

基于点云的3D障碍物检测
描述
基于点云的3D障碍物检测
主要有以下步骤:
点云数据的处理
基于点云的障碍物分割
障碍物边框构建
点云到图像平面的投影
点云数据的处理
KITTI数据集
KITTI数据集有四个相机,主要使用第三个相机(序号为02)拍摄的图片、标定参数和标签文件。
点云数据一般表示为N行,至少三列的numpy数组。每行对应一个单独的点,所以使用至少3个值的空间位置点(X, Y, Z)来表示。
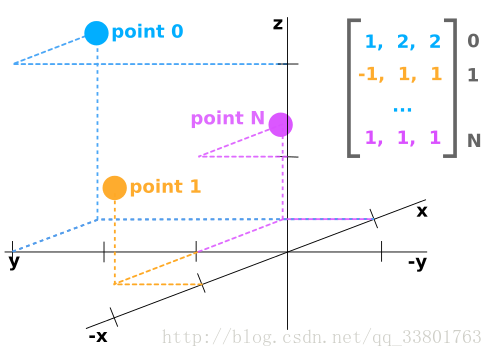
在KITTI数据中有一个附加值“反射率”,这是衡量激光光束在那个位置被反射回来了多少。所以在KITTI数据中,其点云数据就是N*4的矩阵。
三维点云的可视化
在MATLAB中可视化三维点云,如下图。
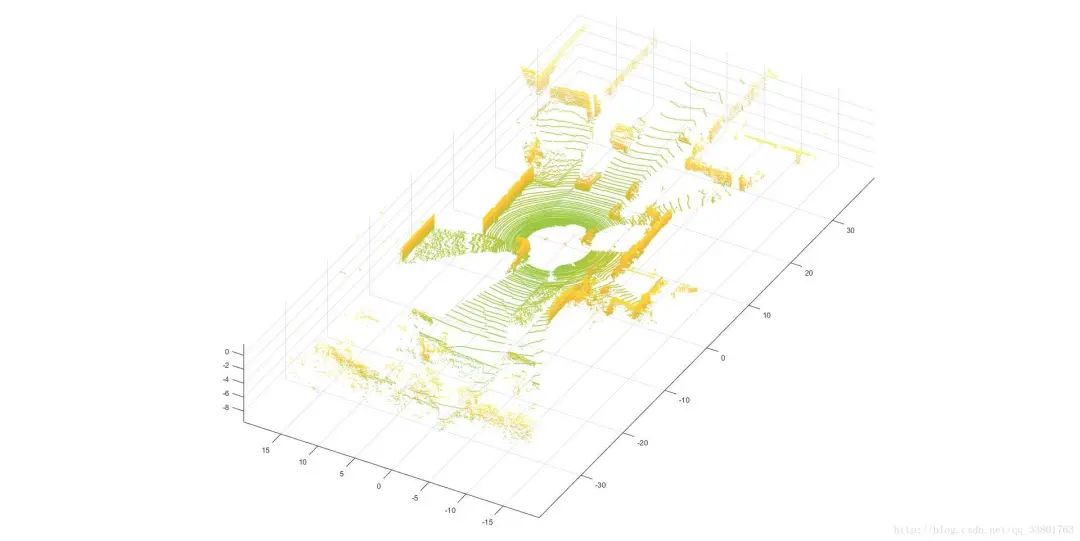
额外的工作:三维点云的可视化,可使用python中的mayavi来实现,它是一个专门画3D图的python工具。另外,在有的论文中常常用到点云的鸟瞰图和前视图(包含360度的全景柱面图)。
高精地图
ROI指定从高精地图检索到包含路面、路口的可驾驶区域。以下点云数据处理在高精地图的基础上进行点云处理,默认去除路边建筑物和树木等背景对象。
额外的工作:百度Apollo使用了高精地图ROI过滤器建立了网格,对网格中的点云数据特征进行CNN学习来实现障碍物分割聚类,之后使用了MinBox构建障碍物边框。
去除地平面
找到地面平面并移除地面平面点,使用RANSAC(随机采样一致)算法检测和匹配地面平面,最后结果如下图。
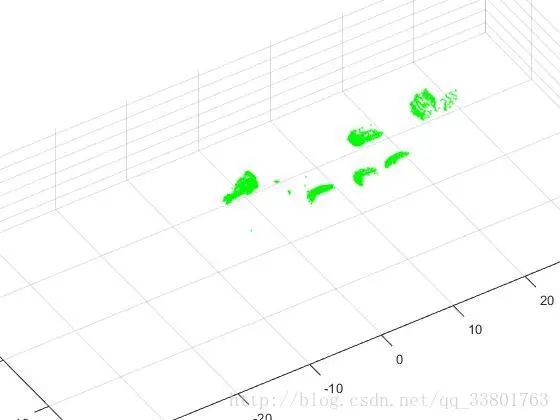
基于点云的障碍物分割
对点云数据进行预处理后,只留下路面上障碍物的点云,其余的背景障碍物以及地面已被移除。障碍物分割主要检测和划分单独的障碍物,将单独的车辆、行人等障碍物分割出来。
由于只是在二维图像中画出3D目标框,所以保留车辆前面的点(取x>5)。在剩下的点云中使用栅格法构建俯视图(即投影到x-y平面)2D网格,网格大小由点云的大小来决定。
通过建立网格,可以得到以下统计量:
网格中的点云个数
网格中的点云的最大、最小和平均高度
网格中的点云序号
基于以上统计量,寻找每个格子附近(3*9)领域的连通区域,每个连通区域为一个障碍物,达到了分割障碍物的目的。
额外的工作:使用KITTI的标签label文件来得到二维图像上的障碍物边界框,在此边界框中进行聚类分割前景障碍物和背景。
障碍物边框构建
从以上得到每个障碍物点云后,就需要画出每个障碍物的边界框。在这里使用最小凸包法求出包围点云的最小面积多边形边界框,如下图。
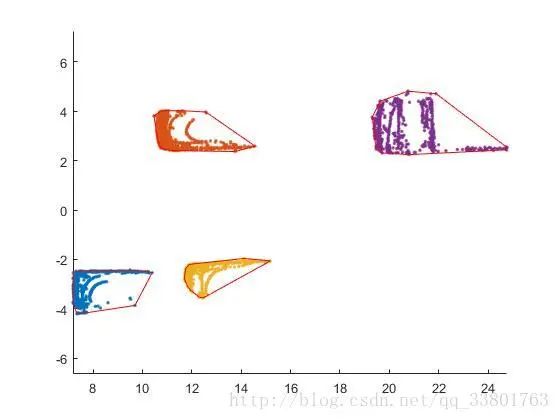
基于最小凸包法得到障碍物周围的点,在这些点的基础上求出包围最小面积的矩形,如下图。
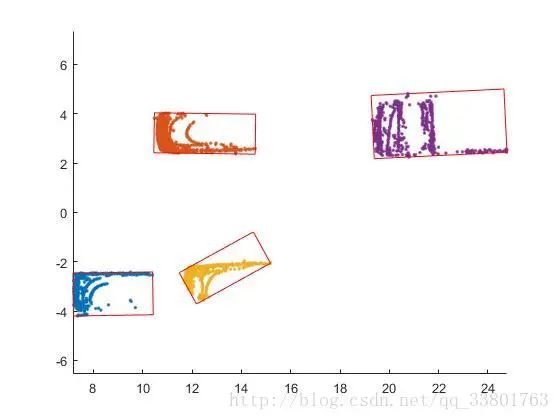
可以看到黄色部分的点云求最小面积矩形边界框,会因为点云的稀疏,使得边界框不精确。
额外的工作:根据点云的x, y坐标找到x, y的最大值和最小值的点(共有4个点),根据这4个点画出矩形框。很显然,这样做是不行的,但是如果知道车辆的朝向,以朝向为轴找到距离轴最大最小的点,此方法画出的边界框更加精确。
点云到图像平面的投影
点云到图像平面的投影需要读取标定参数文件,得到三个参数(相机的内参矩阵、基于相机0的旋转矩阵、外参矩阵),三个参数的乘积也就是点云到图像的投影矩阵,结果如下图。
-
iTOF技术,多样化的3D视觉应用2025-09-05 383
-
基于深度学习的方法在处理3D点云进行缺陷分类应用2024-02-22 2790
-
基于3D点云的多任务模型在板端实现高效部署2023-12-28 3419
-
检测障碍物有什么什么传感器?2023-11-08 548
-
基于点云的3D障碍物检测介绍2023-06-26 2220
-
使用IR模块的障碍物检测器2022-11-14 960
-
何为3D点云语义分割2022-07-21 10677
-
Toposens推出采用英飞凌XENSIV™MEMS麦克风的新型3D超声波传感器2021-11-18 2263
-
基于用于检测障碍物的传感器的3D打印清洁机器人2021-04-28 3145
-
请问Infrared Proximity Sensor如何检测前方是否有障碍物?2020-11-06 1487
-
基于labview机器视觉的障碍物时别2017-03-14 6293
-
基于单片机的道路障碍物系统,新人求教2015-03-10 3266
-
障碍物检测实验2009-03-23 3643
全部0条评论

快来发表一下你的评论吧 !
