

tansformer的量化实现方案
电子说
描述
理论介绍
相比于训练后量化方法,将量化过程插入到训练中可以弥补量化产生的误差,但是带来的问题可能是增加了训练的时间。在tansformer的量化实现中,我们采用了训练中量化的方法,在网络前向传输中,对权重等参数进行线性量化。反向传播中,对scale和权重参数的求导采用Hinton的strait-through estimator的方式。在CPU上训练花费了10天的时间,在这期间又review了最近的量化方法的文章。所以先总结一下,然后再分析一下transformer量化的结果。
1) PACT
这是一种实现对activation量化的方法,基本思想是通过训练来获得ReLU的一个clip参数a。a的动态调整能够在减少量化误差和保证反向传播有效进行之间获得平衡。PACT重新定义了ReLU过程如下:
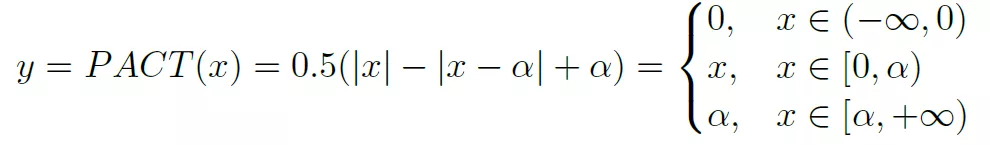
参数a限定了activation的范围为[0, a]。然后获得的激活值y在进行线性映射到k bit的表示空间,如下:
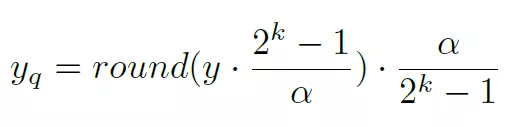
在这里[0, a]是y值的一个限定,a>=y。所以其范围比y值的实际范围要大,这可以对y的量化误差有一些弥补。采用strait-through estimator方法计算其相对于a的梯度为:
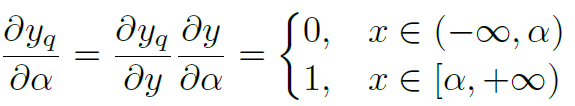
当a趋向于无穷大的时候,就接近于ReLU函数,所以训练过程一定是往a增大方向移动。通过在loss中增加a的L2 规范化可以寻求一个合适的a值。
2) quantization-aware training
谷歌采用量化和训练分离的方法,在前向计算使用量化数据,而在训练的时候还是浮点训练。量化方法为如下公式:
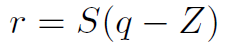
其中S为scale参数,z是零点偏移,q是量化后参数。Z值的存在会导致矩阵或者卷积运算中有交叉项。这会增加一部分加法和乘法项。这在CPU等通用处理器上容易实现,只是一个时间复杂度的问题,但是实际上不利于在FPGA等硬件上实现。所以FPGA等平台的量化一般都让z值为0。消除交叉项计算。对于一个矩阵乘法,量化导致了scale的组合,比如:
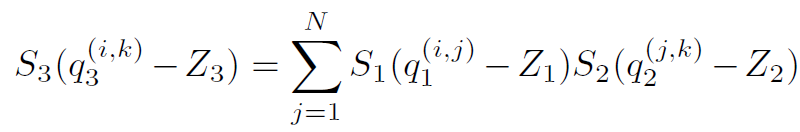
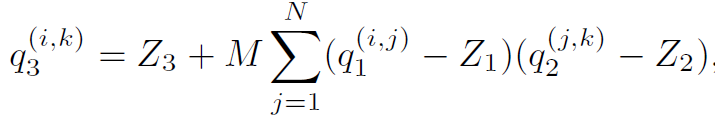
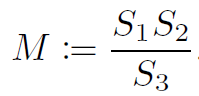
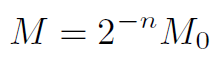
在这里M是浮点数据,在这里作者对其又做了一次量化,首先将M数据映射到[0.5, 1)空间,然后在使用32bit数据来表达为整数。
32bit的表达能够降低量化精度。
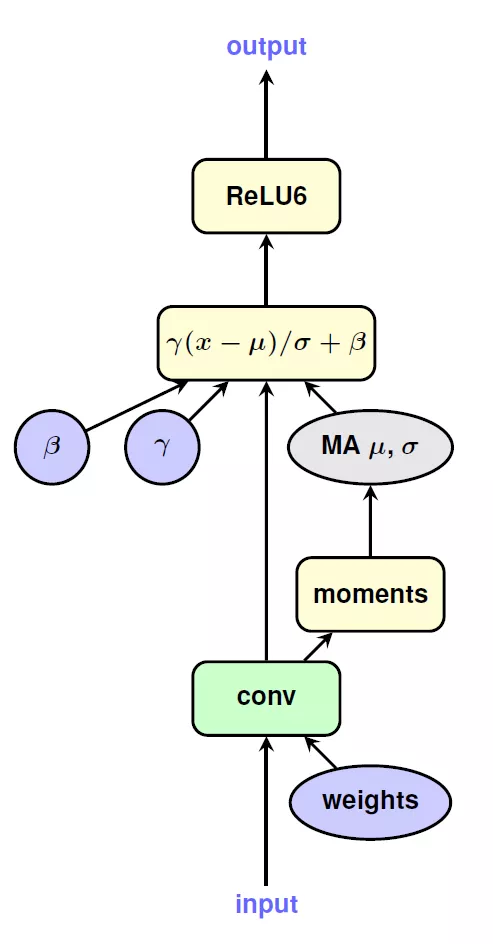
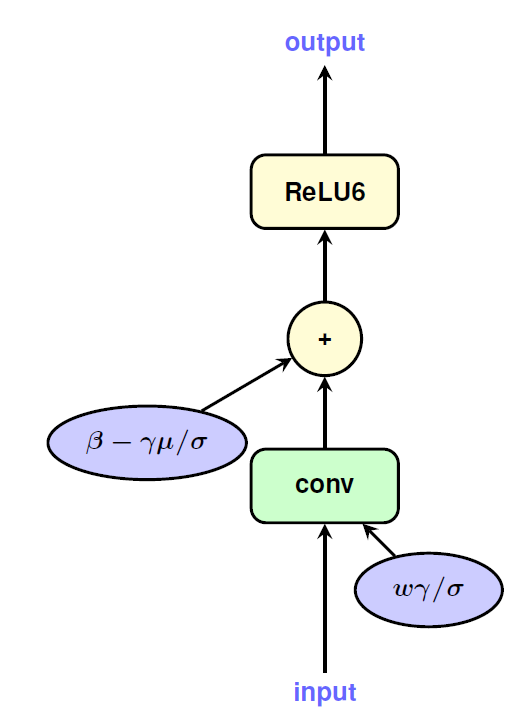
在量化整个网络的过程中,作者也提供了一些处理技巧。在进行线性量化的时候,采用了对称的量化区间,比如8bit量化,正常取值范围在[-128, 127],作者取了对称空间[-127, 127]。这样做的目的和实现的平台有关。在量化activation的时候,使用EMA来处理收集到的数值范围,这样做可以在初始训练中,完全屏蔽掉对activation的量化,使得训练进入到一个比较稳定的状态后在进行量化。BN是一个复杂的计算,但是可以将其折叠到之前的卷积层和FC层中,如下图所示:
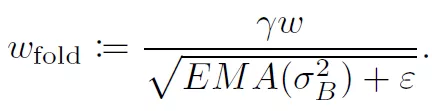
3) 训练后量化,基于KL发散性。
基于训练后的量化方法的优势就是量化花费时间短。在tensorRT中使用了KL发散性来描述量化后的数据和浮点数据之间的信息损失程度。通过最小化这个值来达到量化后数据包含的信息接近浮点数据的信息。这种方法的出发点是,为了保证量化后模型的精度损失较小,应该让量化后的数据和原始浮点数据表达的信息最一致。具体的做法是:
对每层网络,先收集activation的数值区间,这样就生成一个activation值的分布;采用不同的量化区间[a,b]来对activation进行线性映射,这样就形成了针对参数a和b的多种不同分布,然后找到和原始数据分布KL最小的分布,这个时候得到的a和b的值就是量化activation时所采用的threshold值。
Transformer量化结果
还是决定由简入难,先进行16bit的量化,量化内容包括transformer中的dense层,FC层。对权重和数据都进行16bit的量化,即将量化节点插入到计算图中。梯度采用strait-through estimator来估计。对于embedding,softmax,layer normalization还是使用浮点值。因为担心对这些的量化可能会导致精度降低。选择batch size为256,epoch为20,数据集使用英语德语翻译数据集。这个数据集有460万个句子。在服务器上使用CPU跑了10天,以下是结果:
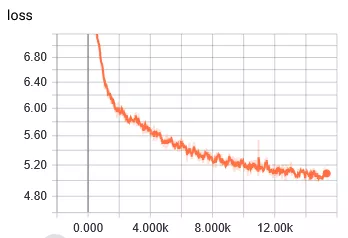
对比一下github上作者浮点模型的训练结果:
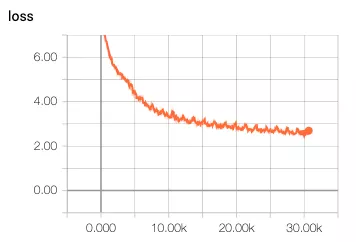
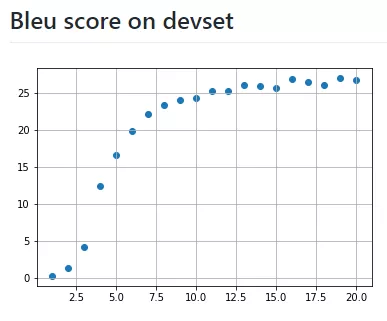
发现存在以下问题:
1 loss下降很慢,浮点模型在训练到达5k次的时候,loss已经下降到4了,但是量化的训练loss在5k次的时候才到5.4。经历了前几次快速下降之后,后边更加缓慢。
2 BLEU得分很低,训练了10K次后得分才有0.11。得分低的原因也是loss值很低。
第一次做没有什么经验,猜测可能有以下几种原因:
1 对所有的scale我都使用了常数2作为初始值,为什么选择2,并没有什么原因,就是随便选择的。或许初始值的不当导致了loss训练很慢。设想通过以下方式来改进,先进行warmup,通过计算参数的范围来计算出一个scale值。进行了几轮warmup之后再进行量化训练。
2 因为看到loss也一直是下降的趋势,那么猜测可能是量化训练是比正常训练收敛慢。因为量化参数的梯度在参数超过阈值会为0,这个可能导致梯度更新较慢。
编辑:hfy
- 相关推荐
- 热点推荐
- cpu
- Transformer
-
解读大模型FP量化的解决方案2023-11-24 1740
-
可实现批量化生产线性恒流驱动IC方案2015-11-20 3112
-
怎么在GUI中如何实现量化2016-05-26 3764
-
碳纤维为何能实现汽车轻量化?2018-01-25 4084
-
怎样分析量化过程及Verilog实现方法?2019-07-05 5631
-
请问怎样实现H.264的量化?2021-04-28 2172
-
INT8量化常见问题的解决方案2023-09-19 991
-
基于模糊规则的服装风格的区域量化与实现2009-08-15 680
-
数字马达控制系统的量化误差设计方案2010-03-12 972
-
非线性量化的模拟实现方法2011-06-22 614
-
如何使用FPGA实现微型SAR成像的量化显示2021-01-26 1284
-
深度解析MegEngine 4 bits量化开源实现2022-09-23 1789
-
浅谈轻量化设计:材料、创新技术及未来解决方案2023-01-29 2938
-
轻量化5G核心网的实现方式2023-06-20 2097
-
基于MacroBenchmark的性能测试量化指标方案2023-10-17 2114
全部0条评论

快来发表一下你的评论吧 !
