

探索Vivado HLS设计流,Vivado HLS高层次综合设计
描述
作者:Mculover666
1.实验目的
通过例程探索Vivado HLS设计流
- 用图形用户界面和TCL脚本两种方式创建Vivado HLS项目
- 用各种HLS指令综合接口
- 优化Vivado HLS设计来满足各种约束
- 用不用的指令来探索多个HLS解决方案
2.实验内容
实验中文件中包含一个矩阵乘法器的实现,实现两个矩阵inA和inB相乘得出结果,并且提供了一个包含了计算结果的testbench文件来与所得结果进行对比验证。
3.实验步骤
3.1.在Vivado HLS GUI界面中创建项目
3.1.1.启动Vivado HLS 2018.1
3.1.2.创建一个新的工程
添加提前创建好的源文件进来,因为我们探索的是设计流而不是编程:
添加提前创建好的测试文件进来:
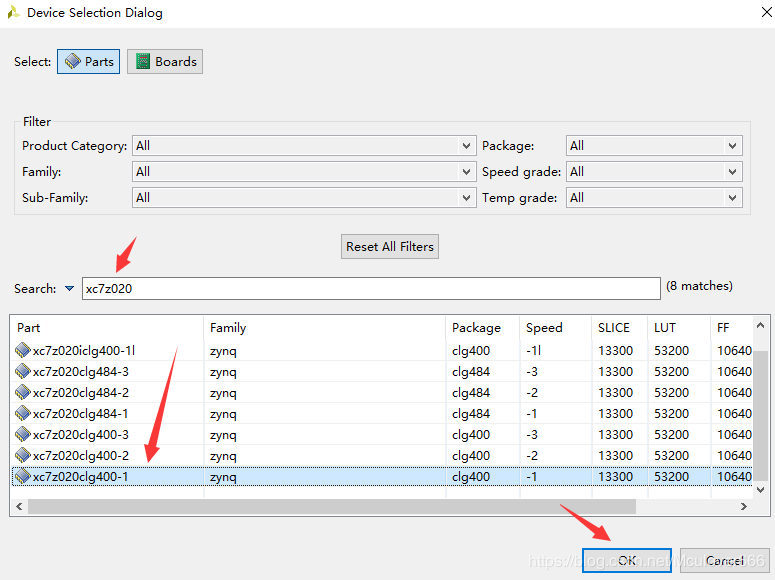
对于具体的FPGA进行解决方案配置,如图所示:
工程创建完成,综合界面如图所示:
3.2.在Vivado HLS 命令行中快速创建项目
在3.1节中采用GUI界面完成了创建工程的工作,这个工程命名和添加文件创建工程的工作可以由一个TCL脚本完成,可以大幅提高我们的效率~
3.2.1.打开Vivado HLS 命令行界面
3.2.2.编写创建工程TCL脚本
新建一个文件run_hls_pynq.tcl,然后编写以下工程配置:
# 创建工程
open_project -reset matrix_mult_prj
# 添加源文件和测试文件
add_files matrix_mult.cpp
add_files matrix_mult.h
add_files -tb matrix_mult_test.cpp
# 设置工程顶层
set_top matrix_mult
# 创建解决方案
open_solution -reset solution1
# 选择具体的FPGA芯片配置
set_part {xc7z010clg400-1}
create_clock -period 5
# 模拟C代码
csim_design
exit
3.2.3.在Vivado HLS命令行运行TCL脚本
在刚刚打开的Vivado HLS命令行界面中输入cd ,然后输入目录所在盘符,进入目录后使用命令vivado_hls -f run_hls_pynq.tcl即可运行脚本,完整过程如图所示:
这样一个工程就创建好了;
3.2.4.在Vivado HLS命令行打开创建的工程
使用命令vivado_hls -p matrix_mult_prj即可在GUI界面打开工程,如图:
3.3.Vidavo HLS中的设计优化
3.3.1.文件作用c
- matrix_mult.cpp 包含了迭代计算矩阵乘法的代码
- matrix_mult.h 包含了宏定义和函数声明
- matrix_mult_test.cpp 测试文件,包含了使用HLS硬件解决方案计算和软件计算的结果,并计算验证
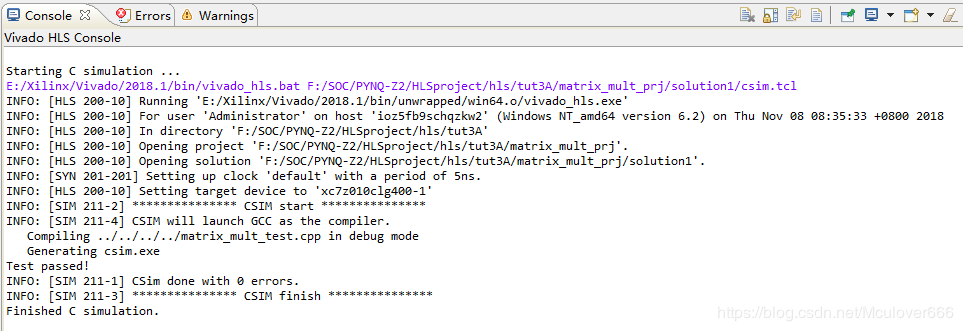
3.3.2.运行C仿真
点击Run C Simulation按钮,然后不用选择,直接下一步,可以看到控制台输出:
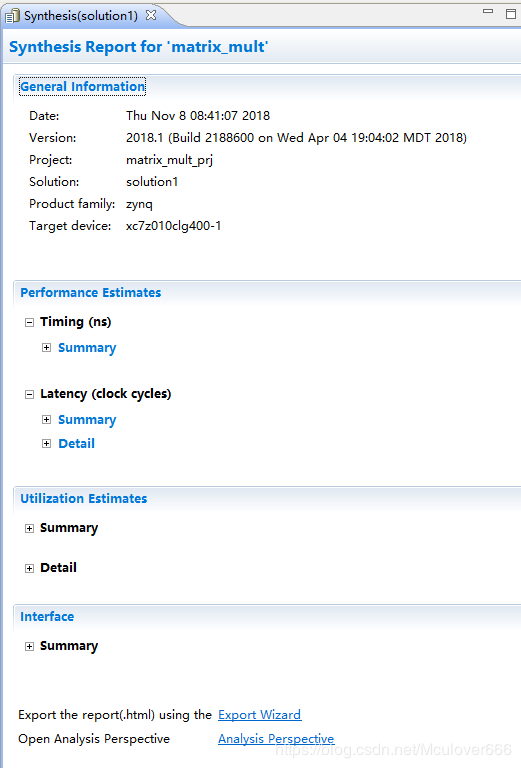
3.3.2.使用HLS综合C++代码
点击C Synthesis按钮,Vivado HLS会开始综合C++代码,综合完成后会自动打开综合报告,其中详细的描述了设计的时序以及FPGA资源占用估算等:
3.3.3.C/RTL共同协作
点击Run C/RTL Cosimulation按钮,选择生成verilog语言文件,设计完成后会自动弹出结果,如图所示:
3.3.4.新建一个解决方案进行对比
点击New Solution按钮新建一个解决方案:
然后打开matrix_mult.cpp文件,选择右边的directive视图,右击Product,选择Inser Directive,然后选择PIPELINE,确定之后运行C综合来综合出RTL设计,完成后同样会弹出设计信息:
然后可以将报告与之前solution1的报告进行对比,
3.3.5.分析
进入Analysis视图:
3.3.6.新建一个流水线解决方案
3.3.7.解决方案对比
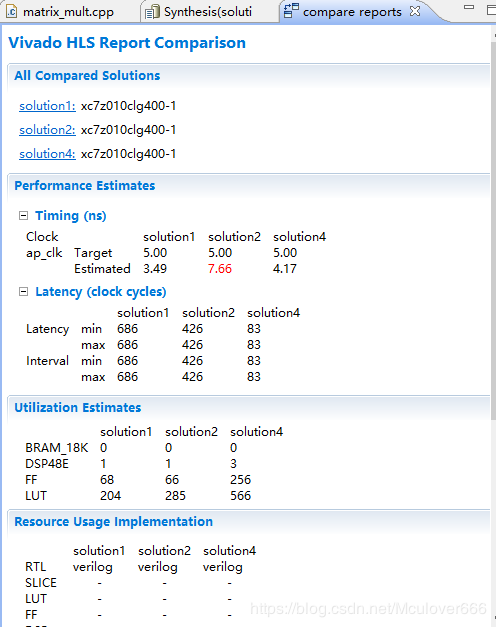
3.4.接口综合
3.4.1.TCL脚本新建工程
在F:/SOC/PYNQ-Z2/HLSproject/hls/tut3C文件夹,使用命令:
vivado_hls -f run_hls_pynq.tcl
3.4.2.打开工程
vivado_hls -p matrix_mult_prj
3.4.3.C Synthesis
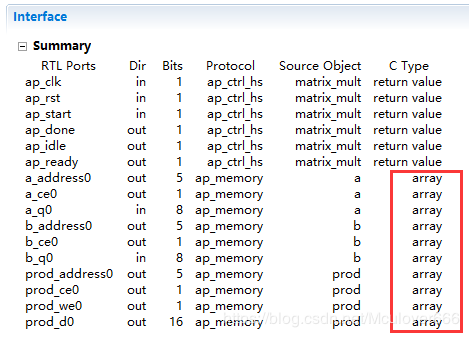
编辑:hfy
- 相关推荐
- 热点推荐
- Vivado
-
通过vivado HLS设计一个FIR低通滤波器2026-01-20 748
-
使用Vivado高层次综合(HLS)进行FPGA设计的简介2023-11-16 617
-
使用Vitis HLS创建属于自己的IP相关资料分享2022-09-09 5614
-
FPGA高层次综合HLS之Vitis HLS知识库简析2022-09-07 3939
-
Vivado HLS设计流的相关资料分享2021-11-11 1172
-
PYNQ上手笔记 | ⑤采用Vivado HLS进行高层次综合设计2021-11-06 880
-
vivado高层次综合HLS定义及挑战2021-07-06 4910
-
高层次综合工作的基本流程2021-01-06 1526
-
来自vivado hls的RTL可以由Design Compiler进行综合吗?2020-04-13 2807
-
关于赛灵思高层次综合工具加速FPGA设计的介绍和分享2019-10-06 2058
-
基于Vivado高层次综合工具评估IQ数据的无线电设备接口压缩算法设计2018-07-24 2975
-
Vivado Hls 设计分析(二)2017-11-16 4362
-
使用Vivado高层次综合 (HLS)进行FPGA设计的简介2016-01-06 1492
-
Vivado 高层次综合2012-04-25 3263
全部0条评论

快来发表一下你的评论吧 !
