

深度学习正在逼近计算极限 如何提升AI算力
人工智能
描述
“在智慧系统中,按照复杂度,排名是这样的:原子,分子,有机体,人类,AI,超级AI,然后是神。”
有意思的是,这个回答,来自OpenAI开发的预训练语言模型——GPT-3,这个可以跟人类对线、创作小说、编吉他谱的AI,着实在硅谷火了一把。
很难想象,2017年的ANI(弱人工智能,比如你手机上的Siri),智商测试的结果只有47,相当于一个六岁孩子的水平。
无疑,像GPT-3这样的AGI(强人工智能)才是下一代AI的未来。
那实现从ANI到AGI跨越的关键是什么呢?——算力。GPT-3的高智商,很大程度上得益于算力的提升,它的参数量是1750 亿,足足是 GPT-2 的 116 倍。
不过,麻省理工学院的研究人员最近发出了算力警告:深度学习正在逼近计算极限。
深度学习的阻碍——算力
现代计算机的计算能力以及可用于馈送算法的大量数据,的确让我们步入了AI开发的新高度。不过,还不够。
根据MIT的一项研究,深度学习的进展非常依赖算力的增长。他们断言,必须发明革命性的算法才能更有效地使用深度学习方法。
研究人员分析了预印本服务器Arxiv.org上的1058篇论文和其他基准资料,以理解深度学习性能和算力之间的联系,主要分析了图像分类、目标检测、问题回答、命名实体识别和机器翻译等领域两方面的计算需求:
1、每一网络遍历的计算量,或给定深度学习模型中单次遍历(即权值调整)所需的浮点运算数。
2、训练整个模型的硬件负担,用处理器数量乘以计算速度和时间来估算。
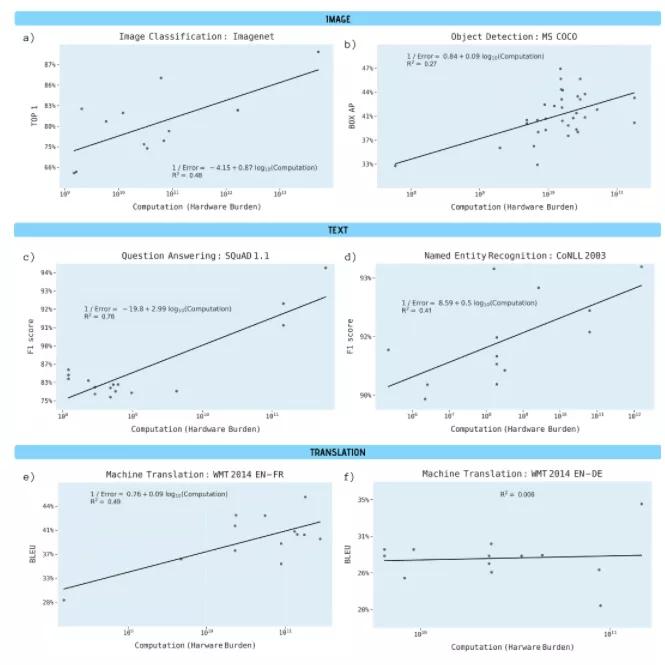
结论显示,训练模型的进步取决于算力的大幅提高,具体来说,计算能力提高10倍相当于3年的算法改进成果。
换言之,算力提高的背后,其实现目标所隐含的计算需求——硬件、环境和金钱等成本将变得无法承受。
计算中有一个称为摩尔定律的概念,它假定计算能力每两年翻一番。OpenAI最近发布的一项研究表明,AI训练中使用的计算能力每3到4个月翻一番,这大大提高了我们习惯的标准进度。自2012年以来,人工智能要求计算能力增加300,000倍,而按照摩尔定律,则只能将AI提升7倍。
人们从来没有想到过芯片的算力会有到达极限的一天,至少从来没有想到芯片算力极限会这么快到来。
深度学习的未来
关于提升算力,我们先把目光投向那些研究AI的大厂。
谷歌团队去年开发的一种翻译算法,大约需要运行12,000个专用芯片。据一些估计,通过云租用这么多的计算机功能将花费多达300万美元。
谷歌的高层们转念一想,这成本也太大了,这么下去不是个办法。于是他们搞起了“量子至上”,并开发了一种能够解决计算问题的量子处理器——Sycamore,计算能力相当于一台超级计算机的10,000多倍。
再看看IBM,谷歌在量子计算领域的最大竞争对手之一,当然也不甘示弱。IBM自己的Summit之类的超级计算机可以在两步内完成与Sycamore处理器相同的计算,仅需半天而不是10,000年。
虽然与谷歌的处理器完成任务大约需要三分半钟的时间相比,差距还是比较大的。但在深度学习领域取得如此大的进展,量子计算是条出路。
在这些大厂相互“厮杀血拼”的时候,吃瓜群众大都心存疑虑:深度学习,或者说机器学习,未来到底在何方?
2020年是至关重要的一年,这将为AI领域下一个十年的创新定下基调并继续保持现有的势头。以下是五个新兴AI和机器学习的趋势:
1)数字数据监管
在当今世界,数据就是一切。各种技术的出现推动了数据的补充。无论是汽车工业还是制造业;数据正以前所未有的速度生成。但是问题是,“所有数据都相关吗?”
好了,为了解开这个谜团,可以部署机器学习,因为它可以通过设置云解决方案和数据中心来对任意数量的数据进行排序。它仅根据数据的重要性过滤数据并调出功能数据,同时保留废料。这样,可以节省时间,组织也可以管理支出。
2020年,将产生大量数据,并且行业将要求机器学习对相关数据进行分类以提高效率。
2)语音协助中的机器学习
语音助手在行业中占相当大的比例。Siri,Cortana,Google Assistant和Amazon Alexa是智能个人助理的热门示例。
机器学习与人工智能相结合,可以以最高的准确性帮助处理操作。因此,机器学习将帮助行业轻松完成复杂而重要的任务,同时提高生产率。
到2020年,不断增长的研究与投资领域将主要集中在淘汰定制设计的机器学习语音帮助上。
3)有效营销
营销是每个企业在激烈的竞争中生存的重要因素。它在推动预期结果的同时提升了业务的存在性和可见性。但是,利用现有的多个营销平台,甚至要证明业务存在,就变得具有挑战性。
但是,如果一家企业足够成功,可以从现有用户数据中提取模式,那么就非常有希望制定成功且有效的营销策略。为了分析数据,可以使用机器学习来挖掘数据并评估研究方法以获得更有益的结果。
在未来一段时间内,人们高度期望采用机器学习来定义有效的营销策略。
4)网络安全的发展
网络安全一直是热门话题,黑客每天创建大量的恶意软件样本,借助计算机、网络、程序和数据中心,向企业或政府发动攻击。
值得庆幸的是,我们拥有机器学习技术,可通过自动执行复杂任务并自行检测网络攻击来提供多层保护。不仅如此,机器学习还可以扩展为对网络安全漏洞做出反应并减轻损害。它可以自动响应网络攻击,而无需人工干预。
展望未来,机器学习将用于高级网络防御计划中,以控制并保存损害。
5)可解释的人工智能-Explainable AI
XAI-可解释的人工智能是另一个正在讨论的未来AI趋势。如今在许多行业和用例中,机器学习方法得出的结果不容易解释。例如,数据科学家有时可能难以理解导致AI做出特定决定的原因,更不用说向其他人(例如客户)解释了。XAI的概念是一种AI,它可以解释自己的决策过程,它源于能够解释算法的推理方式的需要,因为它还可以改进算法并避免错误。
XAI开发的主要障碍是神经网络大多不那么容易解释,因为各层返回权重矩阵。已经有一些想法正在实施,例如权重矩阵的热图可以改善神经网络的可解释性。可以肯定的是,未来几年将在这一领域进行更多的研究。
深度学习的误区
目前,深度学习在计算机视觉、自然语言处理与自然科学领域均展开了大规模的应用。一方面,深度学习有着比其他机器学习算法更加优秀的普适性;另一方面,这种普适性是以更高的时间与空间复杂度为代价的。
作为一名算法工程师,需要做的不仅仅是关注算法的可行性,还需要关注算法本身的复杂度。算法的普适性使深度学习算法具有了比其他机器学习算法更加宽广的想象空间,而这也对相关从业者提出了更高的要求,因为需要了解多个学科的内容。
深度学习内容涉及的统计和几何内容是相对复杂的知识体系。初学者缺乏一个合适的实现过程与理论描述方式,在进行深入学习时,往往会有以下误区:
第一个误区是对所有算法均试图以图形方式去理解或者寻找一种形象的方式去解释。这种方式并不可取,因为初学者应当把精力放于公式之上,这对于算法实现和定量思维方式的建立都是十分重要的。
第二个误区是试图理解每一个公式,使学习过程无法继续进行。初学者应当先建立知识框架,也就是了解每一种算法之间的关系与内在设计思路,在此之上再进行对公式的理解。
第三个误区是太过强调机器学习库。机器学习库本身仅是辅助,更多的工作需要依赖于对算法的理解。在深入理解之后就会发现,几乎所有的机器学习库,比如PyTorch、Caffe等,均是十分相近的。
要解决这些问题,就要将精力集中于几个部分。比如在数学基础部分将主要精力放在理解什么是机器学习以及矩阵相关的概念;在深度神经网络部分希望读者更加关注于建模思路;深度学习建模思路是相近的,理解它有助于快速迁移至其他项目任务之中。
《深度学习算法和实践》力求以统一的数学语言详细而完整地描述深度学习理论,内容上侧重于与应用相关的重点算法与理论,特别是算法预测过程。每一章的写作过程尽量避免使用图形,取而代之的是详细的公式描述,这使读者初读本书时可能有些许障碍。但习惯了公式之后就会发现,图形会使我们的理解出现偏差,同时无法进行实现,而公式则没有这个问题。每一章都尽量对理论有完整的公式推演过程 ,供读者熟悉理论知识。同时,在章节最后会对公式进行实现,以帮助读者在进行理论学习的同时通过实践快速学握算法。
编辑:hfy
-
什么是AI算力模组?2025-09-19 440
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI的未来:提升算力还是智力2025-09-14 1895
-
摩尔线程与AI算力平台AutoDL达成深度合作2025-05-23 1442
-
DeepSeek推动AI算力需求:800G光模块的关键作用2025-03-25 915
-
信而泰CCL仿真:解锁AI算力极限,智算中心网络性能跃升之道2025-02-24 999
-
企业AI算力租赁是什么2024-11-14 2930
-
芯耀辉科技解读高速互连对于AI和大算力芯片而言意味着什么?2024-07-08 1743
-
什么叫AI计算?AI计算力是什么?2023-08-24 8919
-
AIStaiton,有效提升大模型算力平台效率2023-06-30 1319
-
【AI简报第20230210期】 ChatGPT爆火背后、为AIoT和边缘侧AI喂算力的RISC-V2023-02-12 2215
-
解读最佳实践:倚天 710 ARM 芯片的 Python+AI 算力优化2022-12-23 1313
-
深度学习接近芯片算力极限?如何摆脱被淘汰的命运2020-10-30 881
-
深度学习正在逼近计算极限2020-07-21 1057
-
深度解析AI算力的现状和趋势2018-08-01 9563
全部0条评论

快来发表一下你的评论吧 !
