

为什么要编码?视频编解码原理及详细步骤
电子说
描述
谈到视频的编解码,我们会自然地想到H.264、HEVC/H.265这些权威的视频编解码标准;谈到标准,有人觉得这个是有专门机构去研究的,我们关心应用就好;即使有兴趣读了标准和相关技术,面对更多的是各种数学公式和术语,如协方差、傅立叶变换、高频、滤波等等,需要花更多时间去理解。通常更为实际的做法是,我们只要调研如何应用这些标准,如何做好软硬件编码方案的选型,如何优化技术参数以及如何调用API,也就基本能够应对日常的视频业务了。因此,谈到视频的编解码,往往带有一丝神秘色彩。
本文的目标是以非专业的视角来看待视频编解码原理,试图将所谓高大上的专业术语或名词转换为普通IT业者略懂的话语,从而使更多人了解视频编解码到底是怎么回事。
为什么要编码?
原因很简单,不经过编码的源视频数据量太大了。例如输出一路1920×1080分辨率、24位色、每秒30帧的高清视频,就这么一秒钟的视频,它的码率达就到了1.5Gbps.因此需要编码,尽最大可能将其压缩至最低。下图展示了编解码标准的演进历程,经过H.264编码后,视频码率被压缩到10Mbps,是源视频数据量的1/150。
那么,什么时候我们不再关心编码了?理想的状态就是我们不再对存储空间和网络带宽的限制有顾虑的时候,就不需要考虑编码了,照单全收即可。
思考:N年以后,在 G网络普及之后,视频的编解码技术和CDN的作用会不会越来越被淡化?
什么是编码?
狭义但不全面的解释:编码最主要的工作就是压缩。但压缩是分步骤的,不是简单地把图像中重复的0 聚在一起这么简单。依据方法论,可压缩的内容有以下几种:
单幅图像压缩
一幅图像,分成若干小块,每块8×8像素大小,如果这个小块的每个像素的颜色都是白色,是不是就可以用一个点的值来代替这所有64个点的值? 这在编码中的标准术语叫空间冗余,相应的方法叫帧内压缩。
多幅图像间压缩
视频中一个连续的动作,比如画面里的女主角在红墙背景下闭上了眼睛,这一动作的背后,是由一系列的多幅图片组成,而每幅图片的内容基本上都是一样的,唯一变化的部分就是女主角的眼睛所在图像区域,眼睛缓慢由开到闭,这块区域的像素值发生了变化。对于绝大多数的背景区域,它是没有变化的,那么除了含有闭眼动作的这块区域,是否可以只用一幅图像来代替这么多个连续的图像呢?这在编码中的术语叫时间冗余,强调的是在一定时间段内如何对连续多幅图像的冗余部分进行压缩,术语叫帧间压缩。
编码的压缩
图像的空间冗余和时间冗余都被压缩了,压缩成一串字符串,对这段字符串的展现有没有进一步压缩的可能性呢?是所谓的编码冗余。
所有的视频编码技术和标准都是努力对上述三种冗余数据进行压缩,绞尽脑汁采用不同的算法和策略,产生了不同的结果,也就产生了不同的视频编码标准。
编码的核心技术步骤主要分为预测、变换、量化、熵编码,这几步之后还有个可选步骤是滤波。是不是有点懵,现在解释一下。
预测
一个视频根据时间采样被拆成N个图像,为了压缩和计算方便,每个图像被分成多个小块,比如每个小块由8×8个像素构成。如果不做压缩,就需要把每个图像的每个像素值都存储起来,一共存储N幅图像连接起来,从而构成一个完整的原始视频。像素值的类型分为图像的亮度值和色彩值。为了简化理解 ,本文通篇以亮度值举例进行讲解。
压缩的第一步是预测。对于一幅图像的每个块,根据某几个相邻的像素值,在指定的方向上对下一个像素点的值用一个公式做预测,从而得到该点的预测的像素值,来构造完整的图像。
再比如:有连续两幅运动图像 ,对一幅图像不做改变,保存本来的像素值,然后以此图像的值为基础,对另一幅图像使用公式计算来做运动预测,即把第一幅图像的某个像素的值,经过公式计算后,预测出第二个图像指定位置的像素值,以此类推,得到一幅完整的预测出来的图像。
问题来了,这世上哪有那么牛的算法能计算预测得这么完美?是的,没有。那预测还有什么用?答案是为了获取他们的差。差值有什么用?因为差值的绝对值都很小。还是不明白?我们看下图的三个像素值矩阵:
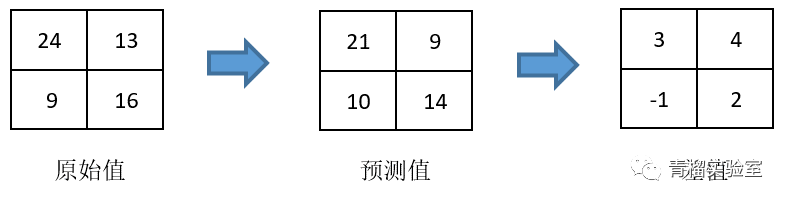
是不是感觉到了差值矩阵的数据存储的绝对值比较小?数值小,理论术语上是为了使包含的信息能量变低;是为了到编码阶段,使编码压缩的数据量更小,从而压缩效率更高。这就是预测的作用。
我们有了原图,又有了特定的预测公式算法,就不需要再去存储第二幅至相关第N幅的像素原值,只需要存储它们的差值就行了。如果要解码,把数据拿来,利用公式还原后再加上差值,就可以把那些被预测的图像的真面目恢复了。
在一幅图内做预测,就叫帧内预测;对一系列组图如一段扣篮动作的视频做运动轨迹预测,属于帧间预测。
拿来做基准参考的帧,叫I帧,是关键帧,它的信息量最大,只能做帧内压缩,通常压缩率很低;而那些后续通过参考I帧的信息做预测获取差值的图像,存储的根本不是原像素值,而是些原始图像的残差,叫预测帧。预测帧有时候会混合使用帧内预测和帧间预测,取决于该区块对那种算法更适应。
根据前一幅图像来预测得到本帧图像叫P帧;结合前面的图像和后面的图像进行双向预测计算得到的本帧图像叫B帧。基于一幅关键I帧图像加上一系列相应的预测图像如B帧、P帧构成的一组图像叫GOP。

现在该明白别人常说的I帧、B帧、P帧是什么意思了吧?I帧是图像信息的关键;B帧或P帧才是主要被压缩的地方。
思考:为了降低视频的网络传输延迟,在CDN上的HLS视频数据分片是不是越细越好?
答案:不是。切片时要为每一个分片都提供至少一个I帧和一系列P帧、B帧。分得太细,I帧数量反而会变多。I帧太多,就意味着压缩率变低,网络传输量不降反升。
变换
事情还远没结束。虽然通过预测公式降低了众多像素存储的编码信息量,但这还不是压缩。于是引入了各种变换,如离散余弦变换DCT、小波变换等等。学术上,其目的是将图像进行从空域到频域的变化,通过这些所谓的变换滤掉高频信息,因为人眼对高频信息不敏感,滤掉一些也无所谓。经典的DCT公式长这样:
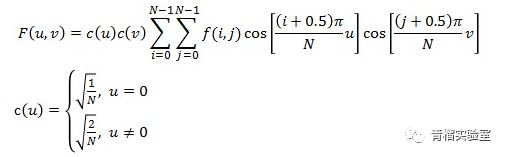
是不是又懵了?好吧,翻译一下 ,看下面这个图。变换公式就如同是水果分拣机器,根据某种特点如按体积大小对水果进行归类,把个头大的放一堆,个头小的放一堆。经过变换,实现了物以类聚,后续如果再有需求就可以很容易地进行封箱打包的操作了。
对图像的变换改变了原来像素信息的空间顺序,取而代之的是依据频率和幅度的存储方式。但此时的变换,只是改变了队形,没有任何实际的压缩动作。
拿一个8×8的图像块举例,原始图像块的像素值如下:

经DCT变换的结果如下图。
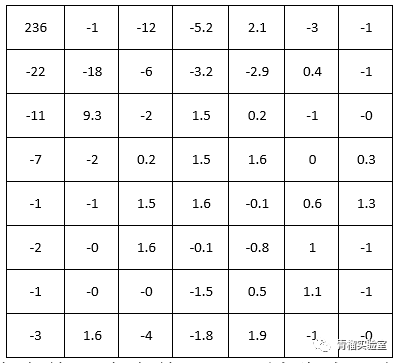
能看出点什么特征吗?如果还不能,提醒一下:矩阵左上角的数值较大,而右下角的数值较小,且趋近于零值。这就是传说中的频率划分。经过DCT变化,低频的、幅值高的、重要的信息都被归置在左上部;而人类不敏感的、高频的、却又低振幅的数据都放在了右下侧。
这又有什么好处呢?在接下来的量化步骤,就可以对右下侧的数据开刀了。因此可以简单理解,不管是什么A变换还是B变换,不要被它的公式和名称吓倒,它只是为了改变队形,为后续的编码和压缩做准备。
量化
到现在为止,仍然没有进行实质性的压缩。万事俱备,只欠量化。它是压缩前的最后一道工序。量化就好比对刚才站好队的队员的身高进行分级打分,通过一个基准步长来计算出每个值的相对数值。又懵了吧? 如下图:量化前左上角的值为236,步长为8,则量化后它值为236/8 = 30;量化前第二行首元素的值为-22,则量化后为-22/ 8 = -3。
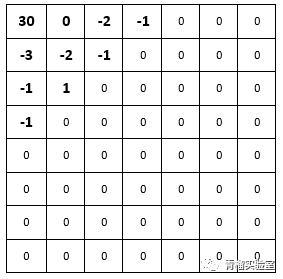
这样一来,经过量化分级,数据开始变得简洁明了,但精度也有损失了,损失的大小由量化的步长决定。图像的失真就是由量化引起的。
回顾,经过上面的DCT变换后以后,数据队形已准备好;再经过量化,把很多高频的右下角的数值变为0。对数值进行Z字形扫描,就变成一串数字了 。
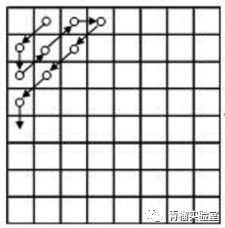
针对上面的变换后的值的量化结果为:
30, 0, -3, -1, -2, -2, -1, -1, 1, -1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
为什么要进行Z字形扫描,因为可以更方便地把0 都聚在一起;为什么0 都会排在右下角?因为经过了DCT变换改变了队形。 为什么把0聚在一起?为了编码压缩啊!
熵编码
压缩的第一道工序叫行程编码。什么是行程编码?忘掉这个名词,就是把连续重复的数据的用重复的次数值来表示。看例子,一个原始串:
aaaaaaabbbbccccdddeeddaa
对这个原始串进行行程编码后,把重复的字母用一个重复的数字来代替,变成了这样:
7a4b4c3d2e2d2a
这就是行程编码的思想。行程编码思想虽然简单但用处很大,在PNG,GZIP等各种压缩算法里都有它的影子。
这还不算完,只是压缩的一小步,第二步就是要对行程编码后的数据进行变长编码,如Huffman编码,这才是压缩的重头戏。Huffman编码主要思路是将出现频率最高的字符串用最短的码来替换,从整体上减少了原始数据的长度。网上的讨论极多,这里不再详述,感兴趣的也可见我的文章《图解DEFLATE编解码》。
编解码总结
再梳理一下视频编码的核心步骤:
• 先做帧内预测和帧间预测,根据关键帧来获取每幅图像的差值,从而减少存储的编码信息量;
• 对其进行变换,完成队形调整;
• 对数据进行有损量化,将不重要的数据归零;
• 对量化数据进行特定方向的扫描,将二维数据转为一维数据;
• 最后进行压缩,即先进行行程编码,再使用压缩编码。
解码的步骤只是反其道而行之。
绝大部分的视频编解码标准都无一例外地包含这些目标。当然有些标准还考虑了环路滤波,但它不是必选项,这里不做解释。
编解码的标准
各大标准之间有什么区别?有了上面的基础理解后,就比较好解释了。不同的标准,有的只用了变换,有的用了预测加变换的混合编码;或者帧内预测算法不一样,预测方向不一样,有的支持4个方向,有的支持8个方向;或者变换的算法不一样,如有的是DCT变换,有的是小波变换;或者熵编码算法也不一样,有的是Huffman编码,有的是算术编码;等等等等……
具体一点如H.263及之前的编码标准,会对帧内编码块直接进行变换,到了H.264,它提供了基于9种方向的帧内预测;再如到了HEVC / H.265, 采用了基于四叉树的分块方式;对于帧间预测提供了8种预测单元的划分类型,除了支持离散余弦变换DCT,还首次使用了离散正弦变换DST,更有效地实现了对残差矩阵的变换。
越是最近新出的编码标准,算法越先进,也越复杂。
最后
以上就是视频编解码的基本原理,希望读了以后能大体明白视频编解码原理的基本思路。但如果真想对视频编解码的标准和算法细节做深入了解,那就真得要下苦功夫了。文中每个主题,都可以写出几本书来。请有理想有毅力的同学继续前行,祝一切顺利!
编辑:hfy
- 相关推荐
- 热点推荐
- 视频编解码
-
视频编解码标准课件2024-12-06 519
-
视频编码包括什么?视频编解码器是如何工作的?2023-04-21 4077
-
#硬声创作季 #视频技术 视频技术-视频编解码技术基础1-3水管工 2022-10-12
-
一个非常朋克的技术-那什么是帧率与编码方式呢?#视频剪辑 #视频编解码面包车 2022-07-29
-
基于HarmonyOS编解码能力,实现Camera实时预览流的播放2021-09-17 1593
-
视频编解码器是什么,编解码器技术原理作用2019-06-24 15472
-
IPTV视频编解码标准的对比与选择2019-01-03 1962
-
字典学习的压缩感知视频编解码模型2018-03-12 973
-
Firefly-RK3399多路视频编解码2017-09-02 7890
全部0条评论

快来发表一下你的评论吧 !
