

写RTL代码时,尽可能地做到代码风格与硬件结构相匹配
描述
两个数相加,三个数相加有什么不同 接下来,我们考虑4个32-bit有符号数相加该如何实现,其中目标时钟频率仍为400MHz。以UltraScale Plus系列芯片为目标芯片。 第一种方案:四个数直接相加此方案对应的电路图如下图所示。这里不难看出关键路径是三个加法器所在路径,这将是时序收敛的瓶颈。
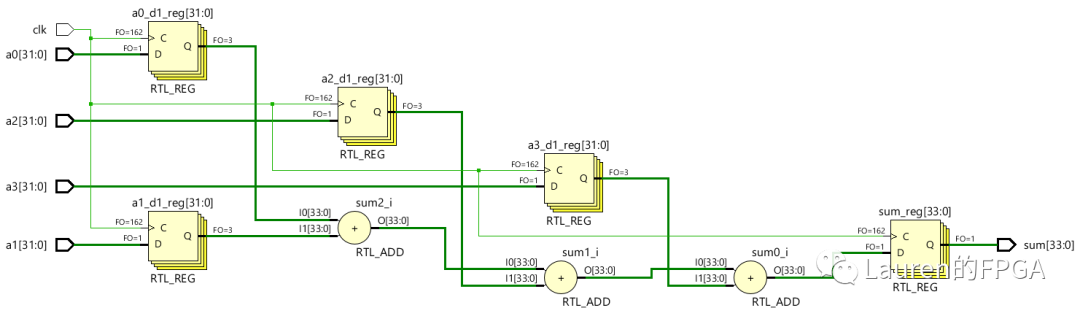
此电路对应的SystemVerilog代码如下图所示。
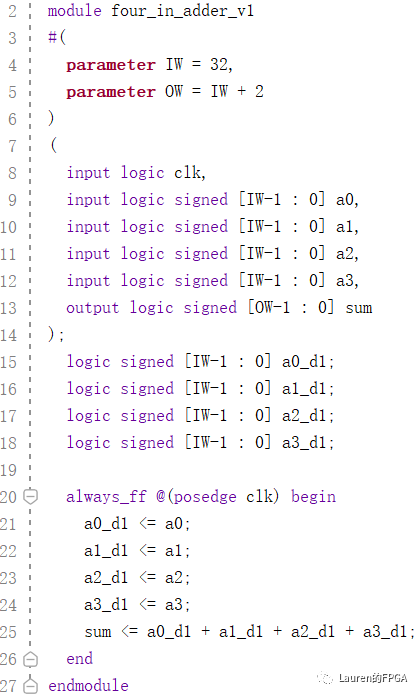
从综合后的结果来看,逻辑级数最高为7。
第二种方案:加法树
加法树的结构如下图所示,两两相加。与第一种方案相比,可以有效降低逻辑级数。

此电路对应的SystemVerilog代码如下图所示。

从综合后的结果来看,逻辑级数最高为6。 第三种方案:加法链之所以选用加法链的结构是因为DSP48本身就是这种链式结构。对应的电路如下图所示。其中a0和a1端口有一级寄存器,a2端口有两级寄存器,a3端口有三级寄存器。

此电路对应的SystemVerilog代码如下图所示。

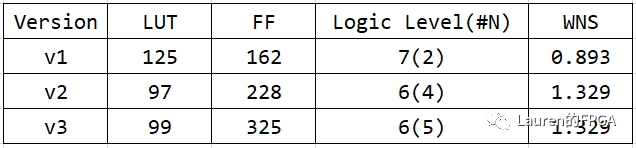
接下来,我们对这三种方案进行比较,如下图所示。不难看出,第一种方案逻辑级数最高,消耗的LUT也最多,时序结果也是最差的(尽管达到了收敛的目的)。后两种方案不相上下。
如果将这三种方案通过综合属性USE_DSP使其映射到DSP48上,结果如何呢?如下图所示。不难看出,第一种方案只消耗了两个DSP,资源利用率最低,但时序也是最糟糕的。后两种方案都用了三个DSP,但第三种方案由于可以很好地匹配硬件结构,故时序最好。

对比下来不难得出这样的结论:写RTL代码时,尽可能地做到代码风格与硬件结构相匹配,可达到更好的性能。
Tcl之$$a 80%的概率...... AI Engine到底是什么?
ACAP不可不知的几个基本概念
嵌套的for循环,到底对哪个执行pipeline更好
HLS中循环的并行性(2)
HLS中循环的并行性(1)
HLS优化方法DATAFLOW你用了吗
HLS中如何控制流水程度
Vivado HLS学习资料有哪些
如何查看可综合C代码的中间结果
如何在C代码中插入移位寄存器
HLS IP Library? HLS Math Library:csim ?C/RTL co-sim(2) HLS Math Library:csim ?C/RTL co-sim(1) 加法运算很简单? AXI-4 Lite与AXI-4 Memory Mapped有什么区别? 深入理解AXI-4 Memory Mapped 接口协议 AXI是Interface还是Bus? 如何阅读时序报告 时序报告要看哪些指标 如何使set_max_delay不被覆盖 一些小巧的IP IP是用DCP还是XCI? 如果使用第三方综合工具,Xilinx IP… IP生成文件知多少 IP的约束需要处理吗? IP为什么被Locked? copy_ip你用过吗? IP是XCI还是XCIX 如何降低OSERDES/CLK和CLKDIV的Clock Skew 如何获取Device DNA 谈谈设计复用 过约束到底怎么做 时序收敛之Baseline 什么情况下要用OOC综合方式 异步跨时钟域电路该怎么约束 如何复用关键路径的布局布线信息 Vivado学习资料有哪些? 异步跨时钟域电路怎么设计 ECO都有哪些应用 FPGA中的CLOCK REGION和SLR是什么含义 FPGA中的BEL, SITE, TILE是什么含义 约束文件有哪些 如何高效复用Block的位置信息? 如何复用关键寄存器的位置信息 部分可重配置都生成哪些.bit文件 VIO你用对了吗 Device视图下能看到什么 Schematic视图下能看到什么 都是pin,有什么区别 都是net,有什么区别 如何快速查找目标cell 学习笔记:深度学习与INT8 学习笔记:多层感知器 学习笔记:单层感知器的局限性 学习笔记:单层感知器基础知识 学习笔记:神经网络学习算法 学习笔记:神经网络模型 学习笔记:ReLU的各种变形函数 学习笔记:神经元模型(2) 学习笔记:神经元模型(1) 学习笔记:深度学习之“深” 学习笔记:深度学习之“学习” 学习笔记:人工智能、机器学习和深度学习 2019文章汇总
原文标题:加法树还是加法链?
文章出处:【微信公众号:Lauren的FPGA】欢迎添加关注!文章转载请注明出处。
-
vhdl良好代码风格25点要求2012-02-06 4036
-
如何做到每天写代码?2014-04-25 5427
-
FPGA实战演练逻辑篇41:代码风格2015-06-25 3503
-
哪里可以买到尽可能高频率的无线能量发射接收模块2015-12-05 4462
-
勇敢的芯伴你玩转Altera FPGA连载35:Verilog代码风格概述2017-12-27 2544
-
Altera代码风格讲义--作者:骏龙小马2015-11-17 539
-
无代码无线门锁的制作教程2019-08-07 3854
-
进行RTL代码设计需要考虑时序收敛的问题2020-11-20 5181
-
Linux内核的首选代码风格应该如何设置2020-11-04 852
-
尽可能限制NVM写操作的数据库日志方案NVRC2021-04-08 1181
-
如何修改Linux内核代码风格?2021-05-13 2858
-
C语言代码风格2022-01-13 577
-
什么样的Verilog代码风格是好的风格?2022-10-24 2731
-
代码编程规范之命名规范2023-02-15 3163
-
浅谈Verilog HDL代码编写风格2023-11-20 1735
全部0条评论

快来发表一下你的评论吧 !
