

基于FPGA的神经网络加速硬件和网络设计的协同
描述
引言
很久没有看基于FPGA的神经网络实现的文章了,因为神经网络加速设计做的久了就会发现,其实架构都差不多。大家都主要集中于去提高以下几种性能:FPGA算力,网络精度,网络模型大小。FPGA架构也差不多这几个模块:片上缓存,卷积加速模块,pool模块,load,save,指令控制模块。硬件架构上并不是太难,难的反而是软件编译这块。因为其要去适应不同的网络模型,还要能兼容FPGA硬件的变化,同时要为客户提供一个容易操作的接口。这些在目前情景下还比较困难。首先是FPGA硬件的变化太多,各个模块可配参数的变化(比如卷积模块并行数的变化),另外一个是网络模型多种多样以及开源的网络模型平台也很多(tensorflow,pytorch等)。网络压缩也有很多种算法,这些算法基本上都会导致网络模型精度的降低。一般基于FPGA的网络加速设计都会强调模型被压缩了多少以及FPGA上可以跑得多快,却很少集中于去改善精度。
这篇文献从概念上提出了硬件和网络的协同设计,是很好的一个思路。因为之前神经网络加速硬件设计和网络压缩是分开的,只是在网络压缩的时候尽可能考虑到硬件的特点,让网络模型更加适合硬件架构。这篇论文其实也是在做这样类似的工作,我并不认为它真正的实现了硬件和网络设计的协同(虽然其标榜自己如此)。但是它确实给我们提供了一个新的研究思路:如何从一开始就设计一个能够适用于硬件的网络。好的,废话不多说,来看论文。
1. 来自作者的批判
发表论文,总是要先去总结以往论文的优缺点,然后指出其中不足,凸显自己的优势。这篇文章也花费了很大篇幅来批判了过去研究的不足。总结起来有以下几点:
1) 过去的研究都是用一些老的网络,比如VGG,resnet,alexnet等,这些网络已经落伍了,市场上已经不怎么用了;
2) 过去用的数据集也小,比如CIFAR10这类,包含的图片种类和数量都太少,不太适合商业应用;
3) 压缩老的网络的技术手段不再适用于最新的网络,比如像squeezeNet网络,它就比alexnet网络小50倍,但是能达到和alexnet一样的精度;
4) 以往的类似resnet的网络,有skip连接的,并不适合在FPGA上部署,因为增加了数据迁移;
5) 以往网络的卷积核较大,如3x3,5x5等,也不适合硬件加速;
6) 以前网络压缩集中于老的那些网络,这些网络本身就有很大的冗余,所以压缩起来很容易,而最新的网络比如ShuffleNet等压缩起来就没有那么容易了,但是这样的报道很少;
总之,意思就是之前的文章都捡软柿子捏,而且比较落后了。那么我们来看看在这样狂妄口气之下的成果如何。
2. shuffleNetV2到DiracDeltNet
shuffleNetV2是新发展出来的一个神经网络,它的网络模型中参数更小(比VGG16小60倍),但是精度只比VGG16低2%。shuffleNet不再像resnet将skip连接的数据求和,而是skip连接的数据进行concat,这样的操作降低了加法操作。Skip连接可以扩展网络的深度和提高深层网络精度。但是加法skip不利于FPGA实现,一个是加法消耗资源和时间,另外一个是skip数据增加了迁移时间。Concat连接也和加法skip有相同的功能,增加网络深度和精度。
作者对shuffleNetV2网络结构进行了更有利于FPGA部署的微调。有以下三个方面:
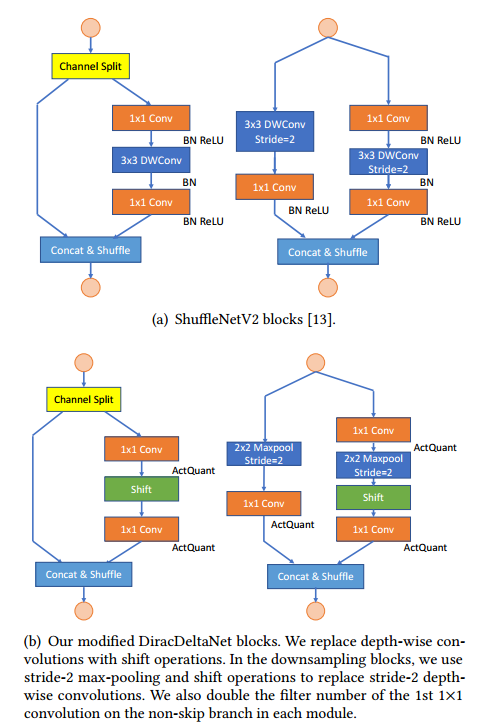
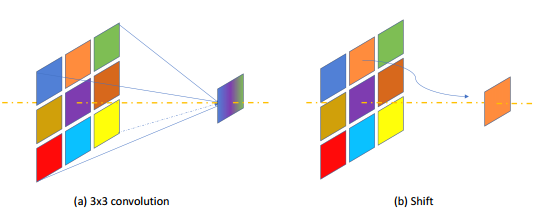
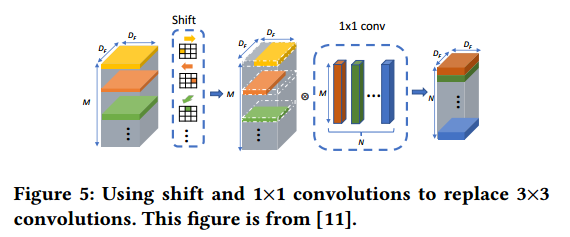
1) 将所有3x3卷积(包括3x3depth-wise卷积)都替换为shift和1x1卷积。这样替换是能够降低feature map数据的迁移,比如3x3的卷积每个图像数据要使用3次,而1x1只需要搬移一次,降低了逻辑复杂性,也提高了运算速度。Shift操作是将某个范围的pixel移动到中间作为结果,这样的操作减少了乘法运算次数。这种替换会导致精度降低,但是可以减少FPGA运算次数。
2) 将3x3的maxpooling操作降低为2x2的。
3) 调整了channel的顺序来适应FPGA。
3. 量化
为了进一步降低网络参数量,作者采用了DoReFa-Net网络的量化方式,对全精度权重进行了量化。同时作者还对activation进行了量化。量化结果如下:
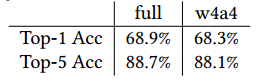
精度损失很小。
文献中使用了很多对网络修改的微调技术,细节很多,可以看出对这样一个已经很少参数的网络来说,要进一步压缩确实要花费很大功夫。这可能不太具有普遍性。这些微调应该会花费很多时间和精力。
4. 硬件架构
硬件主要实现的操作很少,只有一下几种:
1)1x1卷积
2)2x2的ma-pooling
3)shift
4)shuffle和concat
所以硬件架构上也变得很简洁,文章中说两个人用HLS只做了一个月。
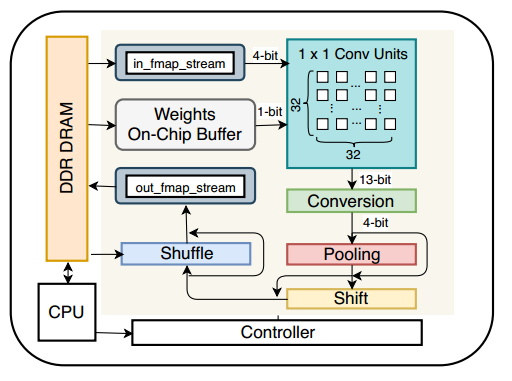
使用资源很少。

看以下和其他人的结果对比:
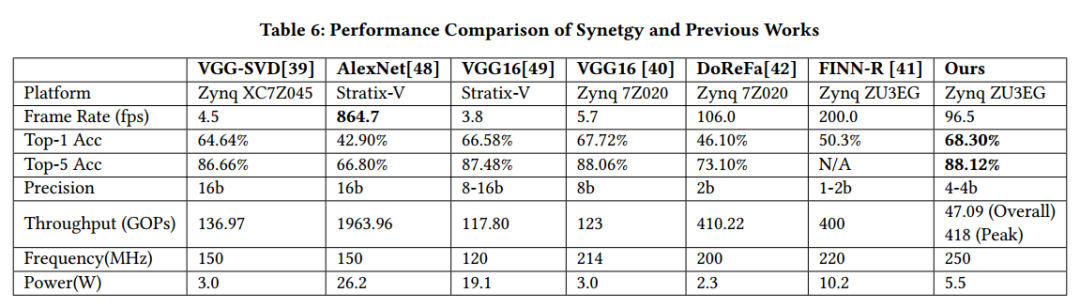
结论
这篇论文在shuffleNet网络的基础上,基于FPGA的特点进行了网络修改。包括网络结构和量化,最终的精度都高于以往的几个网络。结果还是不错的,只是这样手动微调网络并不是很具有普遍性,而且涉及到很多微调技术,也不一定适合每个网络。但是作者确实提供了一个思路:如何去设计一个能够用于FPGA的网络,而且还可以保证很好的精度。
文献
1. Yifan Yang, Q.H., Bichen Wu, Tianjun Zhang, Liang Ma, Giulio Gambardella, Michaela Blott, Luciano Lavagno, Kees Vissers, John Wawrzynek, Kurt Keutzer, Synetgy Algorithm-hardware Co-design for ConvNet Accelerators on Embedded FPGAs. arXiv preprint, 2019.
-
【PYNQ-Z2申请】基于PYNQ的卷积神经网络加速2018-12-19 3984
-
基于赛灵思FPGA的卷积神经网络实现设计2019-06-19 4263
-
如何设计BP神经网络图像压缩算法?2019-08-08 4002
-
如何移植一个CNN神经网络到FPGA中?2020-11-26 5940
-
基于FPGA的神经网络的性能评估及局限性2021-04-30 1767
-
如何构建神经网络?2021-07-12 2026
-
EdgeBoard中神经网络算子在FPGA中的实现方法是什么?2021-09-28 1130
-
请问一下fpga加速神经网络为什么要用arm核呢2022-07-25 2916
-
用FPGA去实现大型神经网络的设计2022-10-24 3163
-
基于FPGA的RBF神经网络硬件实现2021-04-28 1277
-
基于FPGA的神经网络硬件实现方法2021-06-01 1548
-
FPGA加速神经网络的矩阵乘法2023-09-15 597
-
基于FPGA的RBF神经网络的硬件实现2023-10-23 762
-
如何在FPGA上实现神经网络2024-07-10 4929
-
什么是神经网络加速器?它有哪些特点?2024-07-11 2223
全部0条评论

快来发表一下你的评论吧 !
