

浅谈vhost的数据路径硬件化 DPDK中的vDPA实现方案
电子说
描述
vDPA就是VHOST DATA PATH ACCELERATION,即将vhost的数据路径硬件化,如下图所示。

只把data plane硬件化对于网卡厂商要相对容易实现,否则如果要求data plane和 control plane 都需要硬件支持,这就要求硬件的data ring layout需要和virtio一致,还需要 control plane的PCI bar和virtio spec一致,而硬件厂商通常有自己定制的pci bar。不过在智能网卡的裸金属服务器场景,厂商也在做full emulation,即控制面也相对硬件化的方案,我们这只讨论正常的data plane硬件化。
对于kernel的vDPA方案如下图所示。
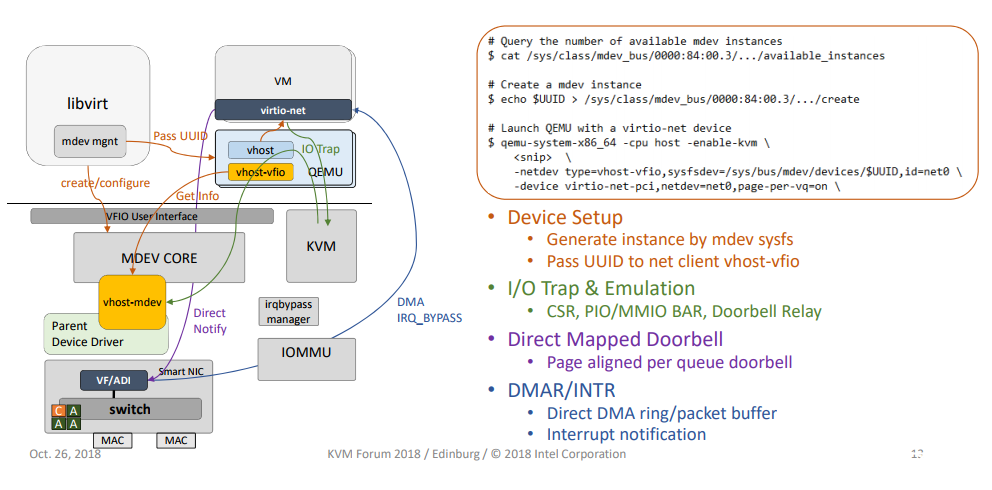
这里面有几个关键组件需要介绍一下。
vhost-mdev
在介绍vhost-mdev前需要先介绍virtio-mdev框架,说起virtio-mdev又不得不先讲vfio-mdev。
vfio-mdev
先快速对vfio的概念进行扫盲。这个扫盲的目的不是详细介绍什么是VFIO,而是给对没有vfio的读者一个入门的指引。
vfio是Linux Kernel UIO特性的升级版本。UIO的作用是把一个设备的IO和中断能力暴露给用户态,从而实现在用户态对硬件的直接访问。它的基本实现方法是,当我们probe一个设备的时候,通过uio_register_device()注册为一个字符设备/dev/uioN,用户程序通过对这个设备mmap访问它的IO空间,通过read/select等接口等待中断。
UIO的缺点在于,用户态的虚拟地址无法直接用于做设备的DMA地址(因为在用户态无法知道DMA内存的物理地址),这样限制了UIO的使用范围。我们有人通过UIO设备自己的ioctl来提供求物理地址的机制,从而实现DMA,但这种方案是有风险的。这里提到的UIO的缺点,基本上拒绝了大流量IO设备使用该机制提供用户空间访问的能力了。
vfio通过IOMMU的能力来解决这个问题。IOMMU可以为设备直接翻译虚拟地址,这样我们在提供虚拟地址给设备前,把地址映射提供给vfio,vfio就可以为这个设备提供页表映射,从而实现用户程序的DMA操作。背负提供DMA操作这个使命,VFIO要解决一个更大的问题,就是要把设备隔离掉。在Linux的概念中,内核是可信任的,用户程序是不可信任的,如果我们允许用户程序对设备做DMA,那么设备也是不可信任的,我们不能允许设备访问程序的全部地址空间(这会包括内核),所以,每个设备,针对每个应用,必须有独立的页表。这个页表,通过iommu_group承载(iommu_group.domain),和进程的页表相互独立。进程必须主动做DMA映射,才能把对应的地址映射写进去。
所以vfio的概念空间是container和group,前者代表设备iommu的格式,后者代表一个独立的iommu_group(vfio中用vfio_group代表),我们先创建container,然后把物理的iommu_group绑定到container上,让container解释group,之后我们基于group访问设备(IO,中断,DMA等等)即可。
这个逻辑空间其实是有破绽的,iommu_group是基于设备来创建的,一个设备有一个iommu_group(或者如果这个设备和其他设备共享同一个IOMMU硬件,是几个设备才有一个iommu_group),那如果我两个进程要一起使用同一个设备呢?基于现在的架构,你只能通过比如VF(Virtual Function,虚拟设备),在物理上先把一个设备拆成多个,然后还是一个进程使用一个设备。这用于虚拟机还可以,但如果用于其他功能,基本上是没戏了。
再说,VF功能基本都依赖SR-IOV这样的实现,也不是你想用就能用的。这我们就要引出vfio-mdev(以下简称mdev)了。
mdev本质上是在vfio层面实现VF功能。在mdev的模型中,通过mdev_register_device()注册到mdev中的设备称为父设备(parent_dev),但你用的时候不使用父设备,而是通过父设备提供的机制(在sysfs中,后面会详细谈这个)创建一个mdev,这个mdev自带一个iommu_group,这样,你有多个进程要访问这个父设备的功能,每个都可以有独立的设备页表,而且互相不受影响。
所以,整个mdev框架包括两个基本概念,一个是pdev(父设备),一个是mdev(注意,我们这里mdev有时指整个vfio-mdev的框架,有时指基于一个pdev的device,请注意区分上下文)。前者提供设备硬件支持,后者支持针对一个独立地址空间的请求。
两者都是device(struct device),前者的总线是真实的物理总线,后者属于虚拟总线mdev,mdev上只有一个驱动vfio_mdev,当你通过pdev创建一个mdev的时候,这个mdev和vfio_mdev驱动匹配,从而给用户态暴露一个普通vfio设备的接口(比如platform_device或者pci_device)的接口。
换句话说,如果一个设备需要给多个进程提供用户态驱动的访问能力,这个设备在probe的时候可以注册到mdev框架中,成为一个mdev框架的pdev。之后,用户程序可以通过sysfs创建这个pdev的mdev。
pdev注册需要提供如下参数:
点击(此处)折叠或打开
struct mdev_parent_ops {
struct module *owner;
const struct attribute_group **dev_attr_groups;
const struct attribute_group **mdev_attr_groups;
struct attribute_group **supported_type_groups;
int (*create)(struct kobject *kobj, struct mdev_device *mdev);
int (*remove)(struct mdev_device *mdev);
int (*open)(struct mdev_device *mdev);
void (*release)(struct mdev_device *mdev);
ssize_t (*read)(struct mdev_device *mdev, char __user *buf,
size_t count, loff_t *ppos);
ssize_t (*write)(struct mdev_device *mdev, const char __user *buf,
size_t count, loff_t *ppos);
long (*ioctl)(struct mdev_device *mdev, unsigned int cmd,
unsigned long arg);
int (*mmap)(struct mdev_device *mdev, struct vm_area_struct *vma);
};
其中三个attribute_group都用于在sysfs中增加一组属性。device本身根据它的bus_type,就会产生一个sysfs的属性组(所谓属性组就是sysfs中的一个目录,里面每个文件就是一个“属性”,文件名就是属性名,内容就是属性的值),假设你的pdev是/sys/bus/platform/devices/abc.0,那么这三个attribute_group产生的属性分别在:
dev_attr_groups:/sys/bus/platform/devices/abc.0下
mdev_attr_groups:/sys/bus/platform/devices/abc.0/下,/sys/bus/mdev/devices中有这个设备的链接
supported_type_groups:/sys/bus/platform/devices/abc.0/mdev_supported_types/下,里面有什么属性是框架规定的,包括:
1) name:设备名称
2) available_instances:还可以创建多少个实例
3) device_api:设备对外的接口API标识
这些参数支持具体用户态驱动如何访问这个设备,pdev的驱动当然可以增加更多。mdev框架在这个目录中还增加如下属性:
1) devices:这是一个目录,链接向所有被创建的mdev
2) create:向这个文件中写入一个uuid就可以创建一个新的mdev,实际上产生对mdev_parent_ops.create()的回调;
mdev这个模型建得最不好的地方是,create的时候只能传进去一个uuid,不能传进去参数,这样如果我创建的设备需要参数怎么办呢?那就只能创建以后再设置了,这增加了“创建以后没有足够资源提供”的可能性),不过看起来,大部分情况我们是可以接受这个限制的。
virtio-mdev
说完了vfio-mdev再来看看virtio-mdev。我们为什么要引入vfio-mdev,因为为了屏蔽不同厂商的配置接口差异需要一个中间层,而这个中间层就是基于vfio-mdev的virtio-mdev。virtio-mdev框架的主要目的是提供给不同的vDPA网卡厂家一个标准的API来实现他们自己的控制路径。mdev提供的框架可以支持vDPA实现数据和控制路径的分离。数据路径硬化,控制路径在软件实现。
这个驱动可以是用户态基于VFIO,也可以是内核态基于virtio的。在目前这个系列,主要关注基于vfio的用户态驱动,但是在未来也会讨论基于virtio的内核态驱动,比如支持AF_VIRTIO。
这个驱动的实现也比较简单,本质上就是一些列的virtio-mdev的API。主要包含:
1) set/get 设备的配置空间
2) set/get virtqueue的元数据:vring地址,大小和基地址
3) kick一个特定的virtqueue
4) 为一个特定的virtqueue注册回调中断
5) 协商功能
6) set/get 脏页日志
7) 启动/重置设备
可以看到这就是virtio消息处理的功能,所以virtio-mdev就是一个抽象层,对上提供统一的接口来支持virtio的配置,对下屏蔽不同厂商的差异,每个厂商实现自己的这些接口注册进来。
vhost-mdev
vhost-mdev 是一个kernel的模块,主要功能是:
(1) 转发用户空间的virtio 命令到virtio mdev的API(这里看出vhost-mdev是在virtio-mdev之上的);
(2) 复用VFIO的框架来准备DMA映射和解映射的用户空间请求。
vhost-mdev 相当于一个直接和qemu对接的,类似于vhost-net的角色,不过它只是一个转换的作用,将qemu发过来的virtio命令转换为virtio mdev的标准API调用(如set_feature,get_feature)。
vhost-mdev通常的工作流程如下:
(1) 把自己注册成一个新类型的mdev驱动
(2) 对外提供和vhost-net兼容的ioctl接口,用户空间的VFIO驱动可以传递virtio的命令
(3) 翻译好的virtio命令以virtio mdev API的形式通过mdev bus传递给virtio-mdev设备。
(4) 当一个新的mdev设备创建时,kernel总是厂商去加载驱动
(5) 在加载过程中,vhost-mdev会把virtio mdev设备连接在VFIO的群组,因此DMA请求就可以通过VFIO的文件描述符。
vhost-mdev是连接用户空间驱动和virtio-mdev设备的关键。它为用户空间驱动提供两个文件描述符:
1) vhost-mdev FD:从用户空间接受vhost的控制命令
2) VFIO container FD:用户空间驱动用来设置DMA
vhost-vfio
vhost-vfio从QEMU的观点来看,vhost-vfio就是一个新类型的QEMU网路后端用来支持virtio-net的设备。(注意,vhost-vfio是在qemu侧工作的)它的主要作用是:
(1) 设置vhost-mdev设备:打开vhost-mdev的设备文件,用来传递vhost的命令到设备去,得到vhost-mdev设备的container,用来传递DMAsetup的命令到VFIO container。
(2) 从virtio-net设备接收数据路径卸载的命令( set/get virtqueue 状态,set 脏页日志,功能协商等等),并把他们翻译vhost-mdev的ioctl。
(3) 接受vIOMMU map和umap的命令并同VFIO DMA的ioctl执行。
最后我们再以下图总结一下vDPA实现的关键,vDPA只将dataplan硬件化,所以重点要考虑的是control plan。设备的PCI 配置空间等还是有qemu模拟,但qemu收到Guest写寄存器的中断时的处理不能再像对待vhost-net一样了,所以qemu引入了vhost-vfio模块用来和后端协商。
而vhost-mdev则作为kernel处理后端协商的代理,接收来自qemu的控制消息,并将消息转文化virtio-mdev的标准接口调用。Virtio-mdev是一个抽象层,抽象了virtio的常用处理函数接口,同时又基于vfio-mdev框架对接不同硬件设备,而不同的硬件厂商只需要实现virtio-mdev的标准接口,同时支持vfio-mdev即可。这样控制通道就从qemu到厂商硬件打通了。
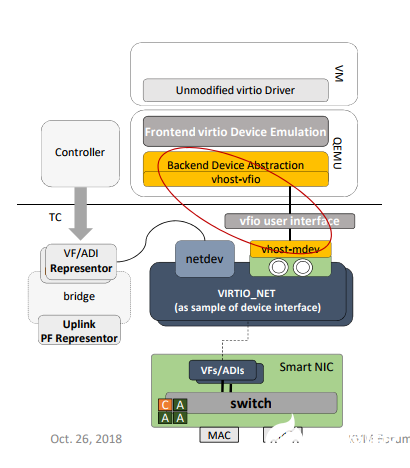
DPDK中的vDPA实现
下面我们看一下在DPDK中是如何实现对vDPA的支持的,我们的分析代码是基于DPDK release 20.02版本的,因为正是在这个版本增加了基于Mellanox设备的vDPA PMD(回想当初写第一篇关于DPDK的文章还是release 16.07)。 Mellanox支持vDPA的网卡有 ConnectX-6, Mellanox ConnectX-6 Dx 以及Mellanox BlueField。在DPDK的example中有一个vDPA的使用例子,这个是在18.11版本加入的,其使用方式可以参考https://mp.weixin.qq.com/s/YspEKL5fRmoJJbHlyPz9IA。这里我们就从这个example入手分析下DPDK中关于vDPA的实现。
这个程序的启动命令是类似如下的方式:
./ vdpa -c 0x2 -n 4 --socket-mem 1024,1024 -w 0000:06:00.3,vdpa=1 -w 0000:06:00.4,vdpa=1
vDPA的设备初始化
所以首先一定是通过-w指定的PCI设备加载对应的驱动,我们以Mellanox的vDPA驱动(mlx5_vdpa_driver)为例分析,注意其相关代码和Mellanox 正常mlx5驱动不在一起,而是在drivers/vdpa的专门路径中。
下面就看一下mlx5_vdpa_driver的注册过程。
点击(此处)折叠或打开
static struct rte_pci_driver mlx5_vdpa_driver = {
.driver = {
.name = "mlx5_vdpa",
},
.id_table = mlx5_vdpa_pci_id_map,
.probe = mlx5_vdpa_pci_probe,
.remove = mlx5_vdpa_pci_remove,
.drv_flags = 0,
};
其核心是驱动加载函数:mlx5_vdpa_pci_probe
l mlx5_vdpa_pci_probe
点击(此处)折叠或打开
/**
* DPDK callback to register a PCI device.
*
* This function spawns vdpa device out of a given PCI device.
*
* @param[in] pci_drv
* PCI driver structure (mlx5_vpda_driver).
* @param[in] pci_dev
* PCI device information.
*
* @return
* 0 on success, 1 to skip this driver, a negative errno value otherwise
* and rte_errno is set.
*/
static int
mlx5_vdpa_pci_probe(struct rte_pci_driver *pci_drv __rte_unused,
struct rte_pci_device *pci_dev __rte_unused)
{
struct ibv_device *ibv;
struct mlx5_vdpa_priv *priv = NULL;
struct ibv_context *ctx = NULL;
struct mlx5_hca_attr attr;
int ret;
/*......*/
ctx = mlx5_glue->dv_open_device(ibv);
priv = rte_zmalloc("mlx5 vDPA device private", sizeof(*priv),
RTE_CACHE_LINE_SIZE);
ret = mlx5_devx_cmd_query_hca_attr(ctx, &attr);
if (ret) {
DRV_LOG(ERR, "Unable to read HCA capabilities.");
rte_errno = ENOTSUP;
goto error;
} else {
if (!attr.vdpa.valid || !attr.vdpa.max_num_virtio_queues) {
DRV_LOG(ERR, "Not enough capabilities to support vdpa,"
" maybe old FW/OFED version?");
rte_errno = ENOTSUP;
goto error;
}
priv->caps = attr.vdpa;
priv->log_max_rqt_size = attr.log_max_rqt_size;
}
priv->ctx = ctx;
priv->dev_addr.pci_addr = pci_dev->addr;
priv->dev_addr.type = PCI_ADDR;
priv->id = rte_vdpa_register_device(&priv->dev_addr, &mlx5_vdpa_ops);
if (priv->id < 0) {
DRV_LOG(ERR, "Failed to register vDPA device.");
rte_errno = rte_errno ? rte_errno : EINVAL;
goto error;
}
SLIST_INIT(&priv->mr_list);
SLIST_INIT(&priv->virtq_list);
pthread_mutex_lock(&priv_list_lock);
TAILQ_INSERT_TAIL(&priv_list, priv, next);
pthread_mutex_unlock(&priv_list_lock);
return 0;
error:
if (priv)
rte_free(priv);
if (ctx)
mlx5_glue->close_device(ctx);
return -rte_errno;
}
这个函数首先分配mlx的vDPA设备私有结构struct mlx5_vdpa_priv,然后通过mlx5_devx_cmd_query_hca_attr函数获取当前设备的属性并初始化这个vDPA私有结构。其中关键的一步是通过 rte_vdpa_register_device函数申请vDPA通用结构struct rte_vdpa_device,并将mlx的vDPA ops函数结合mlx5_vdpa_ops设置为其ops。
l rte_vdpa_register_device
点击(此处)折叠或打开
int
rte_vdpa_register_device(struct rte_vdpa_dev_addr *addr,
struct rte_vdpa_dev_ops *ops)
{
struct rte_vdpa_device *dev;
char device_name[MAX_VDPA_NAME_LEN];
int i;
if (vdpa_device_num >= MAX_VHOST_DEVICE || addr == NULL || ops == NULL)
return -1;
for (i = 0; i < MAX_VHOST_DEVICE; i++) {
dev = vdpa_devices[i];
if (dev && is_same_vdpa_device(&dev->addr, addr))
return -1;
}
for (i = 0; i < MAX_VHOST_DEVICE; i++) {
if (vdpa_devices[i] == NULL)
break;
}
if (i == MAX_VHOST_DEVICE)
return -1;
snprintf(device_name, sizeof(device_name), "vdpa-dev-%d", i);
dev = rte_zmalloc(device_name, sizeof(struct rte_vdpa_device),
RTE_CACHE_LINE_SIZE);
if (!dev)
return -1;
memcpy(&dev->addr, addr, sizeof(struct rte_vdpa_dev_addr));
dev->ops = ops; /*设置ops为设备厂商的具体实现*/
vdpa_devices[i] = dev;
vdpa_device_num++; /*全局变量,记录vDPA设备的个数*/
return i;
}
rte_vdpa_register_device中关键工作就是分配一个vDPA通用结构struct rte_vdpa_device,并将mlx vDPA的实现操作mlx5_vdpa_ops关联上。而rte_vdpa_device结构又是一个全局数组,其数组index就是vDPA的设备id,也就是struct mlx5_vdpa_priv中的id。
另外mlx5_vdpa_ops的具体成员和实现结合如下。可以看到这里的函数和vhost-user的消息处理函数很多是对应的。
点击(此处)折叠或打开
static struct rte_vdpa_dev_ops mlx5_vdpa_ops = {
.get_queue_num = mlx5_vdpa_get_queue_num,
.get_features = mlx5_vdpa_get_vdpa_features,
.get_protocol_features = mlx5_vdpa_get_protocol_features,
.dev_conf = mlx5_vdpa_dev_config,
.dev_close = mlx5_vdpa_dev_close,
.set_vring_state = mlx5_vdpa_set_vring_state,
.set_features = mlx5_vdpa_features_set,
.migration_done = NULL,
.get_vfio_group_fd = NULL,
.get_vfio_device_fd = NULL,
.get_notify_area = NULL,
};
这样就完成了Mellanox侧的vDPA设备初始化,产生的相关数据结构如下图所示。
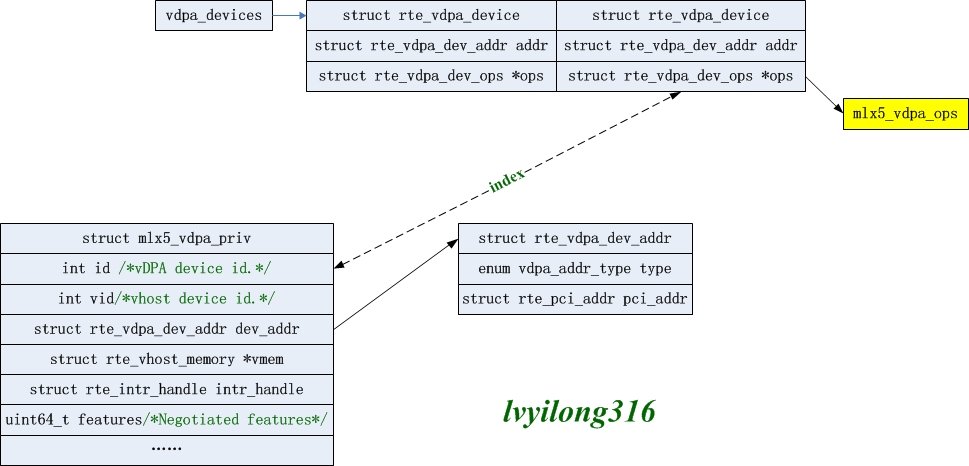
vDPA和vhost-uesr关联
厂商定制化的vDPA部分以及初始化完毕,下面我们看下vhost-user和vDPA是怎么关联的。参考的是vDPA example中的start_vdpa函数,具体如下
l start_vdpa
点击(此处)折叠或打开
static int
start_vdpa(struct vdpa_port *vport)
{
int ret;
char *socket_path = vport->ifname;
int did = vport->did;/* vDPA设备id */
if (client_mode)
vport->flags |= RTE_VHOST_USER_CLIENT;
if (access(socket_path, F_OK) != -1 && !client_mode) {
RTE_LOG(ERR, VDPA,
"%s exists, please remove it or specify another file and try again. ",
socket_path);
return -1;
}
ret = rte_vhost_driver_register(socket_path, vport->flags);/*初始化vsocket结构,创建vhost-user后端重连线程*/
if (ret != 0)
rte_exit(EXIT_FAILURE,
"register driver failed: %s ",
socket_path);
ret = rte_vhost_driver_callback_register(socket_path,
&vdpa_sample_devops); /*注册自定义的vsocket->notify_ops*/
if (ret != 0)
rte_exit(EXIT_FAILURE,
"register driver ops failed: %s ",
socket_path);
ret = rte_vhost_driver_attach_vdpa_device(socket_path, did);/*将vsocket结构和vDPA设备关联*/
if (ret != 0)
rte_exit(EXIT_FAILURE,
"attach vdpa device failed: %s ",
socket_path);
if (rte_vhost_driver_start(socket_path) < 0)/*创建vhost控制面消息处理线程,将vsocket加入重连链表*/
rte_exit(EXIT_FAILURE,
"start vhost driver failed: %s ",
socket_path);
return 0;
}
这个函数关键执行了4步操作:
(1) rte_vhost_driver_register:初始化vsocket结构,创建vhost-user后端重连线程;
(2) rte_vhost_driver_callback_register:注册自定义的vsocket->notify_ops;
(3) rte_vhost_driver_attach_vdpa_device:将vsocket结构和vDPA设备关联
(4) rte_vhost_driver_start:创建vhost控制面消息处理线程,将vsocket加入重连链表;
其中(1)(2)(4)都是vhost-user设备的常规操作,这里不再展开,其中关键的是(3)。
l rte_vhost_driver_attach_vdpa_device
点击(此处)折叠或打开
int
rte_vhost_driver_attach_vdpa_device(const char *path, int did)
{
struct vhost_user_socket *vsocket;
if (rte_vdpa_get_device(did) == NULL || path == NULL)
return -1;
pthread_mutex_lock(&vhost_user.mutex);
vsocket = find_vhost_user_socket(path);
if (vsocket)
vsocket->vdpa_dev_id = did;
pthread_mutex_unlock(&vhost_user.mutex);
return vsocket ? 0 : -1;
}
这个函数将vDPA的deviceid记录在vsocket结构中,这样就将vhost和vDPA设备关联起来了。
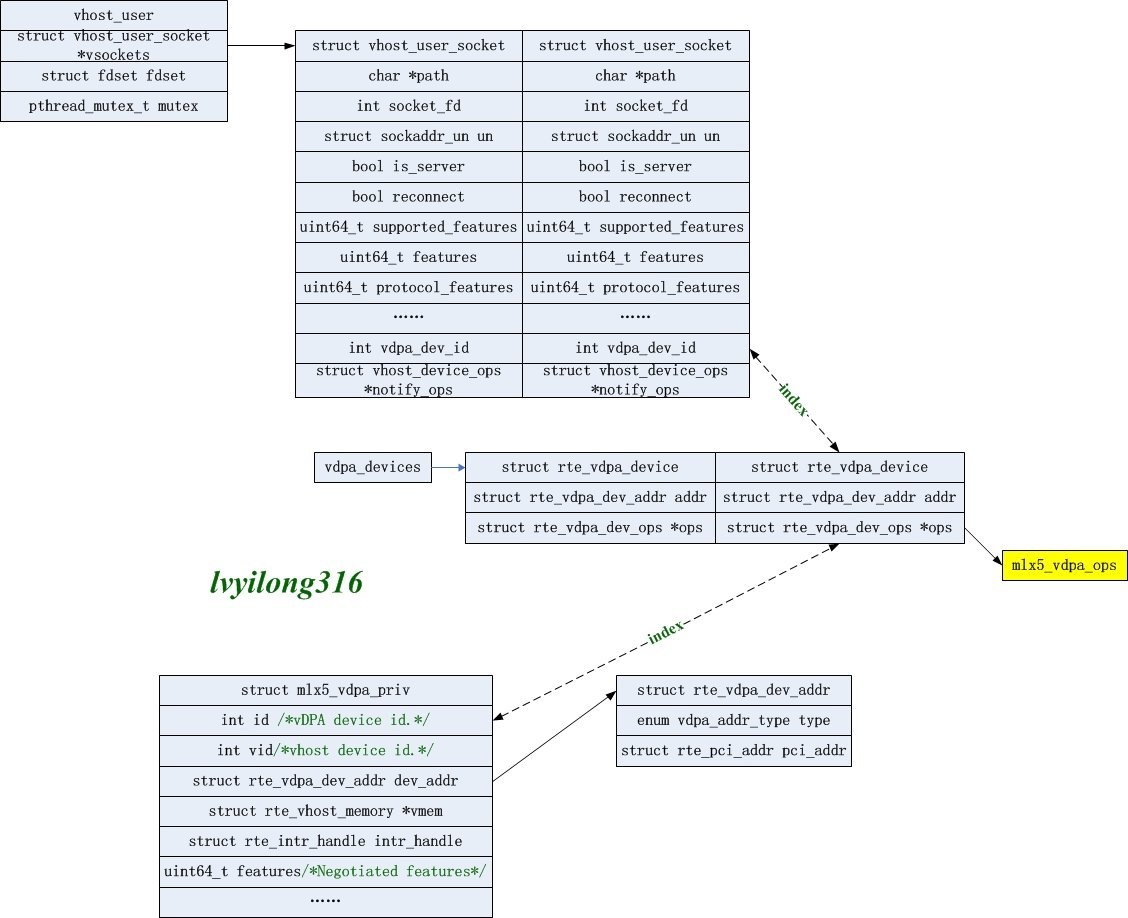
vhost控制面的vDPA初始化
前面说到通过vhost-user的vsocket结构中的vDPA deviceid将vhost-user和vDPA关联起来,那么下面就来看一下vhost-user进行初始化时怎么将对应vDPA设备初始化的。
首先,vhost-user前后端建立连接后会调用vhost_user_add_connection,而vhost_user_add_connection中则会调用 vhost_new_device()分配struct virtio_net结构,而virtio_net中也有一个vdpa_dev_id,在调用vhost_attach_vdpa_device时将vsocket的vdpa_dev_id赋值给virtio_net的vdpa_dev_id。
点击(此处)折叠或打开
static void
vhost_user_add_connection(int fd, struct vhost_user_socket *vsocket)
{
int vid;
size_t size;
struct vhost_user_connection *conn;
int ret;
/*......*/
vid = vhost_new_device();
if (vid == -1) {
goto err;
}
/*......*/
vhost_attach_vdpa_device(vid, vsocket->vdpa_dev_id);
/*......*/
}
有了这个关联以后,后续所有vhost-user的消息处理就可以找到对应的vDPA设备,进而找到厂商关联的vDPA ops函数。回忆前面设备初始化时将Mellanox的mlx5_vdpa_ops注册到的vDPA设备上,其实这是一个struct rte_vdpa_dev_ops结构,如下所示:
点击(此处)折叠或打开
/**
* vdpa device operations
*/
struct rte_vdpa_dev_ops {
/** Get capabilities of this device */
int (*get_queue_num)(int did, uint32_t *queue_num);
/** Get supported features of this device */
int (*get_features)(int did, uint64_t *features);
/** Get supported protocol features of this device */
int (*get_protocol_features)(int did, uint64_t *protocol_features);
/** Driver configure/close the device */
int (*dev_conf)(int vid);
int (*dev_close)(int vid);
/** Enable/disable this vring */
int (*set_vring_state)(int vid, int vring, int state);
/** Set features when changed */
int (*set_features)(int vid);
/** Destination operations when migration done */
int (*migration_done)(int vid);
/** Get the vfio group fd */
int (*get_vfio_group_fd)(int vid);
/** Get the vfio device fd */
int (*get_vfio_device_fd)(int vid);
/** Get the notify area info of the queue */
int (*get_notify_area)(int vid, int qid,
uint64_t *offset, uint64_t *size);
/** Reserved for future extension */
void *reserved[5];
};
可以看到他和我们的vhost-user消息处理函数很多都是对应的,这也是前面我们提到过的virtio-mdev在DPDK的表现。所以很自然的相当在vhost-user处理后端消息时会调用对应的vDPA处理函数。以vhost_user_set_features为例,其中调用了rte_vdpa_get_device通过virtio-net的vdpa_dev_id获取到对应的vDPA设备,并调用对应的vDPA的set_features函数。
点击(此处)折叠或打开
static int
vhost_user_set_features(struct virtio_net **pdev, struct VhostUserMsg *msg,
int main_fd __rte_unused)
{
/*......*/
did = dev->vdpa_dev_id;
vdpa_dev = rte_vdpa_get_device(did);
if (vdpa_dev && vdpa_dev->ops->set_features)
vdpa_dev->ops->set_features(dev->vid);
return RTE_VHOST_MSG_RESULT_OK;
}
其他函数也是类似的,我们可以搜索一下vdpa_dev_id关键字确认。
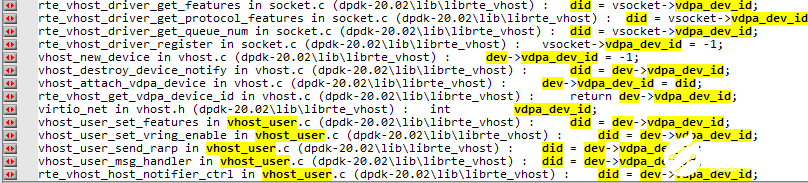
整个vDPA在DPDK的工作方式可以用下图来表示。
-
Arm上带DPDK的Open vSwitch测试系列2022-03-31 4582
-
如何使用DPDK设置OvS从而在Arm平台上运行PHY-VM-PHY或vHost-Loopback流量测试2022-04-12 6373
-
StratoVirt 中的虚拟网卡是如何实现的?2022-08-10 20929
-
基于Intel dpdk数据包捕获技术研究2017-11-24 1117
-
关于ODP和DPDK的介绍与解决方案(一)2018-06-29 12357
-
DPDK的设计方法与API应用介绍2018-10-30 5049
-
DPDK如何处理物理内存2020-09-26 3556
-
DPDK内存的基本概念2020-10-26 3028
-
DPDK的提出以及设计思想是什么?2021-05-24 4992
-
简述高速流量处理DPDK替代方案2021-06-22 4036
-
openEuler Summit 2021-云/虚拟化分论坛:虚拟化硬件加速以及vDPA框架案例分析2021-11-10 2806
-
成果突破!英特尔、研华科技与广和通联合发布《基于uCPE硬件平台集成DPDK与XDP推动5G网络优化》白皮书2022-04-22 1566
全部0条评论

快来发表一下你的评论吧 !
