

FPGA上的HBM性能实测结果分析
电子说
描述
本文是第一篇详细介绍HBM在FPGA上性能实测结果的顶会论文(FCCM2020,Shuhai: Benchmarking High Bandwidth Memory on FPGAs),文章,目前采用Chiplet技术的光口速率可以达到惊人的2Tbps。而本文介绍的同样采用Chiplet技术的HBM,访存带宽高达425GB/s,那么采用这样光口和缓存的网卡会是一种怎样的高性能呢?对NIC或者Switch内部的总线带宽又有怎样的要求呢?我们期待着能够用2Tbps接口和HBM技术的NIC或者Switch的出现。
随着高带宽内存(HBM)的发展,FPGA正变得越来越强大,HBM 给了FPGA 更多能力去缓解再一些应用中遇到的内存带宽瓶颈和处理更多样的应用。然而,HBM 的性能表现我们了解地还不是特别精准,尤其是在 FPGA 平台上。这篇文章我们将会在HBM 的说明书和它的实际表现之间建立起桥梁。我们使用的是一款非常棒的 FPGA,Xilinx ALveo U280,有一个两层的HBM 子系统。在最后,我们提出了竖亥,一款让我们测试出所有HBM 基础性能的基准测试工具。基于FPGA 的测试平台相较于CPU/GPU 平台来说会更位准确,因为噪声会更少,后者有着复杂的控制逻辑和缓存层次。我们观察到 1)HBM 提供高达425 GB/s 的内存带宽,2)如何使用HBM 会给性能表现带来巨大的影响,这也印证了揭开 HBM 特性的重要性,这可以让我们选择最佳的使用方式。作为对照,我们同样将竖亥应用在DDR4上来展现DDR4 和HBM 的不同。竖亥可以被轻松部署在其他FPGA 板卡上,我们会将竖亥开源,造福社会。
1. 引言
现代计算机系统的计算能力随着 CMOS技术的发展持续提升,典型的例子就是应用更多的核心在同样的区域中或者增加额外的功能到核里面去(SIMD、AVX、SGX等)。与此相反,DRAM内存的带宽发展地十分缓慢。因此处理器和内存之间的差距越来越大,并且随着多核设计而变得更严重。HBM被提出用于提供高得多的带宽能力。HBM2 能提供高达900 GB/s 的内存带宽。
与同一代GPU相比,FPGA 带宽能力要低几个数量级,传统的FPGA有两个DRAM内存通道,每个提供19.2GB/s的内存带宽。因此FPGA不能完成很多对带宽能力要求高的应用。因此Xilinx将HBM引用到新一代FPGA中去。HBM有潜力成为改变目前局面的特性。
尽管有着潜力去解决处理器和内存间的差距,应用HBM到FPGA上还是有很多阻碍。HBM的特性不为人们所了解。尽管和DRAM有着相同的die,HBM的特性和前者完全不同。Xilinx的HBM子系统也引入了很多新特性例如switch。Switch的特性同样不为我们所了解。这些东西都会阻碍开发者利用FPGA上的HBM。
在最后我们提出了竖亥,一个可以用来测试HBM特性的基准测试工具。据我们所致,竖亥是第一个系统性测试FPGA上的HBM的测试平台。我们通过以下四个方面来证明竖亥的用处。
F1:HBM提供巨大的内存带宽:在我们的测试平台上,HBM提供高达425 GB/s的内存带宽,比传统使用两个DDR4来说要高一个数量级。虽然只有GPU的一半,但是这对FPGA来说也是一个巨大的进步。
F2:地址映射策略很重要:不同的地址映射策略会带来数量级的速度差异。这也意味着要根据应用的不同选取不同的映射策略。
F3:HBM延时要比DDR4高很多:HBM和FPGA的联系是通过transceiver,带来了额外的纠错码和串行并行转换的开销。竖亥测试出在页命中情况下,HBM的延时是122.2ns,而DDR4仅为73.3ns。
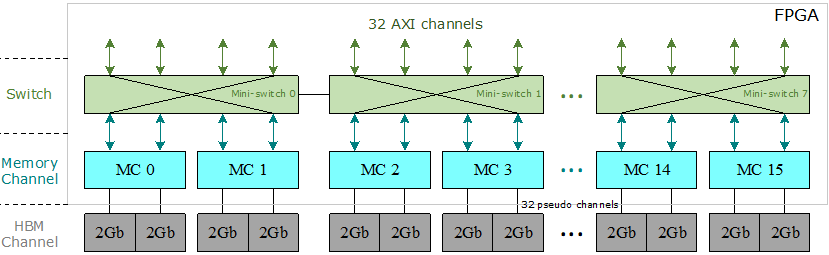
图1:Xilinx HBM子系统架构
F4:FPGA可以更精准地测量:我们将竖亥直接连接HBM模块,使得更容易解释测量结果,而使用CPU/GPU会引出更多的噪声,例如缓存的影响。因此我们主张竖亥是一个更好的选项来测量内存。
2. 背景
HBM芯片采用了最新的IC封装技术,例如直通硅通孔(TSV),堆叠式DRAM和2.5D封装[13],[18]。HBM的基本结构由底部的基本逻辑芯片和顶部堆叠的4或8核心DRAM芯片组成。所有管芯均通过TSV互连。Xilinx在FPGA内部集成了两个HBM堆栈和一个HBM控制器。每个HBM堆栈都分为八个独立的存储通道,其中每个存储通道又分为两个64位伪通道。如图1所示,只允许伪通道访问与其关联的HBM通道,该通道具有自己的内存地址区域。Xilinx的HBM子系统具有16个存储通道,32个伪通道和32个HBM通道。
在16个存储通道的顶部,有32个与用户逻辑交互的AXI通道。每个AXI通道均遵循标准AXI3协议[44],以向FPGA程序员提供经过验证的标准化接口。每个AXI通道都与一个HBM通道(或伪通道)相关联,因此每个AXI通道仅被允许访问其自己的内存区域。为了使每个AXI通道都能访问整个HBM空间,Xilinx引入了在32个AXI通道和32个伪通道之间的switch[41],[44]。但是,由于其巨大的资源消耗,该switch尚未完全实现。相反,Xilinx提供了八个小型switch,其中每个小型switch为四个AXI通道及其相关的伪通道提供服务,并且在每个AXI通道都可以访问同一小型switch中的任何伪通道,该小型switch被完全实现。具有相同的延迟和吞吐量。此外,两个相邻的微型switch之间有两个双向连接,用于全局寻址。
3. 竖亥的基本架构
在本节中,我们介绍设计方法,然后是竖亥的软件和硬件组件。
A.设计方法论
在本小节中,我们总结了两个具体挑战C1和C2,然后介绍竖亥如何来应对这两个挑战。
C1:高层洞察力。在某种意义上,使我们的基准测试框架对FPGA程序员有意义是至关重要的,因为我们应该轻松地向FPGA程序员提供更详尽的解释,而不是仅仅令人费解的内存时序参数(例如行预充电时间TRP),这可用于改善FPGA上HBM存储器的使用。
C2:易于使用。
在对FPGA进行基准测试时,可能需要做一些小改动才能重新配置FPGA,很难实现易用性。因此,我们打算最大程度地减少重新配置的工作,以使在基准测试任务之间无需重新配置FPGA。换句话说,我们的基准测试框架应该允许我们将一个FPGA实例用于大量的基准测试任务,而不仅仅是一个任务。
我们的方法。我们使用竖亥应对上述两个挑战。为了解决第一个挑战C1,竖亥允许直接分析FPGA程序员使用的典型存储器访问模式的性能特征,并提供整体性能的详尽说明。为了解决第二个挑战,即C2,竖亥使用基准电路的运行时参数化功能来覆盖各种基准测试任务,而无需重新配置FPGA。通过基准测试中实现的访问模式,我们可以揭示FPGA上HBM和DDR4的基本特性。
竖亥采用基于两个组件的软件-硬件协同设计方法:软件组件(III-B小节)和硬件组件(III-C小节)。软件组件的主要作用是在运行时参数方面为FPGA程序员提供灵活性。利用这些运行时参数,在对HBM和DDR4进行基准测试时,我们无需频繁地重新配置FPGA。硬件组件的主要作用是保证性能。更准确地说,竖亥应该能够在FPGA上展现HBM存储器在最大可实现的存储器带宽和最小可实现的延迟方面的性能潜力。为此,基准测试电路本身不能在任何时候成为瓶颈。
B.软件组件
竖亥的软件组件旨在提供用户友好的接口,以便FPGA开发人员可以轻松地使用竖亥来对HBM存储器进行基准测试并获得相关的性能特征。为此,我们介绍了一种广泛用于FPGA编程的存储器访问模式:重复顺序遍历(RST),如图2所示。

图2:在竖亥中使用的内存访问模式
RST模式遍历一个存储区域,一个数据阵列按顺序存储数据元素。RST重复扫描起始地址为A的大小为W的存储区域,并且每次读取步长为S字节的B个字节,其中B和S为2的幂。在我们测试的FPGA上,访问大小B应为由于HBM / DDR4存储器应用程序数据宽度的限制,对于HBM(或DDR4),其值不得小于32(或64)。步幅S不应大于工作集大小W。参数汇总在表I中。我们计算出RST发出的第i个存储器读/写事务的地址T [i],如公式1所示。可以使用简单的算法来实现计算,从而减少了FPGA资源的数量,并可能实现更高的频率。尽管这公式非常简单,但是它能帮助我们了解FPGA上的HBM和DDR。
表格1:运行时参数总结

T[i] = A + (i × S)%W 公式(1)
C.硬件组件
竖亥的硬件组件由一个PCIe模块,M个延迟模块,一个参数模块和M个引擎模块组成,如图3所示。在下面,我们讨论每个模块的实现细节。
1)引擎模块:我们直接将实例化的引擎模块连接到AXI通道,以便引擎模块直接服务于AXI接口,例如AXI3和AXI4 [2],[42],它由基础内存IP核提供,HBM和DDR4。AXI接口包含五个不同的通道:读取地址(RA),读取数据(RD),写入地址(WA),写入数据(WD)和写入响应(WR)[42]。此外,引擎模块的输入时钟正是来自相关AXI通道的时钟。例如,在对HBM进行基准测试时,引擎模块的时钟频率为450MHz,因为其AXI通道最多允许450MHz。使用同一时钟有两个好处。首先,跨不同时钟区域所需的FIFO不会引入额外的噪声,例如更长的延迟。其次,引擎模块能够容纳其关联的AXI通道,不会导致内存带宽容量的低估。
用Verilog编写的引擎模块由两个独立的模块组成:写入模块和读取模块。写模块为三个与写相关的通道WA,WD和WR提供服务,而读模块为两个与读相关的通道RA和RD提供服务。
写模块。该模块包含一个状态机,该状态机可以从CPU执行内存写入任务。该任务具有初始地址A,写入数N,访问大小B,步幅S和工作集大小W。公式1中指定了每个存储器写事务的地址。该模块还探测WR通道,以验证动态存储器写的工作已成功完成。
读取模块。读取模块包含一个状态机,该状态机可以从CPU中执行内存读取任务。该任务具有初始地址A,读取事务数N,访问大小B,幅度S和工作集大小W。与写入模块不同,写入模块仅测量可实现的吞吐量,读取模块还测量每个模块的延迟。当测试速度时,该模块会一直尝试满足RA和RD。
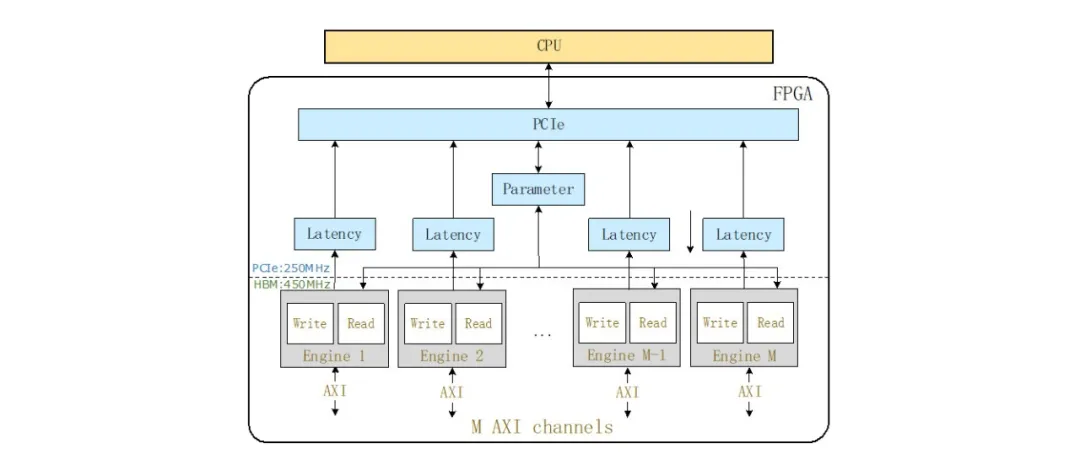
图3:总硬件架构,支持M个硬件引擎同时运行,在我们的实验中,M是32
2)PCIe模块:我们直接在时钟频率为250MHz的PCIe模块中部署了用于PCI Express(PCIe)IP内核的Xilinx DMA/桥接子系统。我们的PCIe驱动程序将FPGA上的运行时参数映射给用户,以便用户能够使用软件代码直接与FPGA交互。这些运行时参数决定存储在参数模块中的控制和状态寄存器。
3)参数模块:参数模块维护运行时参数并通过PCIe模块与主机CPU通信,从CPU接收运行时参数(例如S),并将吞吐量数据返回给CPU。
收到运行时参数后,我们将使用它们来配置M个引擎模块,每个引擎模块都需要两个256位控制寄存器来存储其运行时参数:每个引擎模块中的一个寄存器用于读取模块,另一个寄存器用于写入模块。在256位寄存器中,W占用32位,S占用32位,N占用64位,B占用32位,而A占用64位。剩余的32位保留供将来使用。设置完所有引擎之后,用户可以触发启动信号以开始吞吐量/延迟测试。
参数模块还负责将吞吐量编号(64位状态寄存器)返回给CPU。每个引擎模块专用一个状态寄存器。
4)延迟模块:我们为专用于AXI通道的每个引擎模块实例化一个延迟模块。等待时间模块存储大小为1024的等待时间列表,其中等待时间列表由关联的引擎模块写入并由CPU读取。它的大小是一个综合参数。每个包含一个8位寄存器的等待时间,指从读取操作的发出到数据从存储控制器到达操作的延迟。
4. 实验设置
在本节中,我们介绍经过测试的硬件平台(第IV-A小节)和探讨的地址映射策略(第IV-B小节),然后是硬件资源消耗(第IV-C小节)和我们的基准测试方法(IV-D小节)。
A.硬件平台
我们在Xilinx的Alevo U280 [43]上进行实验,该实验具有两个总容量为8GB的HBM堆栈和两个总容量为32GB的DDR4内存通道。理论HBM内存带宽可以达到450 GB / s(450M * 32 * 32B / s),而DDR4内存理论带宽可以达到38.4GB / s(300M * 2 * 64B / s)。
B.地址映射政策
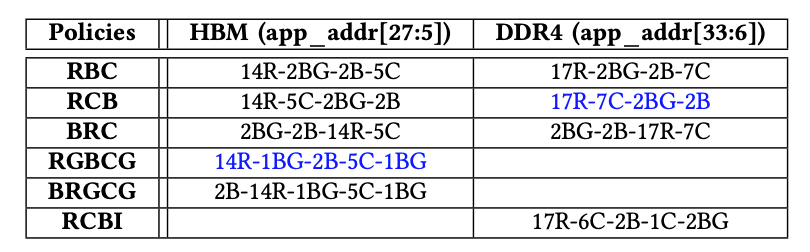
可以使用多种策略将应用程序地址映射到内存地址,其中不同的地址位映射到存储块,行或列地址。选择正确的映射策略对于最大化整体内存吞吐量至关重要。表II中汇总了为HBM和DDR4启用的策略,其中“ xR”表示x位用于行地址,“xBG”表示x位用于存储体组地址,“ xB”表示x位用于存储体地址,“ xC”表示x位用于列地址。HBM和DDR4的默认策略分别为“RGBCG”和“ RCB”。“-”代表地址串联。如果没有特别指定,我们始终对HBM和DDR4使用默认的内存地址映射策略。例如,HBM的默认策略是RGBCG。
表格2:地址映射策略,蓝色的是默认
C.资源消耗明细
在本小节中,我们将叙述7种资源的消耗。
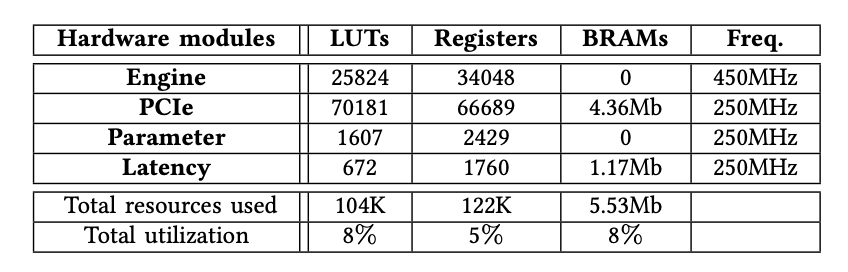
对HBM进行基准测试时,表III列出了每个实例化模块的确切FPGA资源消耗。我们观察到,竖亥只需要少量的资源来实例化32个引擎模块以及PCIe模块等其他组件,总资源利用率不到8%。
表格3:资源消耗量
D.测试方法
我们旨在揭示竖亥使用下Xilinx FPGA上的HBM堆栈的底层细节。作为衡量标准,我们在必要时还分析了同一FPGA板U280上DDR4的性能特征[43]。当我们对HBM通道进行基准测试时,我们将HBM和DDR4的性能特征进行了比较(在第五节中)。我们认为,针对HBM通道获得的数字可以推广到其他计算设备,例如具有HBM内存的CPU或GPU。在HBM内存控制器内部对switch进行基准测试时,由于DDR4内存控制器不包含,因此我们不与DDR进行比较(第六节)。
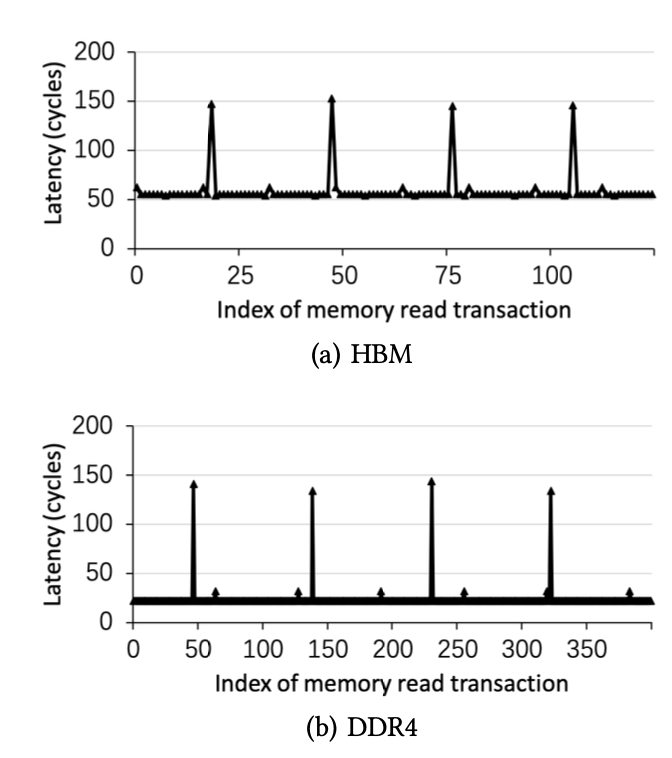
图4:刷新指令带来更高的访问延时周期性地出现在HBM和DDR4中
5. 对HBM通道进行基准测试
在本节中,我们旨在揭示Xilinx FPGA上使用Shuhai的HBM通道的详细信息。
A.刷新间隔的影响
当存储通道正在运行时,应重复刷新存储单元,以使每个存储单元中的信息都不会丢失。在刷新周期中,不允许正常的内存读取和写入事务访问内存。我们观察到,经历内存刷新周期的内存事务比允许直接访问内存芯片的普通内存读/写事务的等待时间长得多。因此,我们能够通过利用正常和非刷新内存事务之间的内存延迟差异来大致确定刷新间隔。特别地,我们利用竖亥来测量串行存储器读取操作的延迟。图4说明了B = 32,S = 64,W = 0x1000000和N = 20000的情况。我们有两个观察结果。首先,对于HBM和DDR4,与刷新命令一致的存储器读取事务具有显着更长的延迟,这表明需要发出足够多的动态存储器事务来分摊刷新命令的负面影响。其次,对于HBM和DDR4,都定期计划刷新命令,任何两个连续刷新命令之间的间隔大致相同。
B.内存访问延迟
为了准确地测量内存延迟,当内存控制器处于“空闲”状态时,即内存控制器中不存在其他未决内存事务的情况下,我们利用竖亥来测量连续内存读取事务的延迟。以最小的延迟将请求的数据返回到读取的事务。我们旨在确定三种不同状态下的延迟:page hit、page miss、page closed。
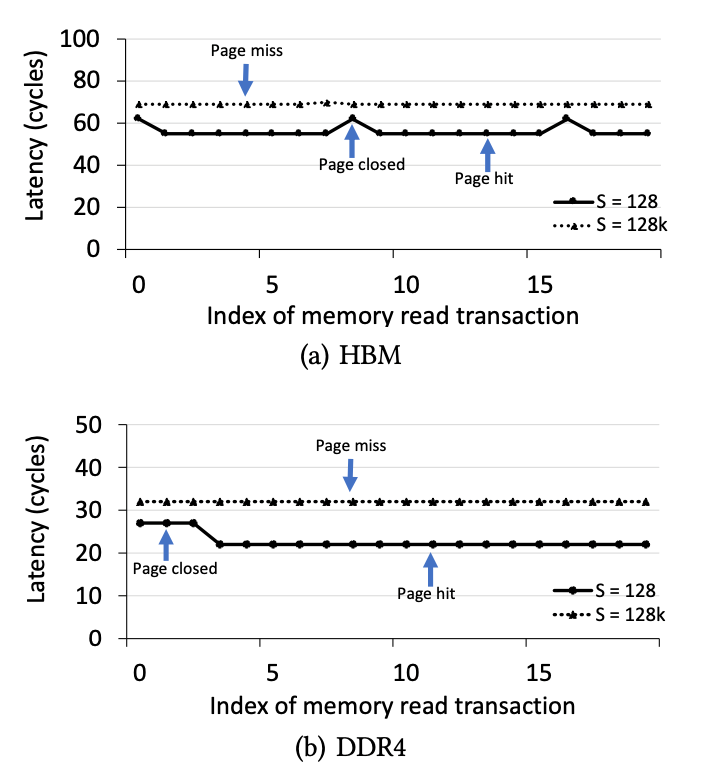
图5.三种状态(page hit、page closed、page miss)的延时
PageHit(页面命中):当内存事务访问其存储区中打开的行时,将发生“页面命中”状态,因此在访问列之前不需要“预充电”和“激活”命令,从而将等待时间降至最低。
PageClosed(页面关闭):当内存事务访问其对应存储体已关闭的行时,将发生“页面关闭”状态,因此在访问列之前需要行Activate命令。
PageMiss(页面丢失):当内存事务访问的行与存储区中的活动行不匹配时,将发生“页面丢失”状态,因此在访问列之前发出了一个Precharge命令和一个Activate命令,这导致了最大的延迟。
我们准确测量B = 32,W = 0x1000000,N = 2000且S发生变化的情况下的等待时间数。直观地讲,小S导致击中同一页面的可能性很高,而大S可能导致击中同一页面错过页面。在本实验中,我们使用两个S值:128和128K。
我们使用情况S = 128来确定页面命中和页面关闭事务的等待时间。S = 128小于页面大小,因此大多数读取事务将访问一个打开的页面,如图5所示。其余点说明页面关闭事务的等待时间,因为小S导致大量读取特定内存区域中的事务。我们使用S = 128K的情况来确定页面丢失事务的等待时间。S = 128K导致HBM和DDR4的每个内存事务发生页面丢失。
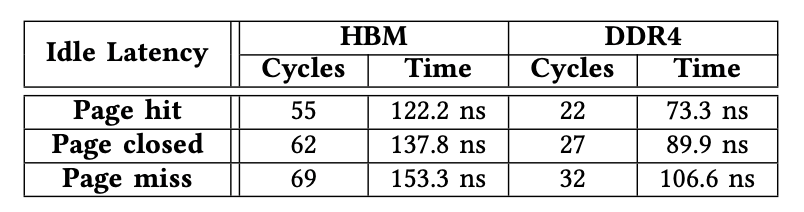
总结:我们在表IV中总结了HBM和DDR的延迟。我们有两个观察结果。首先,在相同的类别(如页面点击)下,HBM上的内存访问延迟比DDR4上高约50纳秒。这意味着当在FPGA上运行对延迟敏感的应用程序时,HBM可能有劣势。其次,延迟数是准确的,证明了竖亥的效率。
表格4.HBM和DDR4的内存访问,HBM的延时要高于DDR4
C.地址映射策略的效果
在本小节中,我们研究了不同内存地址映射策略对可实现吞吐量的影响。特别地,在不同的映射策略下,我们使用步幅S和访问大小B来测量内存吞吐量,同时将工作集大小W(= 0x10000000)保持足够大。图6说明了HBM和DDR4的不同地址映射策略的吞吐量趋势。我们有五个观察到的现象。
首先,不同的地址映射策略会导致明显的性能差异。例如,图6a说明,当S为1024而B为32时,HBM的默认策略(RGBCG)几乎比策略(BRC)快10倍,这说明为内存应用程序选择正确的地址映射策略的重要性。
其次,即使HBM和DDR4采用相同的地址映射策略,其吞吐量趋势也大不相同,这证明了竖亥等基准平台对评估不同的FPGA板或不同的存储器的重要性。
第三,对于HBM和DDR4上的S和B的任何组合,默认策略始终会带来最佳性能,这表明默认设置是合理的。
第四,较小的访问大小导致较低的存储器吞吐量,如图6a,6e所示,这意味着FPGA程序员应增加空间局部性,以从HBM和DDR4获得更高的存储器吞吐量。
第五,大的S(> 8K)总是导致内存带宽利用率极低,这表明保持空间局部性极为重要。换句话说,不保留空间局部性的随机内存访问将遇到低内存吞吐量。
我们得出结论,选择正确的地址映射策略对于优化FPGA上的存储器吞吐量至关重要。
D.储存组的影响
在本小节中,我们研究了存储组的影响,与DDR3相比,存储组是DDR4的新功能。同时访问多个存储组有助于我们减轻DRAM时序限制的负面影响,而这种限制在几代DRAM上并未得到改善。通过访问多个存储组可能会获得更高的内存吞吐量。因此,我们使用引擎模块来验证储存组的效果(图6)。我们有两个观察到的结果。
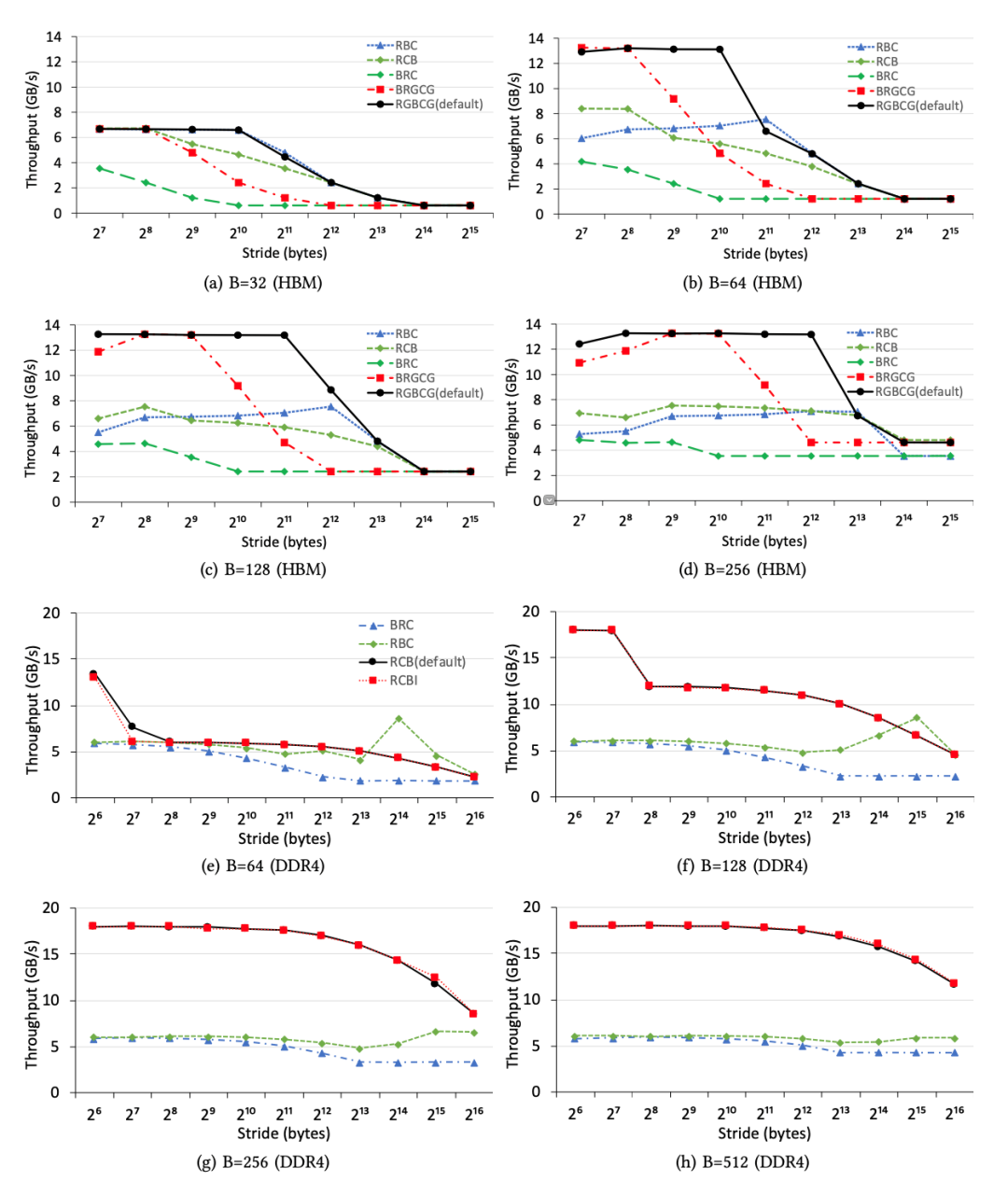
图6.在所有地址映射策略下,具有不同访问大小和跨度的HBM通道和DDR4通道之间的内存吞吐量比较。在本实验中,我们使用AXI通道0访问其关联的HBM通道0,以从单个HBM通道获得最佳性能。我们使用DDR4通道0获得DDR4吞吐量数字。我们观察到,不同的地址映射策略会导致性能最高提高一个数量级,并且就吞吐量趋势而言,HBM的性能特征与DDR4的性能特征不同。
首先,如图6a,6b,6c,6d所示,使用默认地址映射策略,HBM允许使用较大步幅,同时仍保持高吞吐量。根本原因是,即使由于大的S而没有充分利用每个行缓冲区,存储组级并行性也能够使我们饱和利用内存带宽。
其次,在某些映射策略下,纯顺序读取并不总是导致最高吞吐量。图6b,6c说明,当S从128增加到2048时,较大的S在策略“ RBC”下可以实现较高的内存吞吐量,因为较大的S允许同时访问更多激活的存储组,而较小的S可能导致仅一个活动的储存组响应用户的存储请求。
我们得出结论,在HBM和DDR4下利用储存组级并行性来实现高内存吞吐量至关重要。
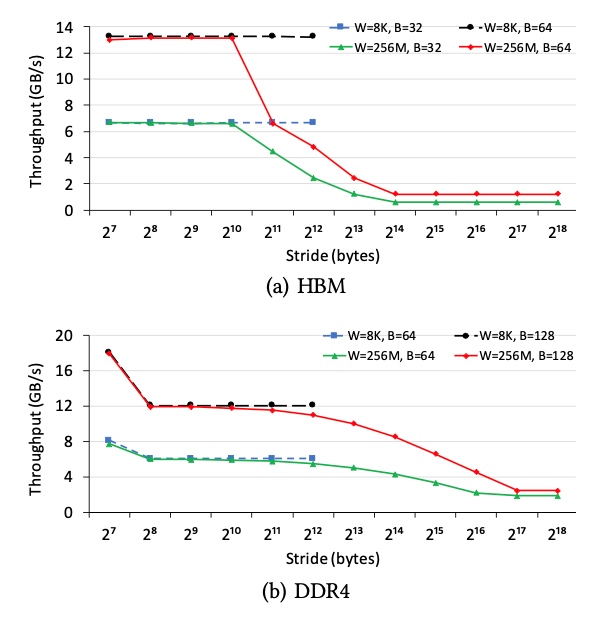
图7.空间局部性的影响,局部性能缓解大的步幅S的影响
E.内存访问局部性的影响
在本小节中,我们研究了内存访问局部性对内存吞吐量的影响。我们更改访问大小B和步幅S,并将工作集大小W设置为两个值:256M和8K。W = 256M的情况是指无法从任何内存访问局部性受益,而W = 8K的情况是指受益的情况。图7说明了HBM和DDR4上不同参数设置的吞吐量。我们有两个观察结果。
首先,内存访问局部确实提高了大的S的情况下的内存吞吐量。例如,在HBM上,(B = 32,W = 8K和S = 4K)情况下速度为6.7 GB / s,而(B = 32,W= 256M和S = 4K)仅为2.4 GB / s,这表明内存访问位置能够消除较大步幅S的负面影响。其次,当S较小时,内存访问局部性不能增加内存吞吐量。相比之下,由于片上缓存的带宽比片外存储器要高得多,因此内存访问局部性可以显著提高现代CPU / GPU的总吞吐量[19]。
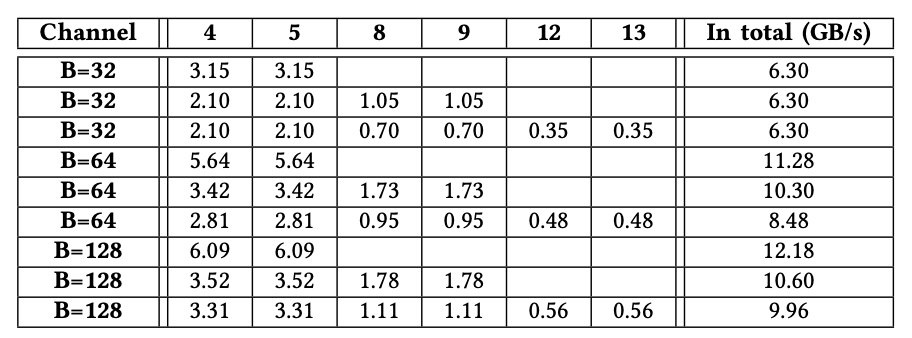
F.总内存吞吐量
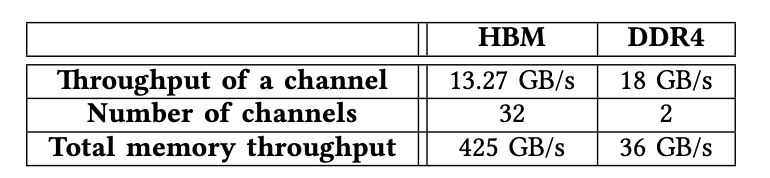
在本小节中,我们探讨了HBM和DDR4的总可实现内存吞吐量(表V)。当我们使用所有32条AXI通道进行测试时,经过测试的FPGA卡U280上的HBM系统能够提供高达425GB / s(13.27 GB / s * 32)的内存吞吐量。
当我们同时访问经过测试的FPGA卡上的两个DDR4通道时,内存能够提供高达36 GB / s(18 GB / s * 2)的内存吞吐量。我们观察到,HBM系统的内存吞吐量是DDR4内存的10倍,这表明增强了HBM的FPGA使我们能够加速内存密集型应用程序,而这通常是在GPU上进行加速的。
表格5.HBM和DDR4访问速度对比,HBM要快一个数量级
6. 在HBM控制器中对switch进行基准测试
每个HBM堆栈将内存地址空间划分为16个独立的伪通道,每个伪通道均与映射到特定地址范围[41],[44]的AXI端口相关。因此,需要使用32×32开关来确保每个AXI端口都可以访问整个地址。在HBM存储器控制器中完全实现的32×32开关需要大量逻辑资源。因此,该switch仅被部分实现,从而显着减少了资源消耗,但实现了特定访问模式的较低性能。我们在本节中的目标是揭示switch的性能特征。
A.AXI通道和HBM通道之间的性能
在本小节中,我们将在时延和吞吐量方面测试任何一个AXI通道和任何HBM通道之间的性能特征。在完全实现的switch中,从任何AXI通道访问任何HBM通道的性能特征都应该大致相同。但是,在当前的实现中,相对距离可能起着重要的作用。
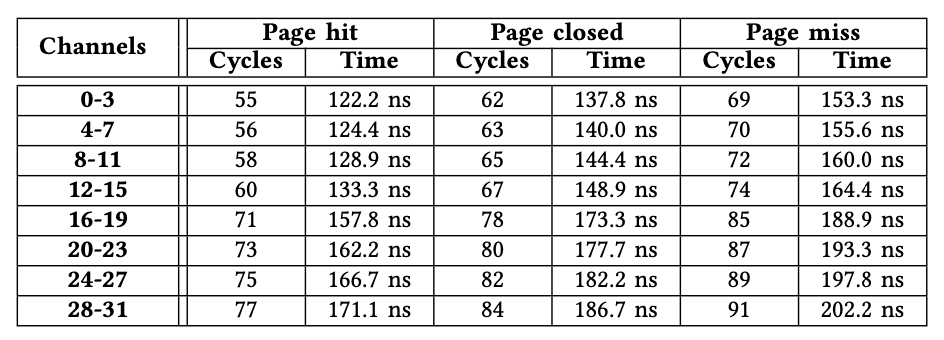
1)内存延迟:由于篇幅所限,我们仅使用所有AXI通道(从0到31)到HBM通道0发出的内存读取事务来演示内存访问延迟。对其他HBM通道的访问具有相似的性能特征。与V-B小节中的实验设置相似,我们还使用引擎模块来确定B = 32,W = 0x1000000,N = 2000以及S变化的情况下的准确等待时间。表VI说明了32个AXI通道之间的等待时间差异。我们有两个观察结果。
首先,延迟差异最多可以达到22个周期。例如,对于页面命中事务,来自AXI通道31的访问需要77个周期,而来自AXI通道0的访问仅需要55个周期。其次,来自同一微型switch中任何AXI通道的访问等待时间是相同的,这表明该微型switch已完全实现。例如,与AXI通道4-7关联的微型switch对所有通道都显示相同的内存访问延迟。我们得出结论,AXI通道应访问其关联的HBM通道或靠近它的HBM通道,以最大程度地减少延迟。
表格6.从32个AXI通道访问HBM通道0的延时,距离越远延时越高,可以达到22个周
2)内存吞吐量:我们使用引擎模块来测量从任何AXI通道(从0到31)到HBM通道0的内存吞吐量,设置为B =64,W = 0x1000000,N = 200000,并且改变S。图8说明了从每个小型switch中的AXI通道到HBM通道0的内存吞吐量。我们观察到AXI通道能够实现大致相同的内存吞吐量,而不管它们的位置如何。
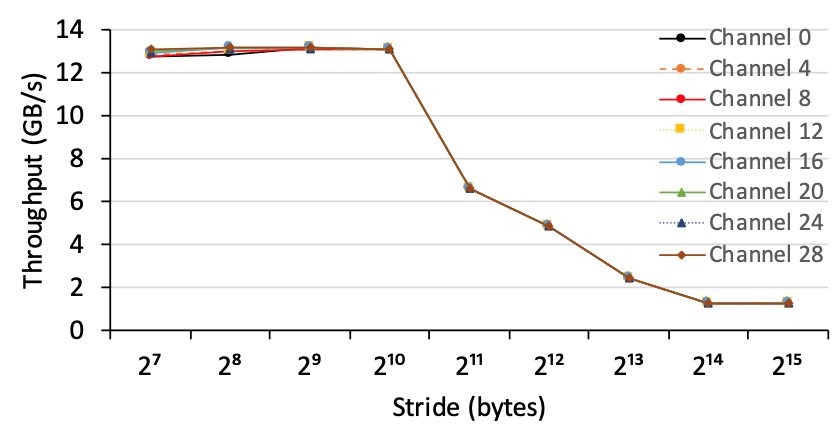
图8,从八个AXI通道到HBM通道1的内存吞吐量,其中每个AXI通道都来自小switch。每个AXI通道在访问HBM通道1时具有大致相同的吞吐量,即使它们的访问延迟可能明显不同
B.AXI通道之间的干扰
在本小节中,我们通过使用不同数量(例如2、4和6)的AXI通道同时访问同一HBM通道1,来检查AXI通道之间的干扰影响。我们还改变了B的大小。表VII显示了具有不同的B值和不同的AXI通道的吞吐量。空值表示该AXI通道未参与吞吐量测试。我们有两个观察结果。首先,当远程AXI通道数量增加时,总吞吐量会略有下降,这表明交换机能够以合理有效的方式为多个AXI通道提供内存事务。其次,以循环方式安排微型switch中的两个横向连接和四个主机。以AXI通道4、5、8和9同时访问且B = 32的情况为例,远程AXI通道8和9的总吞吐量大致等于AXI通道4或5的总吞吐量。
7. 相关工作
就我们所知,竖亥是第一个全面地在FPGA上对HBM进行基准测试的平台。我们将与竖亥密切相关的工作进行对比:1)在FPGA上对传统存储器进行基准测试;2)使用HBM进行数据处理;3)加速FPGA的应用。
表格7.远程AXI通道之间的冲突影响。我们使用不同数量(2、4或6)的远程AXI通道来访问HBM通道1,以测量吞吐量(GB / s)。当远程AXI通道的数量为2时,AXI通道4和5处于活动状态 。当仅使用本地AXI通道1访问HBM通道1时,对于B = 32,B = 64或B =128的情况,吞吐量为6.67、12.9或13.3 GB / s。空值表示相应的AXI通道 不参与特定的基准测试。
在FPGA上对传统内存进行基准测试。先前的工作[20],[22],[23],[47]试图通过使用高级语言(例如OpenCL)在FPGA上对传统存储器(例如DDR3)进行基准测试。相反,我们在最先进的FPGA上对HBM进行基准测试。
使用HBM/ HMC进行数据处理。先前的工作[4],[6],[15],[16],[21],[26],[27],[46]使用HBM来加速其应用,例如哈希表深度学习和流式传输通过利用Intel KnightsLanding(KNL)的HBM [12]提供的高内存带宽。相比之下,我们在Xilinx FPGA板上测试了HBM的性能。
使用FPGA加速应用程序。先前的作品[1],[3],[5],[7],[8],[9],[10],[11],[14],[17],[24],[25], [28],[29],[30],[31],[32],[33],[34],[35],[36],[37],[38],[39],[40] ] [45]使用FPGA加速了广泛的应用,例如数据库和深度学习推理。相反,无论应用如何,我们都在最新的FPGA上系统地对HBM进行基准测试。
8. 结论
高带宽存储器(HBM)增强了FPGA,以解决IO密集应用程序的存储器带宽瓶颈。但是,HBM的性能特征仍未在FPGA上进行定量和系统的分析。我们通过在具有两层HBM2子系统的最新FPGA上对HBM堆栈进行基准测试来揭秘。相应的,我们建议使用竖亥来对HBM的基本细节进行测试。从获得的基准测试数据中,我们观察到:1)HBM提供高达425 GB / s的内存带宽,大约是最新GPU的内存带宽的一半,2)如何使用HBM对性能有着显著影响,这反过来证明了揭露HBM特征的重要性。竖亥可以很容易地推广到其他FPGA板或其他的存储器模块。我们将使相关的基准测试代码开源,以便可以探索新的FPGA板并比较各个板的结果。
源代码链接:https://github.com/RC4ML/Shuhai 。
9. 参考文献
[1]Altera. Guidance for Accurately Benchmarking FPGAs, 2007.
[2]Arm. AMBA AXI and ACE Protocol Specification, 2017.
[3]M. Asiatici and P. Ienne. Stop crying over your cache miss rate:
Handlingefficiently thousands of outstanding misses in fpgas. In FPGA,
2019.
[4]B. Bramas. Fast Sorting Algorithms using AVX-512 on Intel Knights
Landing.CoRR, 2017.
[5]E. Brossard, D. Richmond, J. Green, C. Ebeling, L. Ruzzo, C. Olson, and
S.Hauck. A model for programming data-intensive applications on
fpgas:A genomics case study. In SAAHPC, 2012.
[6]X. Cheng, B. He, E. Lo, W. Wang, S. Lu, and X. Chen. Deploying hash
tableson die-stacked high bandwidth memory. In CIKM, 2019.
[7]Y.-k. Choi, J. Cong, Z. Fang, Y. Hao, G. Reinman, and P. Wei. A QuantitativeAnalysis on Microarchitectures of Modern CPU-FPGA
Platforms.In DAC, 2016.
[8]Y.-K. Choi, J. Cong, Z. Fang, Y. Hao, G. Reinman, and P. Wei. In-Depth
Analysison Microarchitectures of Modern Heterogeneous CPU-FPGA
Platforms.ACM Trans. Reconfigurable Technol. Syst., 2019.
[9]J. Fowers, K. Ovtcharov, K. Strauss, E. S. Chung, and G. Stitt. A high memory bandwidthfpga accelerator for sparse matrix-vector
multiplication.In FCCM, 2014.
[10]Q. Gautier, A. Althoff, Pingfan Meng, and R. Kastner. Spector: An
OpenCLFPGA benchmark suite. In FPT, 2016.
[11]Z. Istva ́n, D. Sidler, and G. Alonso. Runtime parameterizable regular
expressionoperators for databases. In FCCM, 2016.
[12]Jim Jeffers and James Reinders and Avinash Sodani. Intel Xeon Phi
ProcessorHigh Performance Programming Knights Landing Edition,
2016.
[13]H. Jun, J. Cho, K. Lee, H. Son, K. Kim, H. Jin, and K. Kim. Hbm (high
bandwidthmemory) dram technology and architecture. In IMW, 2017.
[14]S. Jun, M. Liu, S. Xu, and Arvind. A transport-layer network for
distributedfpga platforms. In FPL, 2015.
[15]S. Khoram, J. Zhang, M. Strange, and J. Li. Accelerating graph analytics
byco-optimizing storage and access on an fpga-hmc platform. In FPGA,
2018.
[16]A. Li, W. Liu, M. R. B. Kristensen, B. Vinter, H. Wang, K. Hou,
A.Marquez, and S. L. Song. Exploring and Analyzing the Real Impact
ofModern On-Package Memory on HPC Scientific Kernels. In SC, 2017.
[17]Z. Liu, Y. Dou, J. Jiang, Q. Wang, and P. Chow. An fpga-based processor
fortraining convolutional neural networks. In FPT, 2017.
[18]J. Macri. Amd’s next generation gpu and high bandwidth memory
architecture:Fury. In Hot Chips, 2015.
[19]S. Manegold, P. Boncz, and M. L. Kersten. Generic database cost models
forhierarchical memory systems. In PVLDB, 2002.
[20]K.Manev,A.Vaishnav,andD.Koch.Unexpecteddiversity:Quantitative
memoryanalysis for zynq ultrascale+ systems. In FPT, 2019.
[21]H. Miao, M. Jeon, G. Pekhimenko, K. S. McKinley, and F. X. Lin. Streambox-hbm:Stream analytics on high bandwidth hybrid memory.
InASPLOS, 2019.
[22]S. W. Nabi and W. Vanderbauwhede. Mp-stream: A memory perfor-
mancebenchmark for design space exploration on heterogeneous hpc
devices.In IPDPSW, 2018.
[23]S. W. Nabi and W. Vanderbauwhede. Smart-cache: Optimising memory
accessesfor arbitrary boundaries and stencils on fpgas. In IPDPSW, 2019.
[24]M. J. H. Pantho, J. Mandebi Mbongue, C. Bobda, and D. Andrews. Trans- parentAcceleration of Image Processing Kernels on FPGA-Attached Hybrid Memory CubeComputers. In FPT, 2018.
[25]H. Parandeh-Afshar, P. Brisk, and P. Ienne. Efficient synthesis of compressortrees on fpgas. In ASP-DAC, 2008.
[26]I. B. Peng, R. Gioiosa, G. Kestor, P. Cicotti, E. Laure, and S. Markidis.Exploring the performance benefit of hybrid memory system on hpc environments.In IPDPSW, 2017.
[27]C. Pohl and K.-U. Sattler. Joins in a heterogeneous memory hierarchy:Exploiting high-bandwidth memory. In DAMON, 2018.
[28]N. Ramanathan, J. Wickerson, F. Winterstein, and G. A. Constantinides. A casefor work-stealing on fpgas with opencl atomics. In FPGA, 2016.
[29]S. Taheri, P. Behnam, E. Bozorgzadeh, A. Veidenbaum, and A. Nicolau. Affix:Automatic acceleration framework for fpga implementation of
openvxvision algorithms. In FPGA, 2019.
[30]D. B. Thomas, L. Howes, and W. Luk. A Comparison of CPUs, GPUs,
FPGAs,and Massively Parallel Processor Arrays for Random Number
Generation.In FPGA, 2009.
[31]S. I. Venieris and C. Bouganis. fpgaconvnet: A framework for mapping
convolutionalneural networks on fpgas. In FCCM, 2016.
[32]J. Wang, Q. Lou, X. Zhang, C. Zhu, Y. Lin, and D. Chen. Design flow ofaccelerating hybrid extremely low bit-width neural network
inembedded fpga. In FPL, 2018.
[33]Z.Wang,B.He,andW.Zhang.AstudyofdatapartitioningonOpenCL-
basedFPGAs. In FPL, 2015.
[34]Z. Wang, B. He, W. Zhang, and S. Jiang. A performance analysis
frameworkfor optimizing OpenCL applications on FPGAs. In HPCA,
2016.
[35]Z. Wang, K. Kara, H. Zhang, et al. Accelerating Generalized Linear
Modelswith MLWeaving: A One-size-fits-all System for Any-precision
Learning.VLDB, 2019.
[36]Z. Wang, J. Paul, H. Y. Cheah, B. He, and W. Zhang. Relational query
processingon OpenCL-based FPGAs. In FPL, 2016.
[37]Z. Wang, J. Paul, B. He, and W. Zhang. Multikernel data partitioning
withchannel on OpenCL-based FPGAs. TVLSI, 2017.
[38]Z. Wang, S. Zhang, B. He, and W. Zhang. Melia: A MapReduce
frameworkon OpenCL-based FPGAs. TPDS, 2016.
[39]J. Weberruss, L. Kleeman, D. Boland, and T. Drummond. Fpga
accelerationof multilevel orb feature extraction for computer vision.
InFPL, 2017.
[40]G. Weisz, J. Melber, Y. Wang, K. Fleming, E. Nurvitadhi, and J. C. Hoe.
Astudy of pointer-chasing performance on shared-memory processor-
fpgasystems. In FPGA, 2016.
[41]M. Wissolik, D. Zacher, A. Torza, and B. Day. Virtex UltraScale+ HBM
FPGA:A Revolutionary Increase in Memory Performance, 2019.
[42]Xilinx. AXI Reference Guide, 2011.
[43]Xilinx. Alveo U280 Data Center Accelerator Card Data Sheet, 2019.
[44]Xilinx. AXI High Bandwidth Memory Controller v1.0, 2019.
[45]Q. Xiong, R. Patel, C. Yang, T. Geng, A. Skjellum, and M. C. Herbordt.
Ghostsz:A transparent fpga-accelerated lossy compression framework.
InFCCM, 2019.
[46]Y. You, A. Bulu ̧c, and J. Demmel. Scaling deep learning on gpu and
knightslanding clusters. In SC, 2017.
[47]H. R. Zohouri and S. Matsuoka, “The memory controller wall: Bench-marking the intel fpga sdk for opencl memory interface,” in H2RC, 2019.
-
一种基于FPGA的任意锁相倍频算法2013-12-04 5477
-
基于FPGA的简易数字信号传输性能分析仪2015-12-21 4590
-
追求性能提升 使用8GB HBM2显存2016-12-07 4413
-
请问AD9257实测性能多少?2019-01-16 2690
-
HBM传感器的安装2020-06-19 3206
-
关于FPGAs的DSP性能分析2021-05-07 1852
-
探究GDDR6给FPGA带来的大带宽存储优势以及性能测试(上)2021-12-21 6029
-
FPGA上同步开关噪声的分析2010-04-12 3608
-
FPGA芯片追求性能提升 使用8GB HBM2显存2016-11-10 7519
-
分析上拉电阻不同在FPGA上电配置过程中造成的不同影响2017-11-15 9347
-
不同场景的FPGA外围电路的上电时序分析与设计2017-11-22 8797
-
Xilinx Virtex UltraScale+ HBM FPGA2018-11-22 5426
-
关于FPGA上HBM 425GB/s内存带宽的实测2022-12-19 2540
-
SK海力士推全球最高性能HBM3E内存2023-08-22 1994
-
ESD HBM测试差异较大的结果分析2024-11-18 2441
全部0条评论

快来发表一下你的评论吧 !
