

RTX 30显卡细节公布 TFLOPS是什么参数
电子说
描述
RTX 30显卡的在线发布会上有一个细节特别引人瞩目,那就是公布了一个名为TFLOPS的数据时,如果大家收看的视频有弹幕,一定马上就会弹幕爆炸了。这个参数到底是啥?为什么让大家那么关注呢?咱们今天就来说说吧。
TFLOPS是Tera和Floating-point operations per second词组的组合,后者的意思是每秒浮点运算次数,Tera则是万亿的意思,合起来就是每秒浮点运算多少万亿次。因为现在的图像是分成像素点来处理的,每个点的色彩都要进行浮点运算,然后组合成一幅图片,所以这个参数就说明了显卡或者GPU每秒能处理多少个像素点。
它的基础就来自现在的GPU设计,目前的GPU都是由很多小处理核心或者叫流处理器组成,这个核心比处理器核心简单得多,每个时钟周期只负责处理一个浮点数据,所以总的浮点运算次数就是核心数量×时钟周期了。又因为现在的核心可以一次性处理一个双精度浮点数据,它相当于两个最基础的单精度浮点数据,所以再×2就得到了GPU的浮点运算次数。
回过头来看看这个参数对游戏有啥意义。在分辨率确定后,每一幅画面的像素点数量也就确定了,那么每秒处理的像素点越多,实际上每秒能处理的画面数量当然就越多。这说明了啥?当然就是游戏的帧速(每秒画面数)越高啦。没错,对使用同一代特别是同一核心的显卡,算出它的浮点运算能力,基本就了解游戏速度了。
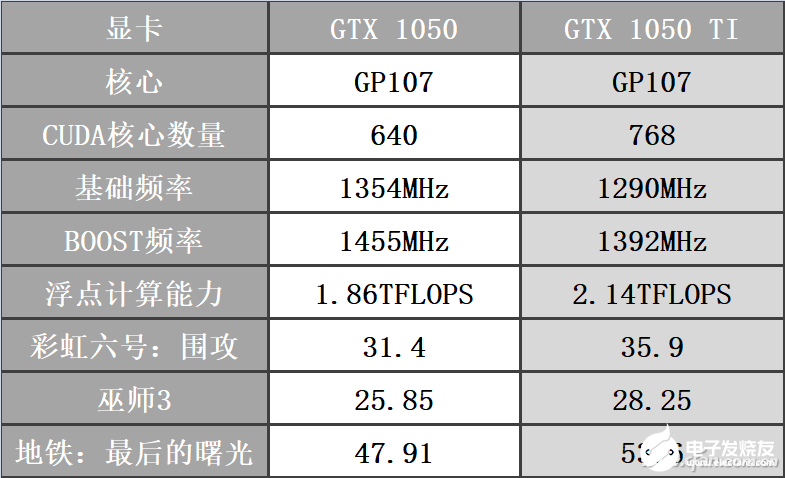
不过对于不同代甚至不同架构的GPU,这种对比就不合适了,比如RTX 3080拥有两倍于RTX 2080 Ti的浮点运算次数,帧速能达到RTX 2080 Ti的两倍吗?从之前的测试大家就知道,当然不是这样。

这就牵扯出了另一个问题,也就是核心的效率,因为谁也不能保证所有的核心或者流处理器能一直满载、有效运行,它的实际发挥还要考虑到前端的分配、后端的合成、显存数据等单元的配合,所以设计不同的架构下,按照最理想情况算出的浮点运算次数能发挥多少也是不同的。
RTX 30还有所不同,因为它实际上是让每个核心中的整数运算单元也参加浮点运算,造成了“理论”运算能力翻倍、但因为干的是非专业工作,整数单元的浮点运算效率肯定赶不上专业的浮点运算单元,再加上前端的数据分配能力、显存带宽啥的没有跟着翻倍,所以效率大幅下降,最终我们可以看到,翻倍的浮点运算能力带来的只是不到40%的实际帧速提升。

既然同一个厂家在架构上的改动都会造成浮点运算能力的实际发挥,AMD和NV这种相差更远的架构就别提了,比如RX 6800系列用了比较特殊的架构设计,就以远低于RTX 3080/3070的浮点运算能力,得到了能抗衡甚至压制它们的性能。
编辑:hfy
-
RTX 5090显卡即将量产 配置细节曝光2024-10-23 1592
-
英伟达发布461.40显卡驱动更新:支持RTX30系移显卡 游戏《灵媒》进行优化2021-02-22 2697
-
RTX 30系列显卡和主板将集体涨价2021-01-14 3237
-
NVIDIA发布RTX 30系列游戏本2021-01-13 3225
-
浅析RX 6000、RTX 30显卡缺货原因2020-12-22 2864
-
微星全新RTX 30超龙系列显卡具体规格一览2020-12-16 7068
-
RTX 30显卡缺货和整个产业链有关2020-12-09 2275
-
微星发布RTX 30 SUPRIM旗舰显卡,散热VIP待遇2020-11-21 2712
-
NVIDIA RTX 30系列显卡缺货的关键原因2020-10-31 6283
-
英伟达RTX 30系列显卡,售价不到RTX 2080 Ti的一半2020-09-19 4630
-
NVIDIA正式发布GeForce RTX 30系列显卡!2020-09-11 6565
-
NVIDIA发布RTX 30系列显卡,支持PCle 4.0功能2020-09-02 3344
-
微软新主机GPU性能公布 略低于目前最强游戏显卡GeForce RTX 2080 Ti2020-02-26 3991
全部0条评论

快来发表一下你的评论吧 !
