

鸿蒙系统 IO栈和Linux IO栈对比分析
描述
华为的鸿蒙系统开源之后第一个想看的模块就是 FS 模块,想了解一下它的 IO 路径与 linux 的区别。现在鸿蒙开源的仓库中有两个内核系统,一个是 liteos_a 系统,一个是 liteos_m 系统。两者的区别主要是适应的场景不一样,liteos_a 系统适用于硬件资源更加丰富的场景,比如 CPU 更强,内存更大;而 liteos_m 系统则适用于 IoT 设备,相对来说硬件资源比较弱一些。所以我们就拿 liteos_a 系统来分析一下它的 IO 栈吧,毕竟它应对的场景更加复杂一些。
鸿蒙系统 liteos_a Kernel 的下载地址在这:https://gitee.com/openharmony/kernel_liteos_a。
1.FS 源码结构
下载内核源码后发现 fs 目录下似乎缺少很多东西。
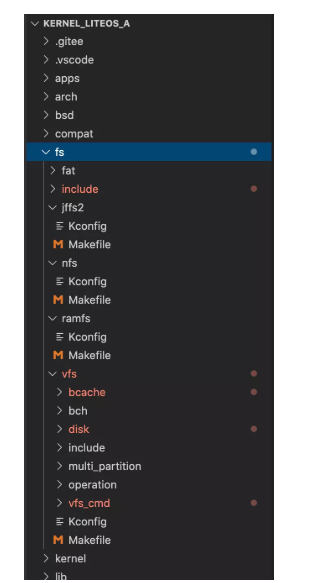
当时觉得好奇怪,啥都没有,那它的 shell 相关命令是怎么使用 fs 模块进行读写的呢?于是发现鸿蒙的 FS 模块主要是从 Nuttx (注:Nuttx 是 Apache 正在孵化的实时操作系统内核)那里借用了 FS 的相关实现。这是从内核的 fs.h 引用的路径发现的,它引用的路径内容如下:
../../../../../third_party/NuttX/include/nuttx/fs/fs.h
所以我们需要找到这个模块,在 gitee 的仓库中搜索 Nuttx 发现的确有这个仓库,所以我们需要联合两个仓库的代码一起解读 IO 栈的源码。Nuttx 的仓库地址为:https://gitee.com/openharmony/third_party_NuttX。
我们来看一下 Nuttx 的目录结构:
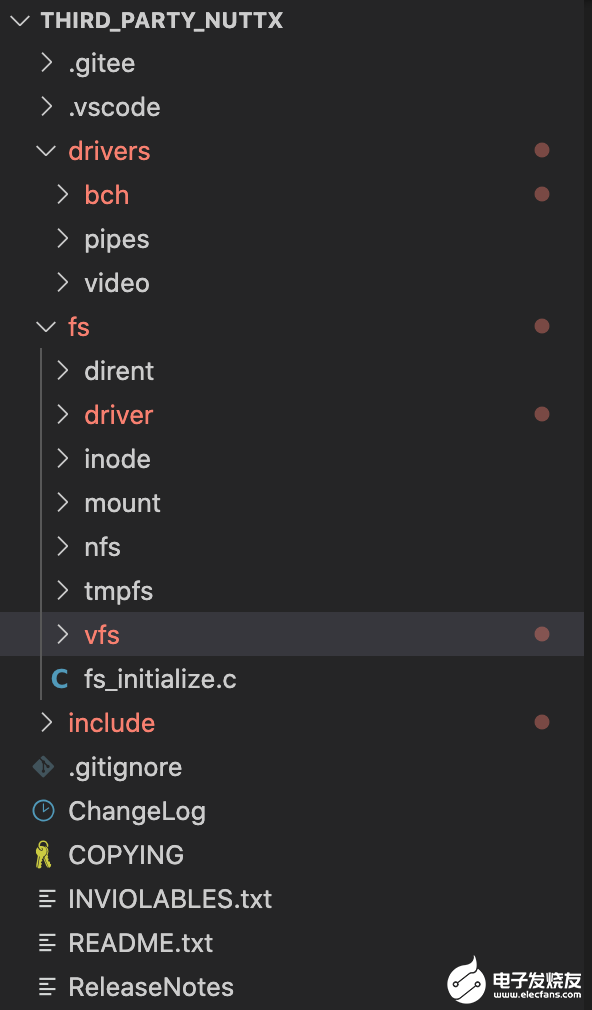
可以发现 FS 的具体实现都在这个 Nuttx 仓库内。接下来我们来看看鸿蒙系统的 IO 栈吧,因为 IO 栈的路径比较多,所以我们选取块设备(block device)的路径来分析。
2. IO 整体架构
鸿蒙系统关于块设备的 IO 栈路径整体架构如下图所示:
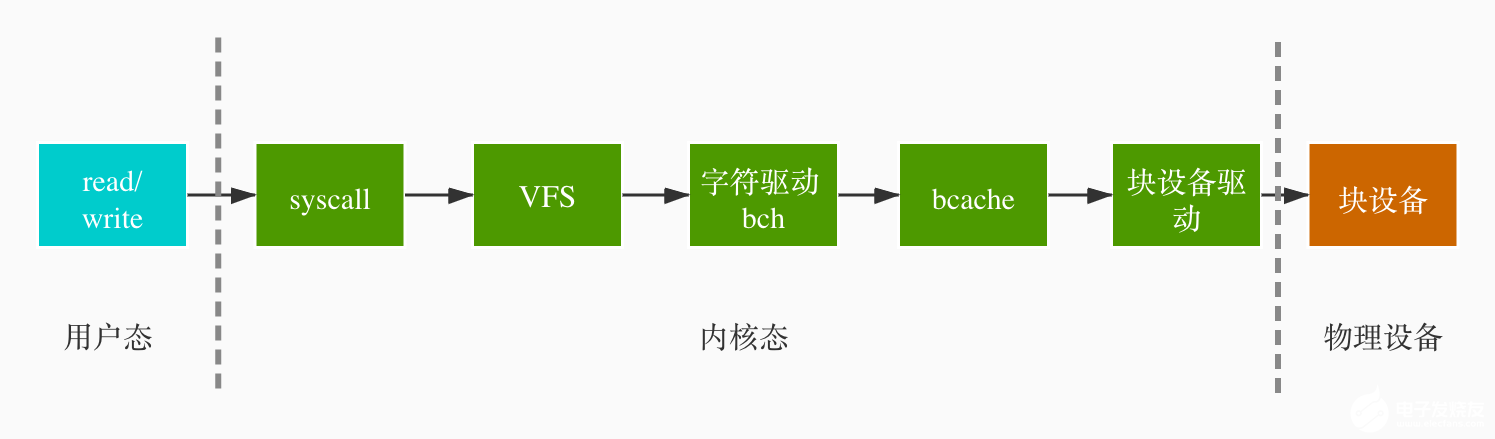
整体 IO 流程如下:
上层应用会在用户态下调用 read / write 接口,这会触发系统调用(syscall)进入内核态;
系统调用往下调用 VFS 的接口,如 read 则对应 read,write 对应 write;
VFS 这层会根据 fd 对应的 file 结构拿出超级块的 inode,利用这个 inode 继续往下调用具体 driver 的 read / write 接口;
在块设备的场景下,它是利用字符设备的驱动作为它的代理,也就是 driver 下面的 bch。鸿蒙系统的设备驱动中并没有块设备的驱动,所以它做了一层 block_proxy,无论是字符设备还是块设备的 IO 都会经过 bch 驱动。数据所位于的扇区以及偏移量(offset)计算位于这层;
IO 往下走会有一层缓存,叫 bcache。bcache 采用红黑树管理这些缓存的数据;
IO 再往下走就是块设备的驱动,内核没有通用的块设备驱动实现,它应该是由不同的厂商来实现的。
3.鸿蒙 IO 流程源码解读
读写流程大致一样,我们就看一下鸿蒙的读数据流程吧。由于函数的源码比较长,全贴出来也不太好,所以太长的源码我只将关键的部分截出。
3.1 上层应用读取数据
上层应用调用 read 接口,这个是系统的 POSIX 接口,read 接口原型如下:
#includessize_t read(int fd, void *buf, size_t count);
3.2 VFS
上层应用在用户态调用 read 接口后会触发系统调用,这个系统调用在 Kernel 的如下文件中进行注册:
syscall/fs_syscall.c
对应的系统调用函数为
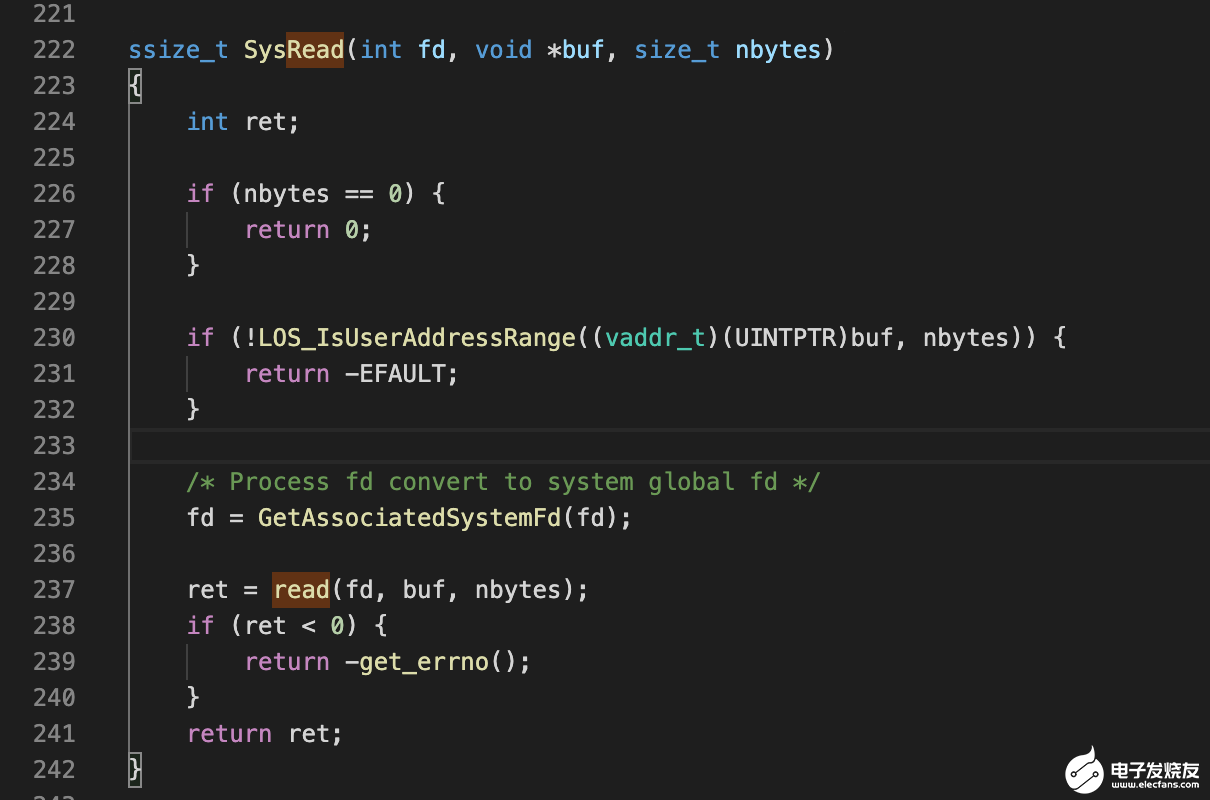
237 行的 read 调用的是 VFS 这层的 read,VFS 这层的 read 函数实现位于 Nuttx 项目的如下路径:
fs/vfs/fs_read.c
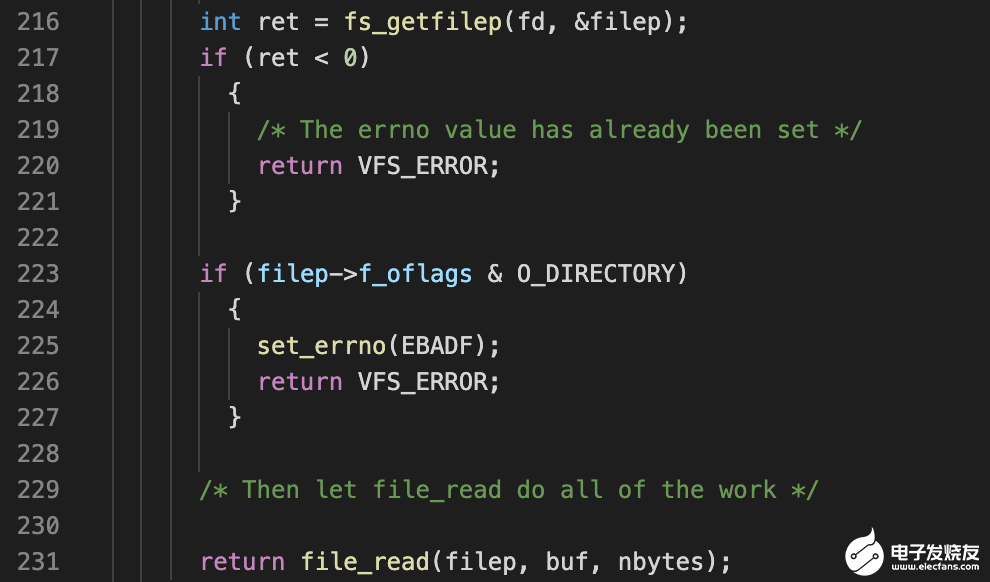
read函数从 fd (文件描述符)中获取对应的 file 对象指针,然后在调用 file_read 接口。file_read 也和 read 函数位于同一个文件下。它从 file 对象中获取了超级块的 inode 对象,然后使用这个 inode 调用 bch 驱动的 read 函数。
3.3 bch 驱动
bch 驱动是一个字符设备驱动,它被用来当做上层与块设备驱动的中间层。注册块设备驱动时会调用 block_proxy 来做代理转换,它的实现位于:
fs/driver/fs_blockproxy.c
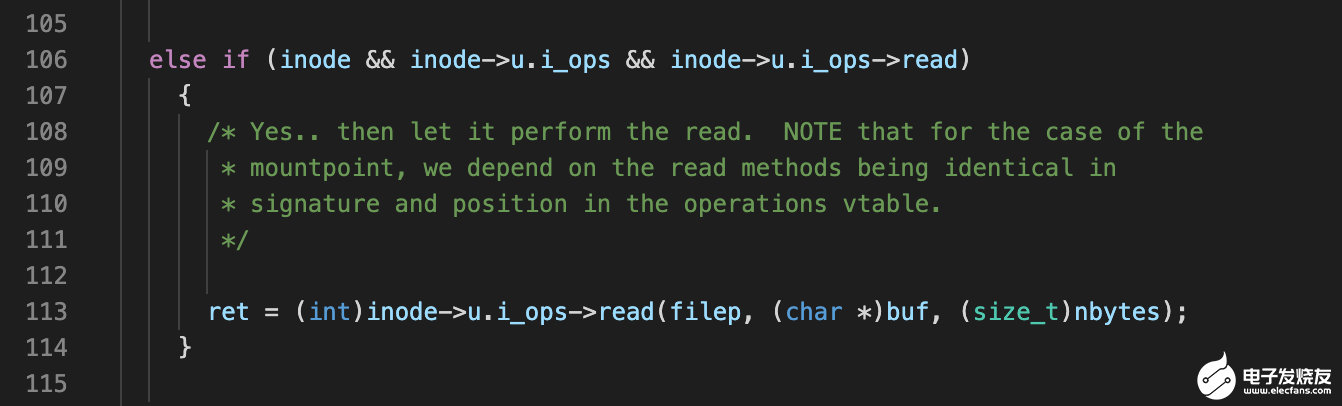
当打开(open)一个块设备时,内核会判断 inode 是否是块设备类型,如果是则调用 block_proxy 来做转换处理。 当上层调用 u.i_ops->read 时,它对应的是 bch_read,它的实现位于:
drivers/bch/bchdev_driver.c
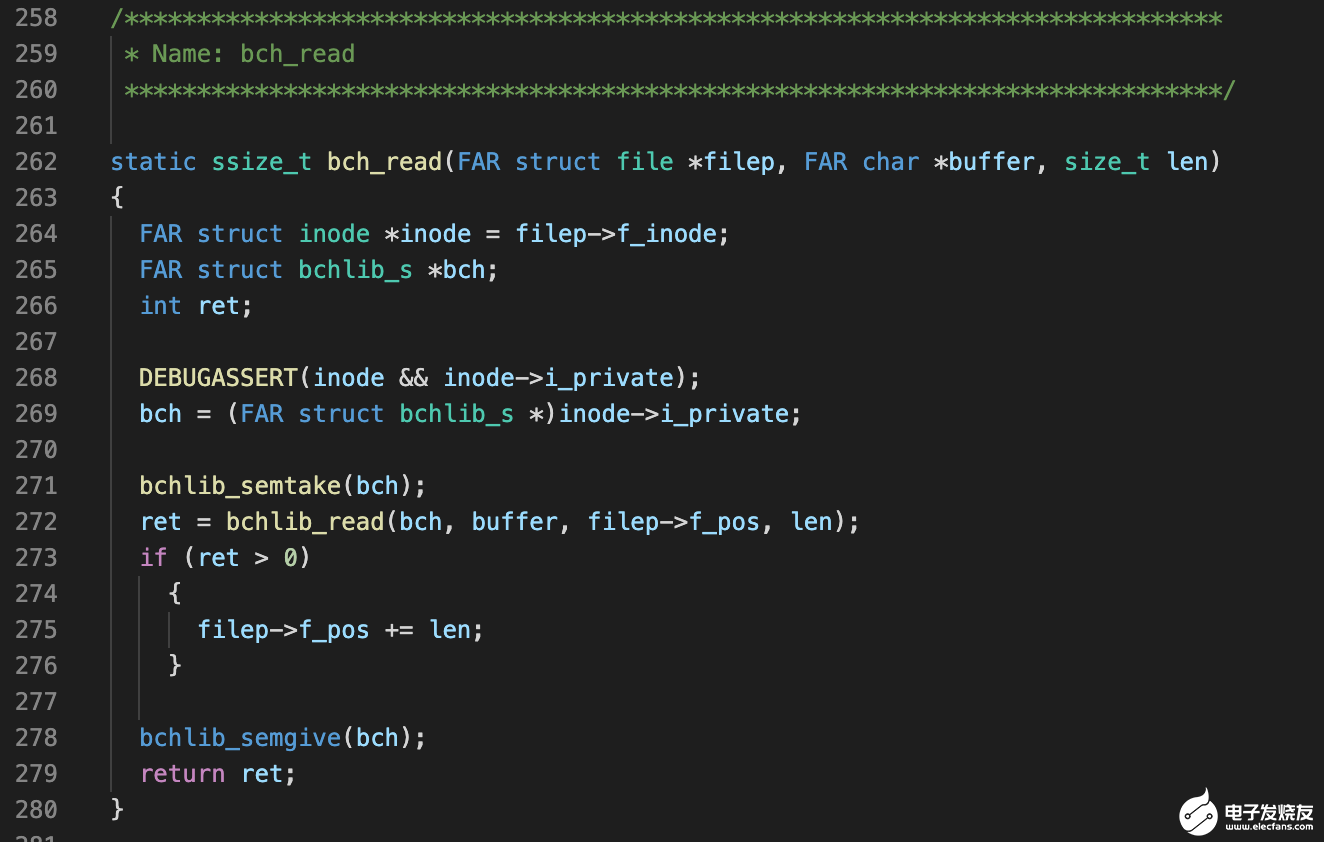
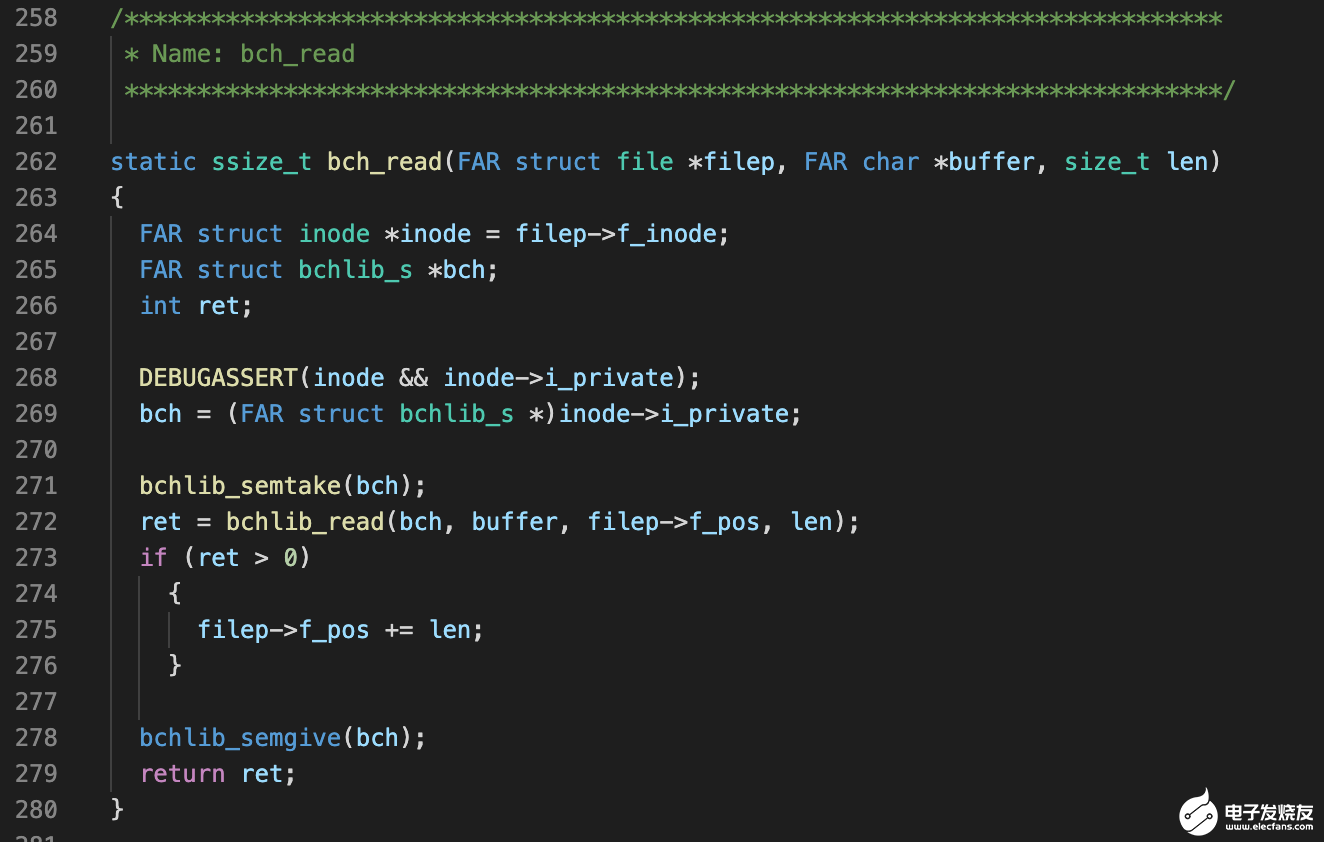
bch_read 会接着调用 bchlib_read,这个函数的实现位于:
drivers/bch/bchlib_read.c
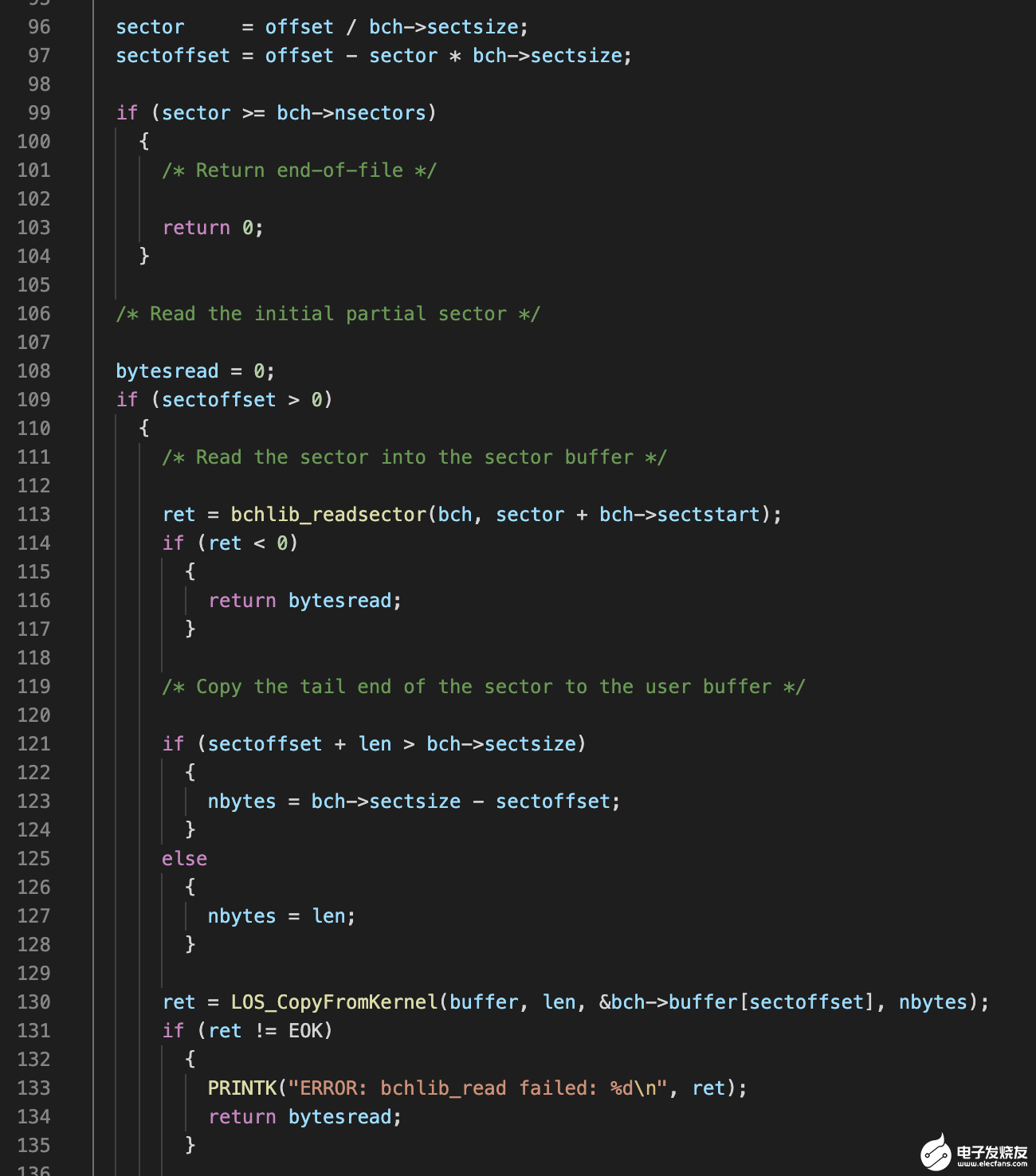
它会根据偏移(offset)计算出在哪个扇区进行读数据,如果要读取的数据只是某个扇区的一部分,则它会先利用 bchlib_readsector 将这个扇区全部读出来,然后再把对应的那部分数据拷贝到内存并返回。 bchlib_readsector 的实现位于如下位置:
drivers/bch/bchlib_cache.c
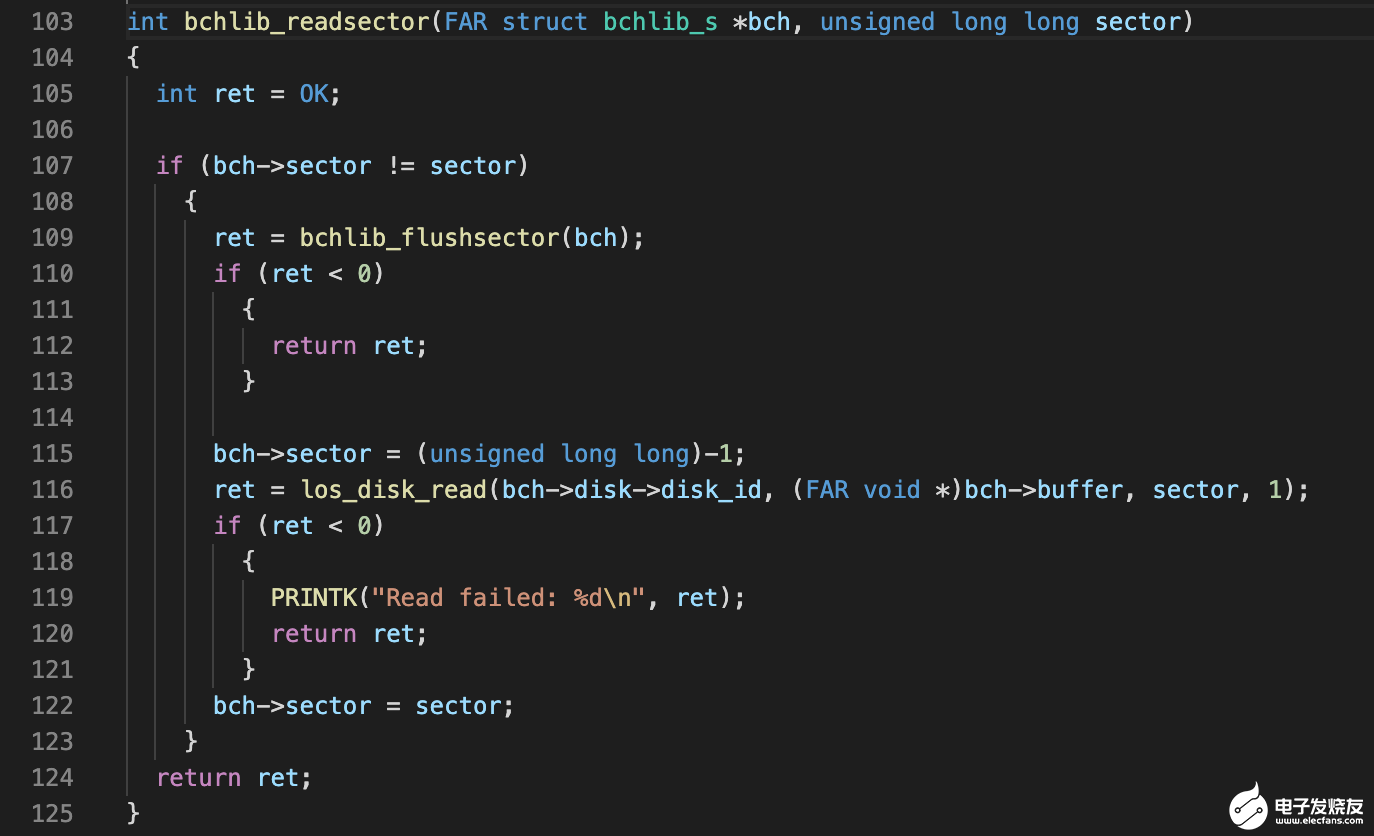
它会先将位于内存的脏数据下刷,等脏数据都下刷完成后才会利用 los_disk_read 把数据从磁盘上读上来。 los_disk_read 的实现位于 kernel 的如下位置:
fs/vfs/disk/disk.c
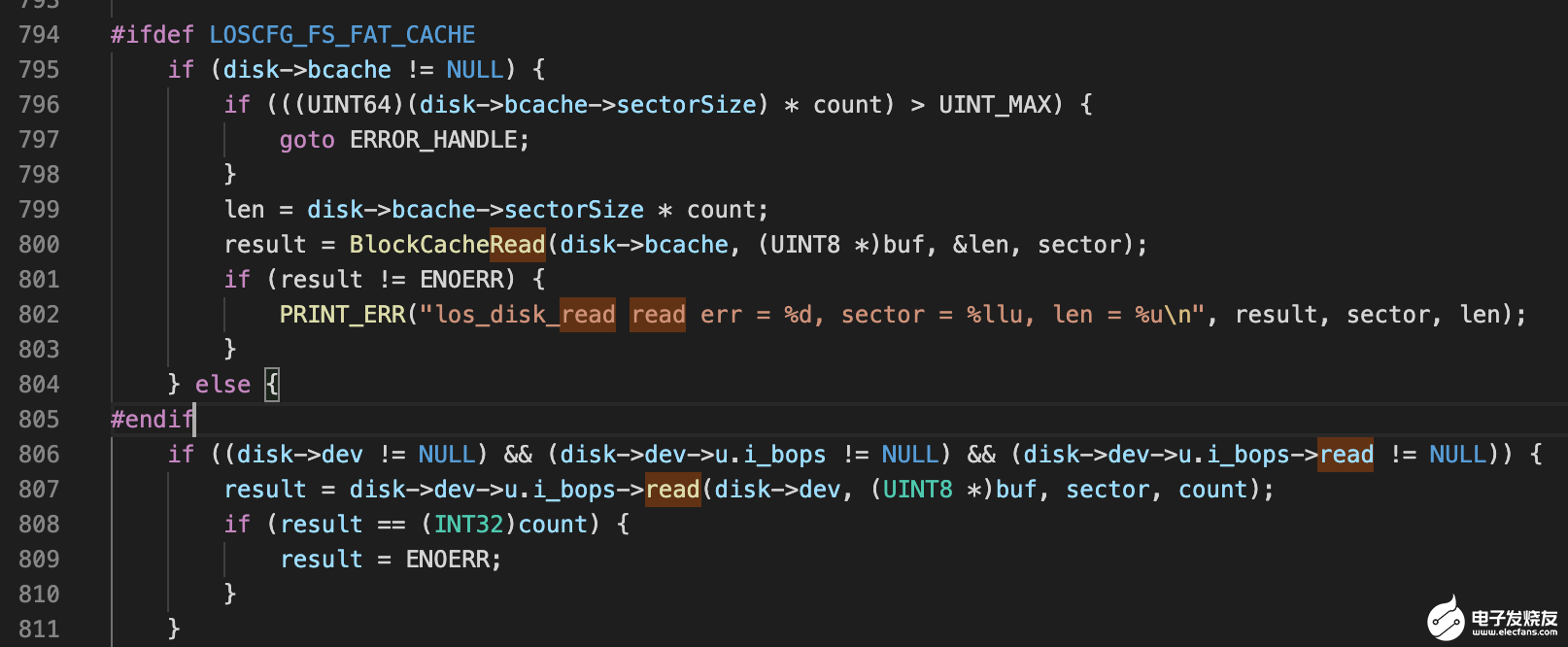
这 los_disk_read 这层会有一层缓存,叫 bcache。它会把每次 IO 的扇区缓存到内存中,缓存的组织方式为红黑树。它是有大小限制的,不是无限增长,具体大小与内存大小有关。 los_disk_read 在读数据之前会先从 bcache 缓存中查找有没有对应的缓存扇区,如果有则直接将这个扇区返回,如果没有则调用真正块设备的 read 函数。这个 read 函数在内核中没有对应的实现,所以它是跟随每个块设备的驱动的不同而不同。
整个读数据流程源码分析就到这里。
鸿蒙系统的 IO 栈分支比较多,这次的源码解读选用了块设备的分支进行分析,希望可以帮助大家更好的理解鸿蒙系统。最后我还想做一下鸿蒙系统与 Linux 关于 IO 栈的对比。
4.鸿蒙 IO 栈与 Linux IO 栈的对比
如果有研究过 linux IO 栈的同学应该能体会到鸿蒙的 IO 栈是比较简单。先来看一下 Linux 的 IO 栈整体架构图:
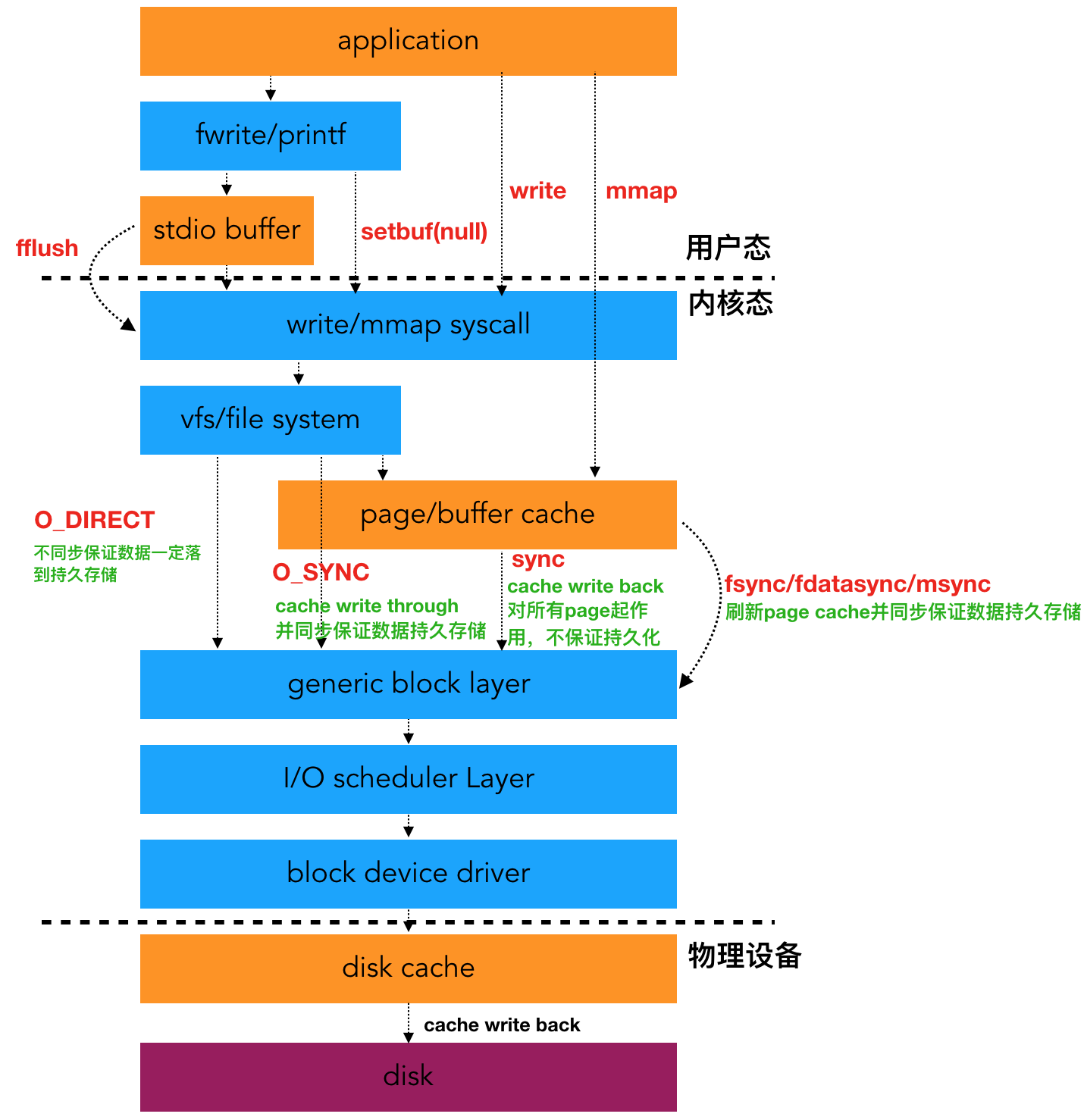
所以,我们对比一下鸿蒙系统和 Linux IO 栈的主要区别吧:
鸿蒙没有 pagecache。所以鸿蒙的系统调用加不加 O_SYNC 应该是一样的,都是直接下到磁盘。
鸿蒙没有通用块层和 IO 调度层。在 Linux 中通用块层是用来将连续的块请求组成一个 bio 结构体,便于对接下层的调度管理。调度层的目的则是用来减少 IO 寻址时间,在这层也有多种调度算法可以选择,如 cfq/deadline/noop 等。我觉得鸿蒙不是没有这两层,而是还没有做,目前只是 IoT 的适用场景。等明年适用于手机的时候再看看,我觉得应该也会做相关的处理,只不过不一定与 Linux 的处理一样。
鸿蒙的驱动层次不够完整,需要用字符设备的驱动来代理块设备的驱动,不知道这是基于什么考虑。
鸿蒙 bcache 的作用与 linux 的 pagecache 作用基本一致,只不过它们在 IO 栈上所在的位置不一样。
编辑:hfy
-
λ-IO:存储计算下的IO栈设计2024-12-02 1377
-
亚信电子于IAS 2024展出最新IO-Link主站&设备软件协议栈解决方案2024-09-18 1424
-
Linux网络协议栈的实现2024-09-10 2566
-
初识IO-Link及IO-Link设备软件协议栈2024-07-08 5748
-
亚信电子推出全新IO-Link设备软件协议栈解决方案2024-01-16 1402
-
异步IO框架iouring介绍2023-11-09 5665
-
linux异步io框架iouring应用2023-11-08 1927
-
linux中的进程栈,线程栈,内核栈的区别2023-08-18 960
-
查看linux系统磁盘io情况的办法是什么2023-08-01 2946
-
系统调用:用户栈与内核栈的切换(上)2023-07-31 2103
-
常用的嵌入式操作系统是什么?Linux OS/palm OS与Windows CE对比分析哪个好?2021-04-27 1913
-
浅谈鸿蒙内核源码的栈2021-04-24 2551
-
请问能不能知道ZigBee协议栈中使用了哪些IO口资源?2018-08-09 3222
-
Linux平台双协议栈主机网络管控系统设计与实现2017-01-07 947
全部0条评论

快来发表一下你的评论吧 !
