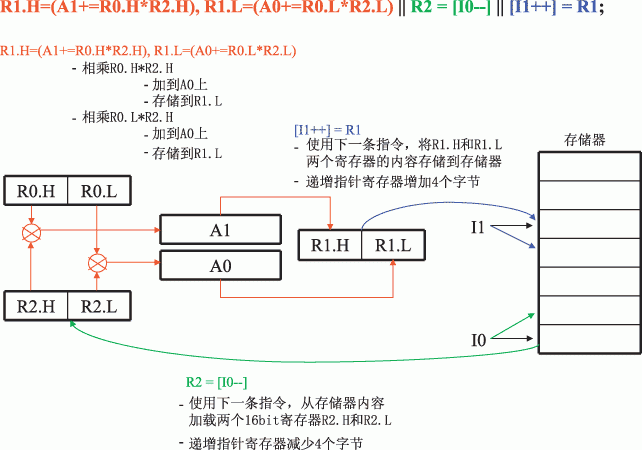
图3 Blackfin多发布指令在单周期内完成几次操作
互锁流水线
随着处理器速度的增加,从整个电路级来看处理流水线必定会变得更深。然而,有些处理器具有“互锁”流水线。这意味着当完成汇编语言编程时,程序员不必手动调度或跟踪通过流水线的数据和指令。处理器会自动处理这些时序的事情。
灵活的数据寄存器文档
最后,另外一个补充特性是通用数据寄存器集。在传统的定点DSP中,字长通常是固定的。然而,具有能够用作一个32bit(例如R0)或两个16bit(例如分别用于低8bit和高8bit的R0.L和R0.H)的数据寄存器是非常有利的。在双MAC系统中,这允许在单周期内操作四个16bit的数据。
内积
内积或者标量积在度量两个向量的正交性时是很有效的操作。大多数C语言程序员应该熟悉以下的内积操作: short dot(short a[], short b[], int size) {
int i;
int output = 0;
for(i=0; i }
return output;
下面是Blackfin处理器汇编代码的主要部分:
//P0=loop count, I0 & P1 are address registers
A1 = A0 = 0; // A0 & A1 are accumulators
LSETUP (loop1,loop1) LC0 = P0 ;// Setup hardware loop starting at label loop1:
loop1: A1 +=R1.H*R0.H, A0+=R1.L*R0.L||R1=[P1++]||R0=[I0++];
下面几点说明了简化这种紧凑编码的DSP体系结构特性。
硬件循环缓冲器和循环计数器在每次迭代的末端不需要跳转指令。由于内积是乘积总和,因此可在一次循环中完成。该汇编程序所示是LSETUP指令,它是执行循环所需的唯一指令。
多发布指令允许在相同的周期内执行多条指令和两次数据访问。在每一次迭代时,必须先读取a和b值,然后相乘,最后写回到可变输出的运行总和中。在许多MCU平台上,这实际上等于四条指令。汇编代码的最后一行示出在一个周期内可执行的所有操作。
并行ALU操作允许同时执行两条16bit指令。汇编代码示出在每次迭代中使用的两个累加器单元(A0和A1),这将迭代次数减少了50%,从而将原来的执行时间减少了一半。
FIR算法
有限脉冲响应(FIR)滤波器是一种等价于卷积操作很常见的滤波器结构。A通过C操作看起来非常类似于内积。
//将信号取样到循环缓冲器中
x[cur] = sampling_function();
cur = (cur+1)%TAPS; // 在循环中增加cur指针
//完成乘加
y = 0;
for (k=0; k }
使用汇编语言编写的FIR内核格式有些类似于内积。在这个特定的例子中,取样值存储在R0寄存器中,同时系数存储在R1寄存器中。
// P0 存有滤波器抽头
R0=[I0++] || R1=[I1++]; // 设置R0和R1的初始值
A1=A0=0; // 将累加器置零
LSETUP (loop1, loop1) LC0 = P0;//设置内部循环
loop1: A1+=R0.L*R1.L, A0+=R0.H*R1.H||R0=[I0++]||R1=[I1++]; //计算
除了具有所描述的用于内积的特性外,上面所示的FIR算法也可使用循环缓冲。
循环缓冲器不需要直接取余运算。在C代码片段中,%(取余)运算符可提供一种用于循环缓冲的机理。正如汇编内核中所示,这些取余运算符不能被编译为内循环中的其他指令。相反,数据地址发生器寄存器I0和I1可在外循环中配置,以便在循环到达系数缓冲器边界时能够自动返回起始处。
FFT算法
快速傅立叶变换(FFT)是许多信号处理算法不可缺少的一部分,其特点之一是输入向量按照连续时间顺序排列,但输出按比特翻转顺序排列。大多数传统的通用处理器要求程序员用单独的程序整理比特翻转输出。在DSP平台上,比特翻转可用于寻址引擎。
比特翻转寻址在实现FFT时不需要单独的比特翻转程序,允许硬件自动将FFT算法的输出进行比特翻转,无须程序员编写额外的程序,从而改进了性能。
除了上面所提到的指令外,有些处理器也包括额外一套专用指令以支持多种应用。提供这些指令的目的就是进一步提高对算法的处理能力,例如维特比算法、Huffman编码以及许多其他比特操作程序。
zrbj:gt
-
嵌入式微处理器体系结构 嵌入式微处理器原理与应用2024-05-04 4136
-
数字信号处理器概论2023-08-07 14874
-
嵌入式微处理器体系结构2021-11-08 2329
-
高级处理器特性能否提高编码效率?2021-04-26 1761
-
微处理器体系结构2021-04-12 1184
-
数字信号处理器的特点2020-12-09 2145
-
利用FPGA怎么实现数字信号处理?2019-10-17 6415
-
什么是数字信号处理器以及它的用处2019-08-26 5906
-
简单介绍数字信号处理器的特点2018-10-29 10803
-
浅谈ARM处理器的特点和体系结构2018-04-03 18553
-
数字信号处理器原理、结构及应用所附光盘2016-06-06 1280
-
嵌入式RISC处理器体系结构并行技术的研究2011-08-18 936
-
数字信号处理器(DSP)2010-01-04 3785
-
ARM微处理器体系结构2009-06-17 816
全部0条评论

快来发表一下你的评论吧 !
