

基于Xilinx SRAM中FPGA实现高速ICAP控制器
电子说
描述
介绍一篇在FPGA工程领域特别有价值的文章,虽然该文仅仅是EI检索,连SCI检索都不是,但其对深入理解FPGA动态可重构的概念却具有重要的参考价值。文章阐述了Xilinx FPGA可编程的本质,逆向分析破解了FPGA编程的bit流文件,并将其与FPGA内部电路相对应,对于深度理解动态可编程及FPGA电路结构具有重要的指导价值,LUT动态可编程使得FPGA内部的资源使用起来更灵活,你可以把LUT当成BRAM使用,也可以随时改变若干个LUT组成电路完成的硬件功能,而这些过程的实现细节网上的资料非常少,团队研究生花费近三个月重现了该文的内容,整理完毕后会把详细实现过程分享给大家,敬请期待。本文只是用工具把英文文章翻译了一下分享给大家(如今的工具翻译水平的确不错)。希望看到的大牛们能够给予指导。
论文标题:AC_ICAP灵活的高速ICAP控制器
论文摘要:内部配置访问端口(ICAP)是基于Xilinx SRAM的现场可编程门阵列(FPGA)中实现的任何动态部分可重配置系统的核心组件。我们开发了一种新的高速ICAP控制器,名为AC ICAP,完全采用硬件实现。除了加速部分比特流和帧的管理的类似解决方案之外,AC ICAP还支持LUT的运行时重新配置,而无需预先计算的部分比特流。通过对比特流执行逆向工程,可以实现最后的特性。此外,我们采用了这种基于硬件的解决方案,以提供可从MicroBlaze处理器访问的IP内核。为此,扩展了控制器并实现了三个版本,以便在连接到处理器的外围本地总线(PLB),快速单工链路(FSL)和AXI接口时评估其性能。因此,控制器可以利用处理器提供的灵活性,但利用硬件加速。它在Virtex-5和Kintex7 FPGA中实现。重新配置时间的结果表明,Virtex-5器件中单个LUT的运行时重新配置小于5us,这意味着与Xilinx XPS HWICAP控制器相比,速度提升超过380倍。

1、引言
现场可编程门阵列(FPGA)器件作为电子系统设计和评估的基本组件而存在。它们不断被报告为最终实现平台,而不仅仅是原型元素[1]。 FPGA已根据VLSI缩放技术的步伐而发展,使得可以在最先进的制造工艺中开发这些器件。例如,7系列基于Xilinx SRAM的FPGA基于28 nm,高k金属栅极工艺技术[2],Xilinx Virtex UltraScale +采用16 nm FinFET +,AlteraStratix 10器件采用Intel-14 nm Tri-栅极(FinFET)工艺技术[3]。这是有利于越来越多的这种设备作为ASIC的可编程替代品的原因之一。
此外,FPGA的设计和制造方面的技术改进产生了更强大,更灵活的元件,嵌入了更大的RAM存储器模块(BRAM),DSP模块,处理器和专用的硬连线组件.FPGA提供的固有可重配置特性是其中最重要的特性之一实际硬件实现和系统重新设计的优势。
我们专注于Xilinx器件,因为除了支持动态部分重配置(DPR)之外,还可以对比特流进行改进。这意味着可以执行对比特流结构的逆向工程,这对于我们在LUT上执行DPR的方法是必不可少的,这将在第3节中解释。
基于Xilinx SRAM的FPGA通过内部配置访问端口(ICAP)支持DMA。如图1所示,这个硬连线元件允许在运行时访问配置存储器。因此,可以修改系统的特定部分,而其余部分继续运行而不受特定运行时修改的影响。动态部分重新配置可以在不同的粒度级别使用。考虑到设备的体系结构,它可以用于修改基本逻辑组件,例如查找表(LUT)或更大的块,例如IP核。因此,DPR广泛应用于自适应系统的设计和关键系统的评估,这些系统需要在最终生产之前进行详尽的测试。
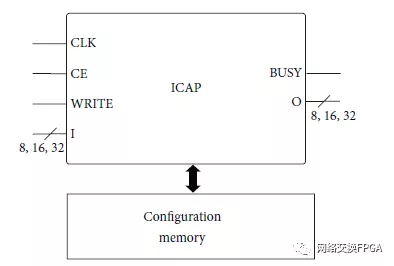
图1:ICAP硬连线原语
Xilinx工具(如PlanAhead或命令行"bitgen-r")将两个实现之间的差异用于生成部分比特流,以允许修改已定义为在运行时更改的特定部分。然后将部分比特流复制到FPGA的外部或内部存储器中,并在系统需要新的硬件任务时将其发送到ICAP。除了特别适用于粗粒模块的这种类型的运行时重新配置之外,还存在使用在片上处理器中执行的某些软件功能来动态地修改诸如LUT的基本元件的替代方案。
考虑到这一点,硬连线ICAP原语及其相关控制器成为动态运行时可重构系统设计中的基础和不可分割的模块.ICAP控制器负责执行访问和修改配置存储器的所有命令。因此,希望这种控制器满足至少两个基本要求:高重新配置吞吐量和灵活性。
Xilinx工具提供通用控制器来驱动ICAP,但它们将大部分处理作为处理器中的软件程序执行。它意味着灵活性,但避免达到最大支持的重配置吞吐量。据报道,这些控制器的多种替代方案可以提高重新配置速度。它们中的大多数已经被定向为管理在设计时生成的部分比特流,并且还操纵作为最小可寻址配置存储器的帧。
深入了解设备的粒度,还应该可以使用已实现设计的LUT上的任何动态修改来增加系统的灵活性。例如,它可以在加密模块中用于修改模块的逻辑行为并增加对某种类型的外部攻击的抵抗力。因此,还需要一种允许在运行时修改LUT的有效机制,因为LUT是在FPGA中实现任何逻辑功能的基本组件。 ICAP控制器应提供一种以最大支持速度在LUT中执行DPR的方法,不仅限于预生成的部分比特流,而且呈现简单的接口,使得架构设备的复杂性对用户透明。
在本文中,我们提出了一种新颖的运行时重配置控制器,它完全在硬件中实现,并支持Xilinx FPGA中LUT的部分重配置。这项工作的主要贡献是:
(1)设计和实现支持DPR的fLUTAC ICAP控制器,并在Virtex5和Kintex7器件中验证
(2)将LUT坐标和LUT配置值透明地片上转换到帧位置
(3)对于位于BRAM或闪存中的部分比特流,LUT-DPR的加速和类似的重新配置速度(与现有解决方案相比)
(4)FSM独立操作和IP版本适用于不同的嵌入式微处理器接口(PLB,FSL和AXI)。
本文的其余部分安排如下。在第2节中,我们回顾了ICAP控制器设计中最相关的工作。在第3节中,我们提出了关于细粒度部分重构的主要考虑因素。在第4节中,我们详细介绍了新的AC ICAP控制器。在第5节中,介绍了可从片上处理器访问的控制器扩展。在第6节中,我们描述了将控制器移植到更新的设备系列时要遵循的注意事项。在第7节中,我们给出了控制器所需的重新配置时间和区域的结果。接下来是第8节,其中控制器用于在加密模块中对LUT进行修改,以实现针对外部攻击的对策。最后,第9节总结了论文并提出了未来的工作。
2.相关工作
在本节中,我们概述了FPGA动态部分重配置中使用的一些最相关的ICAP控制器实现。部分重新配置已广泛应用于各种应用[5-7],这些应用利用了在运行时调整硬件模块的可能性。使用这种技术时的一个共同要求是,应该以最小的时间开销执行硬件模块的切换。
实现具有DPR功能的系统的最常用方法是使用Xilinx工具中提供的ICAP控制器。 XPS HWICAP [4],如图2所示,AXI HWICAP和OPB HWICAP分别是设计用于连接PLB [8],AXI和低速OPB总线的IP内核。它们用作嵌入式处理器系统(PicoBlaze或MicroBlaze)的一部分,并且通过处理器API提供的一系列软件功能提供对部分重新配置的支持。这些功能允许处理位于存储器中的部分比特流,访问配置帧(XHwIcap DeviceReadFrame,XHwIcapDeviceWriteFrame)和修改LUT(XHwIcap SetClbBits,XHwIcap GetClbBits)。在[9]中详细介绍了使用函数修改特定LUT的示例,[10]中的作者使用函数tomodify帧来模拟配置存储器上的故障。
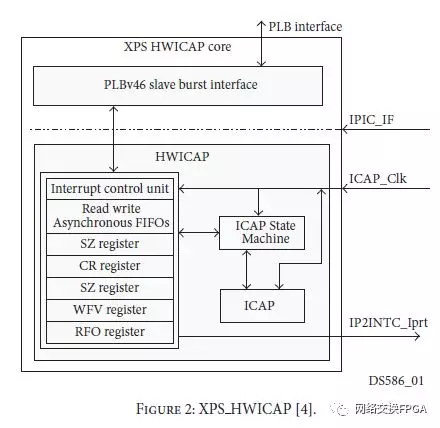
Xilinx功能将大部分操作作为处理器中的软件程序执行。然后,管理ICAP和处理在处理器中执行的部分比特流报头以及总线等待时间的命令影响部分重新配置过程的速度。因此,已经开发了各种替代控制器来克服这些限制。[11]中的作者探索了分析重新配置速度的不同ICAP控制器,并提出了三种变化来加速部分比特流的处理,但它们都需要存在处理器。
[12,13]也是如此。在后一种情况下,使用FSL链路将控制器集成在处理器数据路径中,以最小化总线延迟。相比之下,[14,15]现有的Virtex-5器件控制器能够从BRAM和闪存中加载部分比特流,完全由硬件实现,独立于处理器。以类似的方式,[7,16]报告了用于Virtex-4 FPGA的独立于处理器的ICAP控制器的实现。 [17]中的作者利用DPR来设计容错系统。这些方法显示了在使用BRAM时可以达到最大支持吞吐量的重新配置速度的改进。此外,一些工作,例如[7,18]中提出的工作,通过对ICAP进行超频,实现了高于技术文档中指定速率的吞吐速度。
所有这些工作都面向有效地访问部分比特流并执行硬件切换任务,但不考虑完整控制器应支持的一些其他操作。鲁棒控制器应该能够回读和写入配置帧,并且除了仅控制部分比特流之外,还可以修改LUT。这些最后的特征在关键系统的实现中至关重要,其中ICAP控制器是设计的基本部分[21]。考虑到这一点,各种方法,如[20,22-24]中报道的那些,使用改进的ICAP控制器是基于SRAM的FPGA中容错系统的基本组成部分。在这样的系统中,ICAP用于检测和校正配置存储器中的故障。要做到这一点,控制预先计算的部分比特流是不够的,它们实现了帧的读取和写入,因为在此级别执行故障检测。例如,一旦读取帧,就可以获得其CRC以检查其组成位中是否存在错误。在错误值的情况下,可以校正帧并使用正确的值写回配置存储器。因此,这些报告的工作包括用于写入和读取配置帧的帧处理。
据我们所知,在[25]中介绍了作为ICAP控制器的一部分在LUT级执行运行时重新配置的唯一工作,但它仅适用于LUT具有四个输入的Xilinx Virtex-II器件该器件的架构与新的Xilinx系列有很大不同。这些框架覆盖了设备的整个高度,并未详细说明LUT配置值如何位于框架上。此外,这个家庭目前被认为已经过时。
在这项工作中,我们开发了一个完全用硬件实现的新型ICAP控制器,支持比特流管理,帧的读取和写入以及LUT修改。该方法提供了LUT重新配置速度的改进,并且在不需要预先计算的部分比特流的情况下执行。此外,它可以轻松适应各种Xilinx FPGA系列中的片上处理器。
3. LUT的动态部分重配置
在本节中,我们将介绍XilinxFPGA的一般架构以及部分重配置的相关概念,以Virtex-5 XC5VLX110T器件为参考。但是一般的想法也适用于较新的设备,特别是在考虑LUT时,因为它们保持不变;它是6输入LUT,适用于Virtex-5,Virtex-6和7系列FPGA。
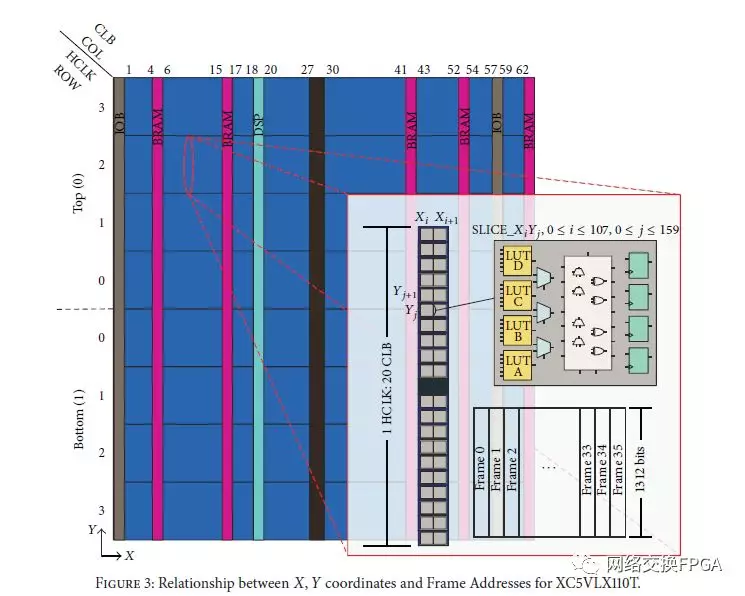
FPGA被组织为连接到开关矩阵的可配置逻辑块(CLB)阵列。图3显示了XC5VLX110T FPGA的配置,可以观察到它被水平分成两半。在顶部(0)和底部(1)两半,我们发现固定数量的行取决于特定器件的大小。Virtex-5 LX110T FPGA分为8个水平时钟行(HCLK):每半个四个。每个HCLK包括确定数量的CLB,BRAM,DSP和I / O. CLB分布在160行×54列中,覆盖整个设备。每个CLB由两个Slice组成,每个Slice包含4个LUT,4个触发器,多路复用器和进位逻辑。因此,该FPGA具有17280个片,69120个LUT和69120个寄存器。
一个CLB列定义为跨越HCLK高度的一组20×1 CLB。这意味着,在HCLK行内的每个CLB列中,有40个Slice和160个LUT。
配置存储器按帧组织。一帧是可以寻址的最小配置存储器大小。因此,应该以帧为参考对配置存储器执行任何操作。一帧由41个32位(1312位)组成.Virtex-5 LX110T需要23712个配置帧来配置整个芯片。因此,配置文件(比特流)由972464个32位字(3.7 MB)组成。它在头部包括272个字的控制信息,其余对应于配置帧.(FPGA器件固定,配置文件的大小也就固定了)。
每次我们要配置整个器件时,3.7MB的比特流包含要实现的电路的描述应该加载到配置存储器中。

要配置CLB列,需要36帧。在36帧内,我们拥有20个CLB中存在的每个元素的信息。我们关注LUT,因为这些是实现FPGA中所有组合逻辑的基本元素。
LUT或逻辑函数发生器是六输入元件,需要64位来定义要执行的功能。LUT的逻辑行为取决于在这64位中配置的值(INIT值)。要处理任何单个LUT,必须定义其位置和INIT值。该位置使用三个参数:(x,y,Bel)。 x和y是Slice的坐标,Bel是用于选择Slice内的单个LUT的索引。 x和y的范围取决于FPGA的大小(在所考虑的器件中为108×160)。 Bel索引的范围从0到3,用坐标(x,y)选择Slice内的4个LUT(LUT-A,LUT-B,LUT-C和LUTD)中的一个。一旦识别出特定的LUT,就可以通过64个配置位修改其INIT值。如第2节所述,由于Xilinx API提供的某些软件程序,可以在运行时修改此LUT参数。函数XHwIcap GetClbBits用于读回LUT的INIT值并将其存储在内存中。 XHwIcap SetClbBits将系统内存中的任何INIT值复制到LUT配置字段中。这两个函数都需要相同类型的参数:LUT(x,y和Bel)的坐标和用于定位INIT值的内存地址。我们发现有关这些函数及其执行的操作的信息非常有限。这些参数的格式目标文件(.o)及其源代码不可用。
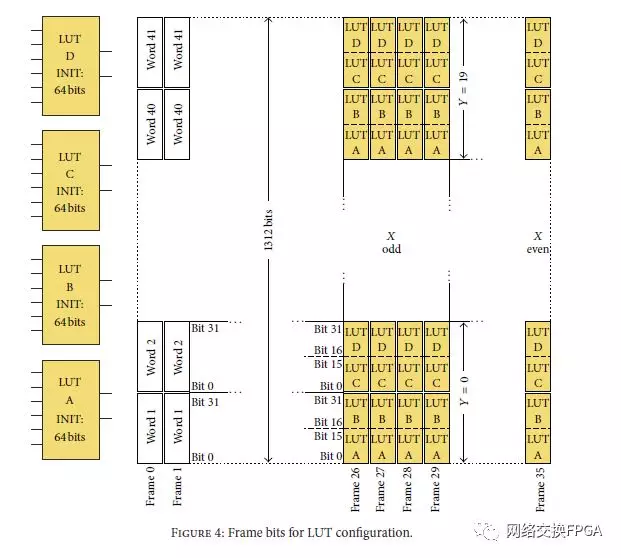
此外,使用这些函数读取和写入LUT的配置值所需的时间大约为2ms,而使用XHwIcap DeviceReadFrame和XHwIcapDeviceWriteFrame函数读取和写入帧的时间大约为30 us。这些数字是使用基于MicroBlaze的100MHz系统实验获得的,为我们提供了改善LUT重新配置时间的机会。因此,我们进行了实验以推断出LUT参数和配置帧之间的关系。通过组合XHwIcap SetClbBits函数以使用XHwIcap DeviceReadFrame写入特定LUT来分析帧上的编程值,我们发现使用四个帧来重新配置单个LUT。
如图4所示,INIT值的64位跨越四个连续帧,每帧包含16个INIT位。每个CLB列中的40个Slice可以看作是20列Slice的2列。一个Slice列包含20个Slice,在x坐标上具有偶数值,而其他20个Slice包含奇数值。帧26至29包围具有奇数x坐标的20个Slice的LUT配置值,而当32坐标为偶数时,帧32至35具有20个Slice的相应信息。以类似的方式,Slice-y坐标确定要使用的每个帧内的特定字。对于任何CLB列,y需要20个连续值。根据此值,帧中的特定字对应于单个LUT。两个连续的帧字具有片的4个LUT的部分信息。 16位INIT LUT-A和16位INIT LUT-B配置值在一个32位字中。类似地,LUT-C和LUT-D INIT值位于下一个字中。
4. AC_ICAP实现
AC ICAP控制器(如图5所示)提供与Xilinx工具中可用的XPS HWICAP和AXI HWICAP类似的功能,但AC ICAP完全在硬件中实现,而不是将大部分任务作为处理器中的软件例程。它包括支持ReadFrames,WriteFrames,Modify LUT,以及从闪存和BRAM内存加载部分比特流。与同样在硬件中实现帧读取和写入的类似方法[20]相比,我们的控制器通过LUT的运行时重新配置得到改进,而无需预先计算的部分比特流。这最后一个特性与自适应的实现相关可能需要根据运行时生成的值对硬件进行微调的系统,而不仅仅是基于预先计算的值。第8节将更详细地讨论这方面的问题。
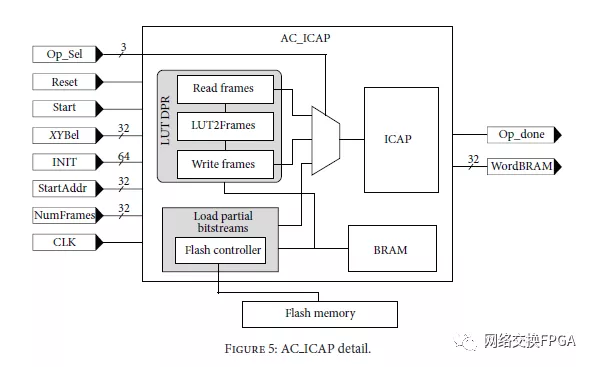
控制器及其内部模块使用有限状态机(FSM)根据表1中指定的输入Op sel的值在不同的配置级别上操作。
AC ICAP最初使用配备了Virtex-5LX110T FPGA的电路板开发,实现流程在Xilinx工具版本14.7中执行。尽管Virtex-5系列提供了详细信息,但应注意控制器也按照第6节中的说明在7系列系列中实现。

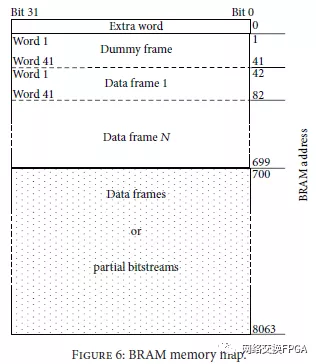
如第3节所述,LUT的DPR需要修改帧的特定部分。因此,用于读写帧的两个模块在LUT运行时重新配置的实现中是必不可少的。我们设计了具有BRAM空间的AC ICAP控制器,能够存储可以重新配置4个CLB列区域的部分比特流。然后,控制器对设备中可用的总BRAM具有低影响(148)。因此,我们将7-36 Kbit BRAM元素(31.5KB)配置为双端口存储器。该存储空间用于存储读取的帧,并且还用作要发送到ICAP的帧的源。保留初始2800字节以执行LUT修改和帧任务。剩余的28.7KB可用于帧或部分比特流存储,如图6所示。当部分比特流适合可用的BRAM时,BRAM任务的负载部分比特流可以达到最大指定吞吐量,因为它们之间的直接连接。片上BRAM和额外字虚拟帧数据帧1数据帧N数据帧或部分比特流位31位0 01 699 700 8063字1 41 42字41字1字41 82 BRAM地址图6:BRAM存储器映射。
ICAP通过32位链接。通过使用100MHz的时钟,每个时钟周期可以使用一个32位字,这相当于ICAP支持的最大吞吐量(3.2 Gbps)。我们遵守技术文件中规定的有关ICAP最大工作频率的限制:100MHz [4]。但是,应该考虑到汉森等人在文献 [18]报告了ICAP的正确操作,当它被超频以实现更好的重配置吞吐速度。
接下来详细说明AC ICAP控制器的组成模块。
4.1 ReadFrames模块
ReadFrames模块使用两个参数来定义要读取的位置(FAddr)和帧数(Nf)。 Nf对于单帧读取取值1或对多帧读取取任何其他值。它受控制器上可用BRAM内存的限制。应该注意的是,对于LUT修改任务,一个BRAM块就足够了,但我们包括六个额外的块来存储帧或小的部分比特流。我们将所有读取帧存储在BRAM上,然后可以访问它们以对它们执行任何操作。或者,能够对读取帧进行顶部处理和存储的外部模块可以获得比由BRAM的大小限制的帧更多的帧。例如,所考虑的板中存在的DDR存储器具有256MB的容量。它可用于保存占用AC ICAP可用BRAM的31.5KB以上的配置帧。
在多帧(Nf> 1)的情况下,FAddr是读取过程开始的第一帧的地址。从那里,例程将读取Nf个连续帧。ReadFrames例程中涉及的步骤如图7所示。当op sel =“001”并且Start信号被置位时,ICAP被配置为读取指定的帧。这是通过写入ICAP的某些寄存器来完成的,详见[28]。重要的是指出CE和WRITE输入的正确断言以定义ICAP上的读取或写入操作。在CE之前,应该修改内容,以避免引起中止序列。它在图7中的两个框ICAPWRITE和ICAP READ中有详细说明。
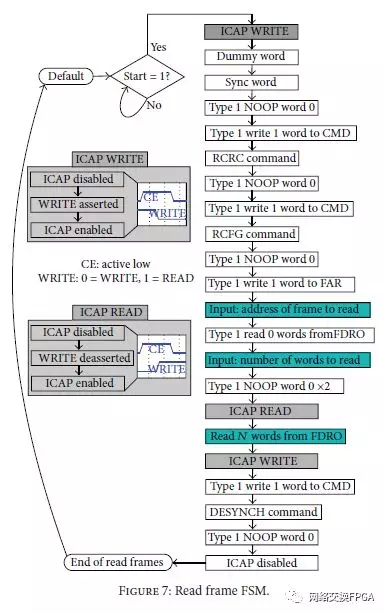
输入FAddr和Nf用于用输入字标识的流程的两个步骤。这两个值适用于相应寄存器的格式。 FAddr应具有帧地址寄存器的格式,即一个32位字,其中包含字段:块类型,顶部,HCLK行,列和列内的帧。 Nf用于计算读取的字的数量(N)并生成要发送给ICAP的类型2字。用户可以通过输入Startaddr和NumFrames分别指定FAddr和Nf。或者它们可以由Lut2Frames模块生成,如第4.3节中所述。
我们必须考虑任何帧的读取都包括在过程开始时生成的一个额外虚拟帧以及一个额外的字。考虑到这一点,Virtex-5器件的读取字数可以计算为
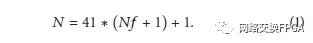
公式(1)适用于任何Virtex-5FPGA,因为在这些器件中,所有配置帧都具有相同的大小。这是41个32位字。伪帧由1到Nf的加法表示。最后一个添加代表了最初的字。
来自FDRO的状态READNWords执行组成帧的N个32位字的实际读取。对于从ICAP的FDRO寄存器读取的每个字,增加BRAM地址以将帧存储在该存储器上。图6显示了帧的位置和其它字。
4.2 WriteFrames模块
该模块的设计遵循与ReadFrame中相同的方法。主要区别在于准备ICAP写入配置存储器所需的配置命令。当表1中定义的Op sel输入为“010”且启动信号有效时,WriteFrames模块被激活。要达到最大吞吐速度,要写入的帧的首选源是BRAM。如果帧位于AC ICAP的BRAM中,则每个时钟周期都有一个32位字。
由于此模块通常与ReadFrames结合使用,因此要写入的帧已经被读取并存储在BRAM上。然后,WriteFrames模块使用相同的存储空间,如图6所示,其中ReadFrames放置了回读帧。
与ReadFrames模块需要考虑一个虚拟帧的方式相同,在每个写帧例程中,虚拟帧应该在进程的最后部分发送到ICAP。因此,数据帧从BRAM地址= 42开始并在地址41 *(Nf + 1)。发送数据帧后,应立即跟随虚拟帧。为此,起始地址更改为1,并在发送41个字(1帧)时结束。地址0处的额外字不用于写入过程。
我们生成Op完成输出以指示写入过程的结束。有必要保证ICAP任务正确完成。发送完所有字后,必须发送DESYNC命令并禁用ICAP。当ICAP接收并处理DESYNC命令时,操作完成。当输出端口O从0xDF变为0x9F时观察到。该过程具有6个时钟周期的延迟,与输入CE上的值无关。
4.3 DPR of LUTs with LUT2Frames 模块
LUT2Frames模块通过将LUT参数转换为帧表示来允许LUT的动态部分重配置。如第3节所述,LUT的特征在于坐标(x,y,Bel)和INIT值。 LUT2Frames模块,如图8所示,执行两个主要任务:(1)将x,y,Bel坐标转换为FAR格式,以及(2)将INIT(64位)LUT函数转换为4个16位的字。
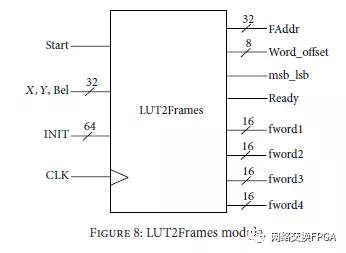
x,y,Bel输入合并为一个32位字,当设置Start输入时,LUT2Frames模块使用INIT值。基于坐标值,生成一个具有帧地址寄存器(FAddr)格式的32位字,以定义读写开始的帧。此外,x,y和Bel值确定字偏移量,它是需要操作的每个帧(2-41个字中的第一个)的具体字。
从32位字开始,只有16位对应于特定的LUT。因此,信号msb lsb指示应修改32位字的哪一部分:0为字的LSB部分(LUT-A或LUT-C) 16个MSB(LUT-B或LUT-D)为1。
与先前的处理并行地,LUT2Frames模块生成四个16位字(fword1⋅⋅⋅fword4),其对应于变换并适应四个帧的INIT值。
帧位置和寻址的所有复杂性对用户是透明的。 LUT2Frames模块实现所有转换并计算适当的地址和内存管理,以便在需要修改整个设备中的任何LUT时允许用户进行简单操作。
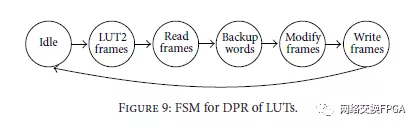
当需要进行LUT修改时,执行由FSM控制的步骤,如图9所示。该过程由启动信号触发;然后,激活LUT2Frames模块。使用此空闲备份字生成的值修改帧写入帧读取帧LUT2帧模块,从FAddr开始的4帧被读取并存储在BRAM(读取帧)中。字偏移和msb lsb表示应修改的特定字。备份这4个字(备份字),使用LUT2Frames生成的四个字进行修改,并复制回BRAM。此时,BRAM包含具有新字的帧,并且WriteFrames模块执行对应于LUT的4帧的写入。
Recover LUT例程使用在备份字阶段获得的四个备份值将LUT恢复到其先前的配置值。考虑图9,它仅执行LUT修改例程的最后两个步骤。
它修改了BRAM上的4个帧,然后通过WriteFrames模块发送这些帧以将LUT恢复到其先前的INIT值。此例程在需要在修改LUT之前恢复LUT的先前功能的应用程序中非常有用。通过遵循这种方法,我们避免再次读取四帧,因为这些已经在BRAM上。
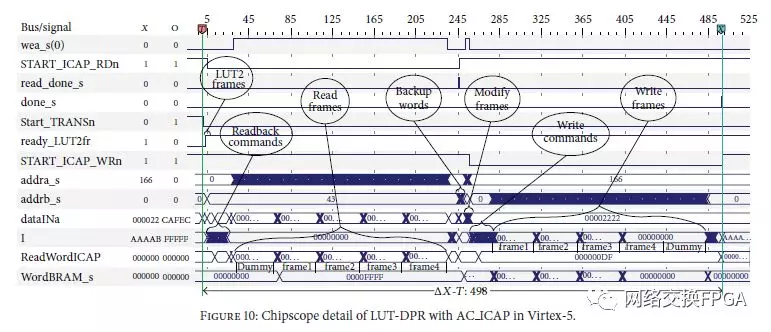
使用ChipScope Pro Debugger [29]验证了控制器的正确操作。图10显示了LUT修改过程的详细信息。我们指定了要修改的LUT的x,y,Bel和INIT值。图10中所示的步骤可以在图10中标识。LUT2Frames模块仅需要两个时钟周期,并且它生成的信息用于寻址四个帧以读取和修改这些帧中的四个特定字。
4.4 Load Partial Bitstreams模块
该模块遵循类似于第2节中描述的方法,关于通过加载部分比特流来加速部分重新配置。负载部分比特流模块执行三个主要任务:(1)从闪存加载部分比特流,(2)将部分比特流从闪存复制到BRAM,以及(3)从BRAM加载部分比特流。为此,该模块包括一个存储器访问控制器,用于从闪存中读取部分比特流。因此,从闪存读取的数据可以直接发送到ICAP I端口,也可以复制到内部BRAM中。当部分比特流在BRAM上时,可以达到ICAP上的最大配置速度。如果部分比特流在外部存储器上,则重新配置时间取决于访问存储器的延迟。在这种情况下,我们使用Intel StrataFlash存储器28F256P30,它需要在100MHz的26个时钟周期才能得到32位字。
可以放置在BRAM上的部分比特流的大小受控制器上可用的BRAM存储器的限制。从AC ICAP中存在的7-36Kbit BRAM,我们保留了2800字节来执行LUT修改和帧任务。因此,可放置的部分比特流的最大大小为28.7KB。它可以增加,因为FPGA包含更多的BRAM(LX110T器件中有148个)但它取决于应用限制。
部分比特流是按照标准Xilinx流程生成的;它使用的是PlanAhead或bitgen工具。这些配置文件包括关于设备类型的标题信息,配置数据的大小,比特流的生成的日期和时间等。我们调整部分比特流以从头部移除不必要的信息,并且仅保留与不包括头部的部分比特流的大小(以字节为单位)对应的最后的头部字段。因此,我们的控制器首先读取包含部分比特流大小的字,并使用该信息计算从内存中读取的字数(闪存为16位字,BRAM为32位字)。使用这种方法,唯一需要的参数是部分比特流所在的初始地址。
控制器自动计算结束地址并执行读取过程。根据输入Op sel选择的操作,数据将发送到ICAP或BRAM。以类似的方式,当Op sel设置为“111”时,该模块配置ICAP控制信号和BRAM地址以允许高吞吐量部分重新配置。
5. AC_ICAP适用于片上处理器
为了使控制器能够连接到基于处理器的设计,它适用于MicroBlaze系统使用的外围本地总线和快速单工链路接口。为此,AC ICAP被认为是具有图5中所示的I / O端口的黑盒子,并且这些端口适用于各自的总线。这种方法提供了更大的灵活性,因为控制器可以容易地从处理器命令。我们创建了一系列适用于每个接口的函数,以执行表1中所示的任务。这些函数(如代码1所示)使用XilinxAPI中的特定例程来访问PLB和FSL接口。
代码1、驱动AC ICAP IP的功能如下:

StartAddr参数指的是应根据op sel值进行调整的唯一输入。在读取和写入帧的情况下,它对应于初始帧的地址(FAddr)。对于其他功能,它是存储数据的存储器地址。 NumFrames是要读取或写入的帧数,x,y bel,INIT是控制单个LUT的参数。这些是命令AC ICAP控制器所需的唯一值,因为它在内部执行所有操作,例如将x,y bel和INIT转换为帧格式,在读取部分比特流的大小后计算结束地址,等等。
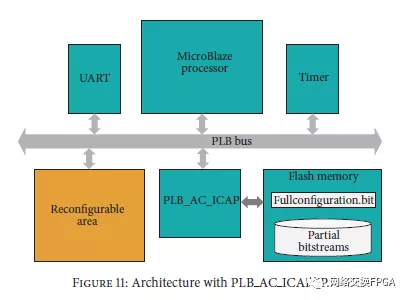
5.1 PLB IP
PLB总线用于将外围设备连接到MicroBlaze处理器。以VHDL设计的原始AC ICAP在PLB包装器中实例化以生成定制PLBAC ICAP IP。控制器的输入和输出连接到PLB总线的信号,然后处理器可以使用寄存器地址访问它们。因此,PLB AC ICAP可以连接到任何基于MicroBlaze的系统,如图11所示。该架构包括闪存,其中修改可重配置区域的全部和部分比特流位于其中。通过将闪存的AC ICAP连接定义为外部端口,也可以在IP设计中执行与闪存的直接连接。一旦包含在EDK的硬件设计中,处理器中运行的软件就能够通过使用代码1中列出的功能来控制PLB AC ICAP外设。因此,部分重配置相关任务使用代码1中指定的任何功能。并监视输出操作,直到它变高为确认任务已完成。
5.2 FSL Coprocessor
Fast Simplex Link是MicroBlaze处理器的一个接口,允许包含具有高执行优先级的专用硬件例程,因此意味着与处理器通信的低延迟。在这种方法中,我们采用了类似于[13]中提出的解决方案,以便由于总线延迟而获得最小的控制器性能下降。因此,基于VHDL的AC ICAP适用于FSL接口,可以作为协处理器轻松连接,从而利用处理器的所有灵活性,但利用ICAP相关任务中的硬件加速。图12显示了使用FSL AC ICAP协处理器的系统。
FSL AC ICAP协处理器的访问方式与PLB AC ICAPIP中考虑的方式类似,即通过代码1中提供的功能集合。主要区别在于这些例程的类型功能需要todrive theFLS。在这种情况下,我们将阻塞例程putfsl和getfsl与Xilinx API结合使用,因为我们认为重新配置任务具有高优先级。
6.在较新的设备系列中使用AC_ICAP
为了验证7系列器件中的控制器,我们使用配备Kintex7 XC7325T FPGA的KC705板[30]。
该FPGA包含50,950个Slice,在每个Slice内部,有4个6输入LUT和8个FF .445个BRAM对应2002 KB,比特流大小为10.9MB。为了使针对Virtex-5设计的AC ICAP适应7系列器件,需要进行某些更改。主要差异总结如下:
(1)7系列系列中每帧的字数为101而不是41(Virtex-5)。这是因为7系列FPGA中的CLB列高50宽1宽,这意味着CLB列中存在100个Slice。同样,HCLK行的数量也不同;对于这个特定的设备,它是7(3顶部和4底部)。
(2)开始读或写的帧的地址由FAR寄存器定义。对于7系列,该寄存器使用32位中的26位,而在Virtex5 FAR中,它使用24位。这是由于FPGA的大小增加。
(3)与Virtex-5相反,对于7系列,在读取帧任务开始时不需要额外的字。因此,可以根据对任何7系列FPGA有效的(2)来计算从这些设备读取/写入的字数(Nwords 7),因为在这些设备中所有配置帧具有相同的大小。伪帧由帧数(Nf)加1表示:
(4)指示在LUT-DPR过程中应该修改帧上的特定字的字偏移现在具有0到100的范围。对于Virtex-5,它在0到40之间变化。以类似的方式,跳过列(包含不同于CLB的资源的列:BRAM,DSP I / O)和主要列编号需要更新.Kintex7中的第一列的主要地址为2,而它为1 Virtex-5的。
(5)在7系列中,原始ICAPE2没有BUSY输出。相反,我们应该在CE断言后考虑3个时钟周期来获得有效数据。
(6)WriteFrames模块还需要进行一些更改。在Virtex-5中,可以通过设置配置寄存器(COR0-bit28)并在每次修改FAR时将值0xDEFC加载到CRC寄存器来绕过CRC计算。在7系列中,此类寄存器不存在;默认情况下,新的控制寄存器(COR1-bits15-16)设置为允许在计算CRC后对系统进行连续操作,因此删除了这些步骤。
(7)该电路板中可用的闪存与Virtex-5中的闪存类型相同,但由于尺寸不同,闪存控制器经过修改后还包含两条额外的地址线。
配置CLB列所需的帧数保持不变(36),包含LUT信息的特定帧也是如此。我们使用22个BRAM块占用与Virtex-5类似的百分比(5%)。
一旦在AC ICAP中执行了所提出的更改,它就在Kintex7 FPGA中实现,并使用它支持的所有操作进行测试。在图13中,我们再次提供了一个LUT的DPR细节,因为它涉及控制器中可用的各种任务。
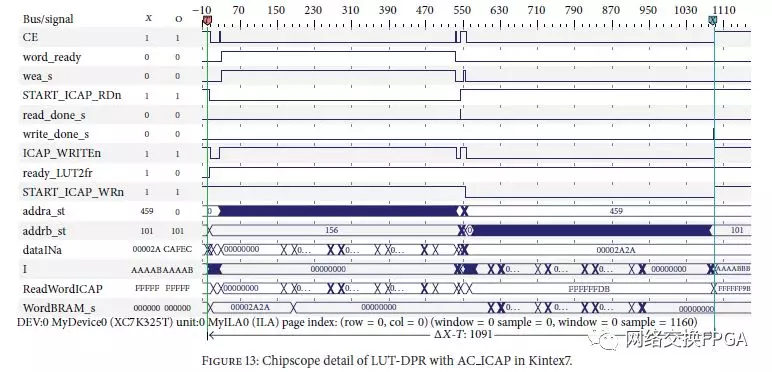
这个新的AC ICAP适用于AXI接口,因为它用于所有newXilinx系列。该IP被标识为AXI AC ICAP,并支持代码1中提供的适用于AXI API的相同功能。
基于前面的描述,我们有不同的控制器变体来评估:AC ICAP,独立硬件版本; PLB AC ICAP和AXI AC ICAP,分别适用于PLB和AXI总线;和FSL AC ICAP,用作协处理器。我们使用PlanAhead 14.7和Vivado 2015.3来定义不同大小的可重新配置分区(从1到10个CLB列)并生成不同的部分比特流。
对于基于Xilinx的控制器,我们实现了如图11所示的架构,但我们不是使用PLB AC ICAP,而是添加了XPS HWICAP或AXI HWICAP,其参数可以实现重配置吞吐量的最佳性能(写入FIFO深度= 1024,读FIFO深度= 256,并启用FIFO类型)。对于这两种情况,还包括Xilinx闪存控制器,以访问位于该存储器中的部分比特流。在这样做时,我们可以获得准确的比较,因为我们使用相同的工具版本和综合选项。
7. 实验结果
本节总结了有关AC ICAP控制器的各种版本的重新配置速度和资源利用率的主要结果。我们认为比较用于Virtex5的Xilinx XPS HWICAP和用于Kintex7的AXI HWICAP的主要参考,因为这些是报告的替代方案中的一个,支持大多数DPR任务的那些。我们考虑到,对于配置多达4个CLB列的部分比特流,可以将它们复制到BRAM中,因为Virtex-5限制为28.7KB,Kintex7限制为99 KB。为了记录AC ICAP(独立版本)的时间性能,使用了ChipScope Pro。对于适用于处理器接口的版本,系统中包含的定时器用于记录特定任务所需的时钟周期数。这些数字在表2中报告。这里,我们想提一些关于Kintex7 FPGA获得的值的问题.AXI HWICAP包含的LUT功能不支持7系列。使用最新版本的工具进行实验(Vivado 2015.3和驱动程序hwicap v10 0),仅支持Virtex6和以前的设备,我们无法修改它们,因为源代码不可用。功能对于使用AXI HWICAP的读写帧,需要修改一些头文件,因为它们会出现一些错误的值。文件xhwicap ih:使用7系列中的Virtex6值,但这些值不应该相同。例如,声明两个族的帧中字的数量是81.但是对于7系列族,正确的值是101. FAR创建时会发生类似的情况。驱动程序使用一些对Virtex-6有效但不对Kintex7有效的参数创建FAR,并对这些参数进行了修改以获得正确的操作。
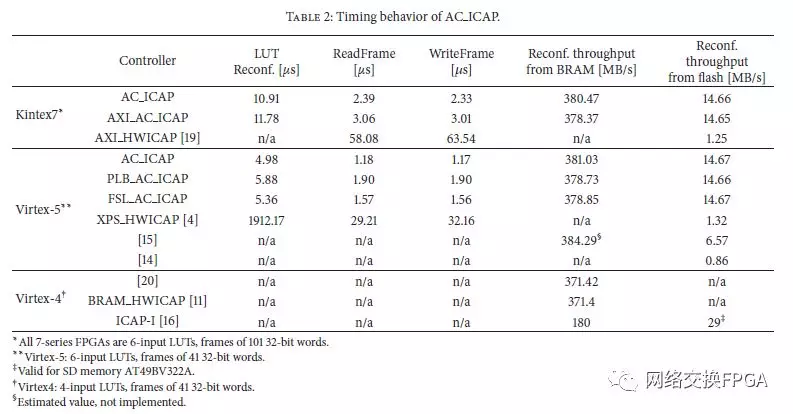
从表2可以看出,据我们所知,使用AC ICAP的LUT的重新配置时间是报告最快的替代方案。与Virtex-5中的XPS HWICAP相比,它意味着PLB AC ICAP的速度提升超过320倍,这是最慢的版本,独立的AC ICAP改善了LUT的重配置时间超过380次。以类似的方式,考虑到Virtex-5和Kintex7,读写帧任务的加速分别经历了超过18次和21次的改进。
对于Virtex-5和Kintex7,来自BRAM的负载部分比特流(对于AC ICAP)的重新配置吞吐量分别为380.47和381.03 MB / s。它接近400MB / s的最大支持吞吐量和[15,20]上的报告值。对于[15]报告的工作,应该指出的是,估计的价值并不是在实际执行中衡量的;因为该控制器不包括BRAM。我们的控制器与400 MB / s值的偏差是由于ICAP开始读取BRAM和处理DESYNC命令(0x0D)所需的额外时钟周期。对于每个与ICAP相关的任务,我们认为在确认DESYNC命令时它就完成了。它是通过监视ICAP的O端口来完成的,该端口在Vinterex-5中从0xDF变为0x9F,在Kintex7中从0xFFFFFFDB变为0xFFFFFF9B,以确认完成任务是否成功。这意味着在最后一个数据发送到的后6个额外的时钟周期ICAP。
对于PLB,AXI和FSL版本,由于接口的延迟,时间会有一些降级,但在所有情况下,它们对来自闪存的负载部分比特流提供了超过11倍的改进。
将部分比特流从闪存复制到BRAM的时间与从闪存加载部分比特流所需的范围相同。这些存储在BRAM上,而不是向ICAP发送数据。因此,当应用程序可以在执行开始之前(例如,在引导时)将部分比特流复制到BRAM时,它尤其有用。
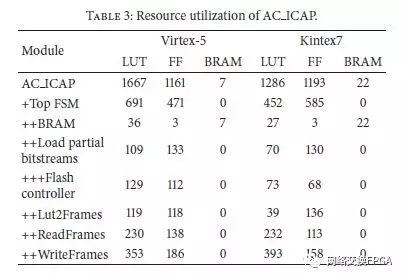
关于资源利用率,表3列出了AC ICAP控制器的每个模块的详细信息。应该注意的是,AC ICAP包括闪存控制器,而XPS HWICAP和AXI HWICAP则不是这种情况。表4总结了控制器的各种选项所需的资源。 AC ICAP的PLB,AXI和FSL版本的额外资源是由于使控制器适应这些接口所需的包装逻辑。可以看出,资源需求最大的方法使用了5%的Slice,这可以被认为是合理的大小,因为所有操作都是在硬件中完成的。
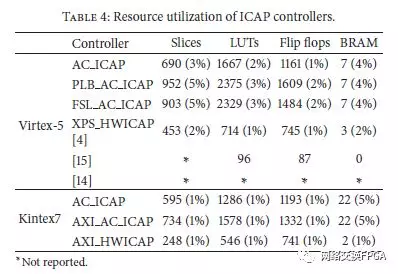
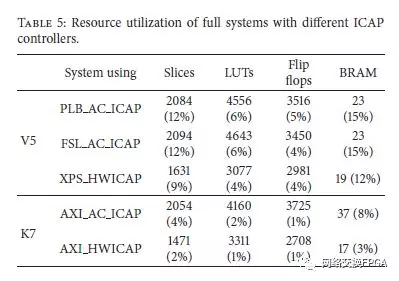
最后,在表5中,我们比较了完整的基于MicroBlaze的架构所需的资源,包括不同版本的ICAP控制器。我们可以看到,使用适用于PLB和FSL的AC ICAP的系统平均需要比XPS HWICAP替代方案多3%的Virtex-5 FPGA资源。这是为了加速所有重新配置任务而支付的区域开销,例如当使用FSL AC ICAP时,LUT的重新配置时间在356x中得到改善。当我们看到Kintex7的数据时,面积百分比随着设备的增大而降低。
因此,随着要管理的配置数据量变得越来越大,任务的加速变得越来越重要,但ICAP原语支持的速度和总线宽度自Virtex-4生成(32位@ 100MHz)以来保持不变。从提供的数据中,我们可以总结出最佳的性能区域权衡由AC ICAP给出,它使用3%的FPGA资源但在LUT DPR中提供380x的加速。
使用该方法的LUT的动态部分重新配置提供了以下优点:对于要执行的每个修改,它不需要预先计算的部分比特流。它允许使用任何布尔值修改运行时LUT,并且不受内存中部分比特流可用性的限制。这种精细的部分运行时重新配置在诸如故障注入平台和密码实现的应用中具有越来越大的相关性,其中硬件可以在LUT级别被修改以避免某些类型的攻击。这些细粒度修改的案例应用将在下一节中介绍。
8. 用于LUT评估AES模块的AC_ICAP
在本节中,我们使用AC ICAP来评估[31]中提供的AES模块。我们的想法是找到一种方法来识别LUT的关键配置值。有了这些信息,就可以设计出针对外部攻击的对策。例如,可以采用这种方法来修改某些LUT的逻辑行为,以在不停止系统的情况下产生错误值。在这样做时,AES可以持续工作,给出错误的正确操作感,可以将其用作对抗诸如差分功率分析之类的攻击的对策。
如果使用部分比特流方法来修改LUT,则每个LUT tomodify都需要部分比特流。这些应该在设计时生成并复制到存储器中。因此,LUT的所有可能修改都应该在设计时定义,一旦系统运行,很难包含任何变化,例如新的LUT修改,因为它意味着生成新的部分比特流的耗时过程。 AC ICAP支持的LUT的DPR的优点是不需要部分比特流,并且可以动态地执行任何逻辑修改。为了评估这种方法,我们使用伪随机数发生器(PRNG)来产生64位配置存储器,以便对要修改的LUT进行修改。我们不关注AES或PRNG的细节。我们的目标是提供一种方法来轻松识别LUT及其关键值,以用于评估和设计关键模块。
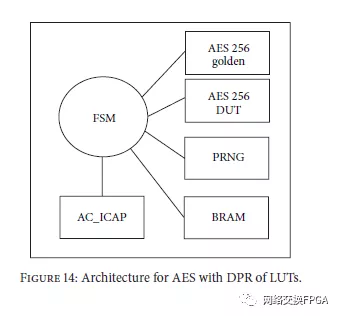
该系统的架构如图14所示,并在Virtex-5 FPGA中实现。我们包括两个AES模块的副本,用于在线比较结果,BRAM存储LUT的信息。 AES的单个副本需要8360 FF和13952 LUT。 DUT副本在区域中受到约束,并定义为要使用的分区,以保持在初始实现中定义的路由。定义了88个CLB列(14080 LUT)的区域来放置AES。由于我们可以在其他设计中重用已实现的分区,因此使用LUT的DPR获得的值对于不同的实现仍然有效。由FSM控制的系统使用PRNG获得随机配置值以配置LUT,并且AC ICAP用于通过使用Slice的x,y坐标来修改DUT区域上的LUT。一旦修改了LUT,就会对黄金和DUT组件应用一些测试台输入,并分析输出以确定LUT修改是否产生错误值。在应用所有输入模式之后,对这种修改的效果进行分类。如果产生错误值,则存储LUT地址和配置值。 LUT恢复到先前的值并测试新的LUT。如果没有产生错误的值,可以绕过它或使用新的配置值进行测试。因此,这种方法允许灵活的替代方案来彻底地或以更轻松的方式评估系统。然后,使用存储在BRAM中的信息来确定在系统受到攻击时可以采用哪些LUT及其相关配置值来有意修改逻辑功能。
9.结论和未来工作
我们介绍了AC ICAP,这是一种在Virtex-5和Kintex7 FPGA中验证的新ICAP控制器。它能够加载部分比特流,读取和写入帧,以及修改FPGA中的任何LUT,在最后一种情况下无需预生成的部分比特流。该控制器适用于使用PLB,FSL和AXI链路的嵌入式处理器系统。与Virtex-5 FPGA的XPS HWICAP功能相比,独立于处理器的版本的重配置速度分析显示LUT的运行时重新配置提高了380多倍。由于我们的控制器完全采用硬件实现,因此显然需要更多资源,但无论如何它占据了XC5VLX110T器件上可用元件的5%以上。因此,AC ICAP提供了一个完整的高速解决方案,可以执行多种动态部分重配置任务。可接受的FPGA足迹。它被用于设计AES模块,可以修改特定的LUT作为可能的攻击对策。
作为未来的工作,我们计划使用DDR控制器扩展AC ICAP,以加速重新配置任务,当这些任务基于预先计算的部分比特流由于其大小而无法复制到BRAM中时。因此,DDR存储器是克服BRAM可用限制的替代方案。
参考文献
[1] Keysight Technologies, M9451A-DPD PXIeMeasurementAccelerator, 2015.
[2] Xilinx, 7 Series FPGAs Overview DS180 (v1.16.1), Xilinx, 2014.
[3] Altera, A New FPGA Architecture and Leading-Edge FinFETProcess Technology Promise to Meet Next Generation System RequirementsWP-01220-1.1, Altera, SanJose, Calif, USA, 2015.
[4] Xilinx, LogiCORE IP XPS HWICAP (v5.01a) DS586, Xilinx, 2011.
[5] L. A. Cardona, J. Agrawal, Y. Guo, J. Oliver, and C. Ferrer, “Performance-areaimprovement by partial reconfiguration for an aerospace remote sensingapplication,” in Proceedings of the International Conference onReconfigurable Computing and FPGAs (ReConFig ’11), pp. 497–500, Cancun, Mexico, November-December 2011.
[6] C. Claus, R. Ahmed, F. Altenried, and W. Stechele, “Towards rapiddynamic partial reconfiguration in video-based driver assistance systems,” in Reconfigurable Computing: Architectures, Tools and Applications, P. Sirisuk,F.Morgan,T.Elhazawi, and H.Amano, Eds., vol. 5992 of Lecture Notes inComputer Science, pp. 55–67, Springer, Berlin, Germany, 2010.
[7] S. Bhandari, S. Subbaraman, S. Pujari et al., “High speed dynamicpartial reconfiguration for real timemultimedia signal processing,” in Proceedings of the 15th Euromicro Conference on Digital System Design(DSD ’12), pp. 319–326, Izmir, Turkey, September 2012.
[8] IBM, 128-Bit Processor Local Bus Architecture Specifications, IBMCorporation, Armonk, NY, USA, 2007.
[9] K. Glette and P. Kaufmann, “Lookup table partial reconfiguration foran evolvable hardware classifier system,” in Proceedings ofthe IEEE Congress on Evolutionary Computation (CEC ’14), pp. 1706–1713, Beijing, China, July 2014.
[10] L. Sterpone and M. Violante, “A new partial reconfigurationbased fault-injectionsystem to evaluate SEU effects in SRAM based FPGAs,” IEEE Transactionson Nuclear Science, vol. 54, no. 4, pp. 965–970, 2007.
[11] M. Liu, W. Kuehn, Z. Lu, and A. Jantsch, “Run-time partial reconfigurationspeed investigation and architectural design space exploration,” in Proceedings of the International Conference on Field Programmable Logicand Applications (FPL ’09),
pp. 498–502, August 2009.
[12] C. Claus, B. Zhang, W. Stechele, L. Braun, M. H¨ubner, and J. Becker,“A multi-platform controller allowing for maximum dynamic partialreconfiguration throughput,” in Proceedings of theInternational Conference on Field Programmable Logic and Applications (FPL ’08), pp. 535–538, Heidelberg, Germany, September2008.
[13] M. H¨ubner, D. G¨ohringer, J. Noguera, and J. Becker, “Fast dynamicand partial reconfiguration data path with low hardware overhead on XilinxFPGAs,” in Proceedings of the IEEE International Symposium on Parallel andDistributed Processing, Workshops and Phd Forum(IPDPSW’10), pp. 1–8, IEEE,Atlanta, Ga, USA, April 2010.
[14] S. Lamonnier, M. Thoris, and M. Ambielle, “Accelerate partial reconfigurationwith a 100% hardware solution,” Xcell Journal, no. 79, pp.44–49, 2012.
[15] J. Tarrillo, F. A. Escobar, F. L. Kastensmidt, and C. Valderrama, “Dynamicpartial reconfiguration manager,” in Proceedings of the IEEE 5thLatin American Symposium on Circuits and Systems (LASCAS ’14), pp. 1–4, IEEE, Santiago, Chile, February2014. International Journal of Reconfigurable Computing 15
[16] V. Lai and O. Diessel, “ICAP-I: a reusable interface for the internalreconfiguration of Xilinx FPGAs,” in Proceedings of theInternational Conference on Field-Programmable Technology (FPT ’09), pp. 357–360, Sydney, Australia, December 2009.
[17] M. Straka, J. Kastil, and Z. Kotasek, “Generic partial dynamic reconfigurationcontroller for fault tolerant designs based on FPGA,” in Proceedings of the 28th Norchip Conference (NORCHIP ’10), pp. 1–4, IEEE, Tampere, Finland, November
2010.
[18] S. G. Hansen, D. Koch, and J. Torresen, “High speed partial run-timereconfiguration using enhanced ICAP hard macro,” in Proceedings ofthe 25th IEEE International Parallel and Distributed Processing Symposium,Workshops and Phd Forum (IPDPSW ’11), pp. 174–180, Shanghai,China, May 2011.
[19] Xilinx, AXI HWICAP v3.0, Xilinx, San Jose, Calif, USA, 2015.
[20] A. Ebrahim, K. Benkrid, X. Iturbe, and C. Hong, “A novelhighperformance
fault-tolerant ICAP controller,” in Proceedings of theNASA/ESA Conference on Adaptive Hardware and Systems (AHS ’12), pp. 259–263, IEEE, Erlangen, Germany, June2012.
[21] A. Ebrahim, T. Arslan, and X. Iturbe, “On enhancing the reliabilityof internal configuration controllers in FPGAs,” in Proceedings ofthe NASA/ESAConference onAdaptiveHardware and Systems (AHS ’14), pp. 83–88, IEEE, Leicester, UK, July 2014.
[22] J. Heiner, N. Collins, and M. Wirthlin, “Fault tolerant ICAP controllerfor high-reliable internal scrubbing,” in Proceedings ofthe IEEE Aerospace Conference, pp. 1–10, IEEE, BigSky,Mont, USA, March 2008.
[23] A. Ebrahim, K. Benkrid, X. Iturbe, and C. Hong, “Multipleclone configurationof relocatable partial bitstreams in Xilinx Virtex FPGAs,” in Proceedings of the NASA/ESA Conference on Adaptive Hardware and Systems(AHS ’13), pp. 178–183, Torino, Italy, June 2013.
[24] U. Legat, A. Biasizzo, and F. Novak, “SEU recovery mechanism for SRAM-BasedFPGAs,” IEEE Transactions on Nuclear Science, vol. 59, no. 5, pp. 2562–2571, 2012.
[25] C. Schuck, B. Haetzer, and J. Becker, “An interface for a decentralized2D reconfiguration on Xilinx Virtex-FPGAs for organic computing,” International Journal of Reconfigurable Computing, vol.2009,Article ID 273791, 11 pages, 2009.
[26] Xilinx, Partial Reconfiguration User Guide UG702(V14.7), Xilinx, 2013.
[27] Xilinx, Command Line Tools User Guide UG628 (v 14.7), Xilinx, SanJose, Calif, USA, 2013.
[28] Xilinx, Virtex-5 FPGA Configuration Guide UG191 (V3.11), Xilinx, 2012.
[29] Xilinx,ChipScope Pro Software and Cores, Xilinx,SanJose, Calif, USA, 2012.
[30] Xilinx, Xilinx Kintex-7 FPGA KC705 Evaluation Kit, Xilinx, San Jose,Calif, USA, 2015.
[31] Opencores,“AES project,” 2015, http://opencores.org/project.
-
如何利用Verilog HDL在FPGA上实现SRAM的读写测试2025-10-22 4918
-
如何使用FPGA实现高速图像存储系统中的SDRAM控制器2021-01-26 1511
-
如何使用Xilinx的FPGA对高速PCB信号实现优化设计2021-01-13 1388
-
如何用中档FPGA实现高速DDR3存储器控制器?2019-08-09 3439
-
基于Xilinx FPGA SOPC的TFT-LCD 控制器设计与实现2017-11-22 3212
-
(Xilinx)FPGA中LVDS差分高速传输的实现2017-03-01 1573
-
FPGA实现CAN总线控制器源码2016-06-07 1182
-
基于FPGA的高速A_D转换控制器设计2016-05-10 1166
-
资源分享季 (10)——Xilinx+FPGA+SDRAM控制器论文2012-07-28 8006
-
基于FPGA的PCI接口控制器的设计与实现2009-12-14 2347
-
ZBT SRAM控制器参考设计,xilinx提供Verilo2009-06-14 828
全部0条评论

快来发表一下你的评论吧 !
