

数据分析中最常用、最好用的20个Python库分享
描述
【导读】Python在解决数据科学任务和挑战方面处于领先地位。而一些方便易用的库则帮助了开发人员高效开发。在这里我们整理了20个在深度学习、数据分析中最常用、最好用的Python库,供大家一起学习。
作者| ActiveWizards
编译|专知
整理|Yingying,李大囧
核心库与统计
NumPy
我们从科学应用程序库开始说起,NumPy是该领域的主要软件包之一。 它旨在处理大型多维数组和矩阵,并且广泛的高级数学函数和实现的方法集合,使得可以使用这些对象执行各种操作。
在这一年中,NumPy有很多更新。 除了错误修复和兼容性问题之外,关键更新还包括NumPy对象的打印格式。此外,某些函数现在可以处理Python中可用的任何编码的文件。
SciPy
另一个科学计算核心库是SciPy。它基于NumPy,并扩展了其功能。 SciPy主数据结构又是一个多维数组,由Numpy实现。该软件包包含有助于解决线性代数,概率论,积分计算和更多任务的工具。
SciPy可以适配不同的操作系统。这一年,Scipy带来了许多函数的更新,尤其是优化器也更新了。此外,封装了许多新的BLAS和LAPACK函数。
Pandas
Pandas提供了高级数据结构和各种分析工具。该软件包的一大特色是能够将相当复杂的数据操作转换为一个或两个命令。 Pandas包含许多用于分组,过滤和组合数据的内置方法,以及时间序列功能。
Pandas在这一年的更新包括数百个新功能,bug修复和API的更改。
StatsModels
Statsmodels是一个统用于统计数据分析的方法,例如统计模型估计,执行统计测试等。在它的帮助下,您可以实现许多机器学习方法。
这个库在不停的更新。今年带来了时间序列改进和新的计数模型,即GeneralizedPoisson,零膨胀模型和NegativeBinomialP,以及新的多变量方法 - 因子分析,MANOVA和ANOVA中的重复测量。
可视化
Matplotlib
Matplotlib是一个用于创建二维图表和图形的低级库。 借助它的帮助,您可以构建各种图表,从直方图和散点图到非笛卡尔坐标图。 此外,许多流行的绘图库被设计为与matplotlib一起使用。
颜色,尺寸,字体,图例的样式等都有变化。比如轴图例的自动对齐,和更友好的配色。
Seaborn
Seaborn本质上是基于matplotlib库的更高级别的API。 它包含有丰富的可视化图库,包括时间序列,联合图和小提琴图(展示数据密度分布)等复杂类型。
seaborn更新主要包括bug修复。 此外,FacetGrid或PairGrid与增强的交互式matplotlib后端之间的兼容性有所改进,为可视化添加了参数和选项。
Plotly
Plotly是一个流行的库,可以让您轻松地构建复杂的图形。 该软件包适用于交互式Web应用程序。 其可视化效果包括轮廓图形,三元图和3D图表。
今年该库的更新包括对“多链接视图”以及动画和串扰集成的支持。
Bokeh
Bokeh库使用JavaScript小部件在浏览器中创建交互式和可伸缩的可视化。 该库提供了多种图形,样式及链接图形式的交互能力,定义回调以及更多有用的功能。
Bokeh可以提供改进的交互式功能,例如分类刻度标签的旋转,以及小缩放工具和自定义工具提示字段增强功能。
Pydot
Pydot是Graphviz的一个接口,用纯Python编写。 在它的帮助下,可以显示图形的结构,这在构建神经网络和基于决策树的算法时会经常用到。
机器学习
Scikit-learn
这个基于NumPy和SciPy的Python模块是处理数据的最佳库之一。它为许多标准机器学习和数据挖掘任务提供算法,例如聚类,回归,分类,降维和模型选择。
今年这个库的更新包括:修改交叉验证,提供了使用多个指标的功能;最近邻和逻辑回归等几种训练方法有一些小的改进。
XGBoost / LightGBM / CatBoost
Boosting是最流行的机器学习算法之一,其在于构建基本模型的集合,即决策树。因此,有专门的库设计用于快速方便地实现该方法。XGBoost,LightGBM和CatBoost值得特别关注。这些库提供高度优化,可扩展和快速的梯度增强实现,这使得它们在数据科学家和Kaggle竞赛中非常受欢迎。
Eli5
通常,机器学习模型预测的结果并不完全清楚,而eli5库有助与解决问题。它是一个可视化调试机器学习模型的包,并逐步跟踪算法的工作过程。它可与scikit-learn,XGBoost,LightGBM,lightning和sklearn-crfsuite库兼容。
深度学习
TensorFlow
TensorFlow是一个流行的深度和机器学习框架,由Google Brain开发。它提供了使用具有多个数据集的人工神经网络的能力。最受欢迎的TensorFlow应用包括对象识别,语音识别等。
这个库在新版本中很快,引入了新功能和新功能。最新的修复包括潜在的安全漏洞和改进的TensorFlow和GPU集成,例如您可以在一台计算机上的多个GPU上运行Estimator模型。
PyTorch
PyTorch是一个大型框架,允许使用GPU加速执行张量计算,创建动态计算图并自动计算梯度。在此之上,PyTorch提供了丰富的API,用于解决与神经网络相关的应用。
该库基于Torch,这是一个用C语言实现的开源深度学习库,在Lua中有一个包装器。 Python API于2017年推出,从那时起,该框架越来越受欢迎并吸引了越来越多的数据科学家。
Keras
Keras是一个用于处理神经网络的高级库,运行在TensorFlow,Theano之上。现在它也可以使用CNTK和MxNet作为后端。它简化了许多特定任务,并大大减少了单调代码的数量。但是,它可能不适合某些复杂的事情。
该库在性能,可用性,文档和API都有一定改进。一些新功能是Conv3DTranspose层,新的MobileNet应用程序和自我规范化网络。
分布式深度学习
Dist-keras / elephas / spark-deep-learning
使用像Apache Spark这样的分布式计算系统可以更轻松地处理如此大量的数据,这再次扩展了深度学习的可能性。因此,dist-keras,elephas和spark-deep-learning正在迅速发展。这些软件包可以在Apache Spark的帮助下直接基于Keras库训练神经网络。 Spark-deep-learning还提供了使用Python神经网络创建管道的工具。
自然语言处理
NLTK
NLTK是一组库,是自然语言处理的完整平台。 在NLTK的帮助下,您可以通过各种方式处理和分析文本,标记文本,提取信息等。NLTK还用于原型设计和构建研究系统。
这个库的附魔包括API和兼容性的微小变化以及CoreNLP的新界面。
SpaCy
SpaCy是一个自然语言处理库,包含优秀的demo,API文档和演示应用程序。该库是用Cython语言编写的,它是Python的C扩展。它支持近30种语言,提供简单的深度学习集成,并保证了稳健性和高准确性。 SpaCy的另一个重要特性它是为整个文档处理而设计的,而不会将文档分成短语。
Gensim
Gensim是一个用于强大语义分析,主题建模和向量空间建模的Python库,基于Numpy和Scipy构建。它提供了流行的NLP算法的实现,例如word2vec。
数据抓取
Scrapy
Scrapy是一个用于创建扫描网站页面和收集结构化数据的爬虫库。此外,Scrapy可以从API中提取数据。由于其可扩展性和可移植性,该库恰好非常方便。
结论
与去年相比,一些新的库越来越受欢迎,而那些已成为数据科学任务经典库正在不断改进。
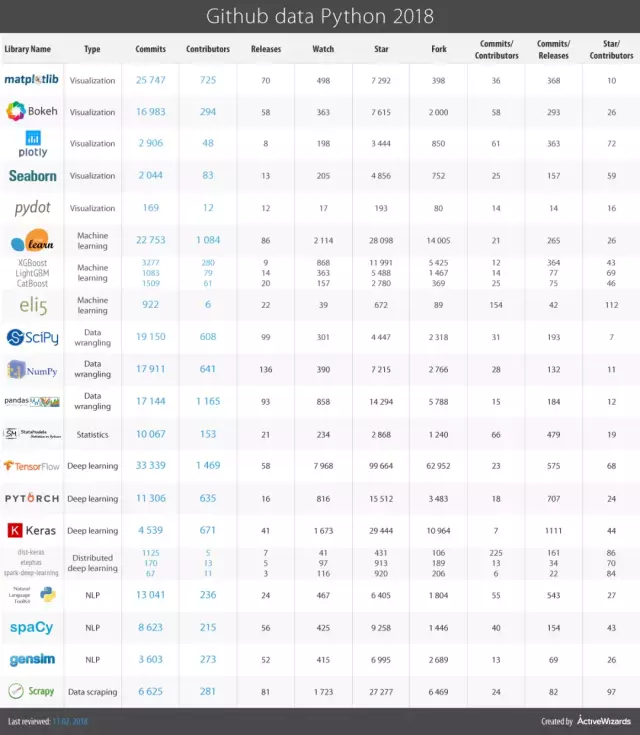
表格中列出了这些库的github活动的详细统计信息。
编辑:hfy
-
Pandas:Python中最好的数据分析工具2023-10-31 1492
-
zip():Python 中最好用的内置类型之一2023-10-30 4401
-
如何安装常用Python库2023-04-14 2252
-
成为Python数据分析师,需要掌握哪些技能2021-06-23 6985
-
从Excel到Python数据分析进阶指南资源下载2021-04-06 1960
-
基于Python的数据分析2020-05-01 1959
-
python数据分析之安装mysql数据库2020-03-20 1510
-
python 数据分析基础 day12-python调用mysql2019-10-23 1600
-
Python中最常用十大图像处理库详细介绍2019-07-06 22727
-
想做好数据分析,不用Python怎么行?2018-11-28 3919
-
怎么有效学习Python数据分析?2018-06-28 3011
-
python数据分析的类库2018-05-10 2800
-
数据分析需要的技能2018-04-10 3359
-
数据分析必备的NumPy技巧(Python)2018-03-05 6708
全部0条评论

快来发表一下你的评论吧 !
