

关于Spark on Kubernetes实现方案
电子说
描述
大数据时代,以Oracle为代表的数据库中间件已经逐渐无法适应企业数字化转型的需求,Spark将会是比较好的大数据批处理引擎。而随着Kubernetes越来越火,很多数字化企业已经把在线业务搬到了Kubernetes之上,并希望在此之上建设一套统一的、完整的大数据基础架构。那么Spark on Kubernetes面临哪些挑战?又该如何解决?
云原生背景介绍与思考
“数据湖”正在被越来越多人提起,尽管定义并不统一,但企业已纷纷投入实践,无论是在云上自建还是使用云产品。
阿里云大数据团队认为:数据湖是大数据和AI时代融合存储和计算的全新体系。为什么这么说?在数据量爆发式增长的今天,数字化转型成为IT行业的热点,数据需要更深度的价值挖掘,因此确保数据中保留的原始信息不丢失,应对未来不断变化的需求。当前以Oracle为代表的数据库中间件已经逐渐无法适应这样的需求,于是业界也不断地产生新的计算引擎,以便应对大数据时代的到来。企业开始纷纷自建开源Hadoop数据湖架构,原始数据统一存放在对象存储OSS或HDFS系统上,引擎以Hadoop和Spark开源生态为主,存储和计算一体。
图1是基于ECS底座的EMR架构,这是一套非常完整的开源大数据生态,也是近10年来每个数字化企业必不可少的开源大数据解决方案。
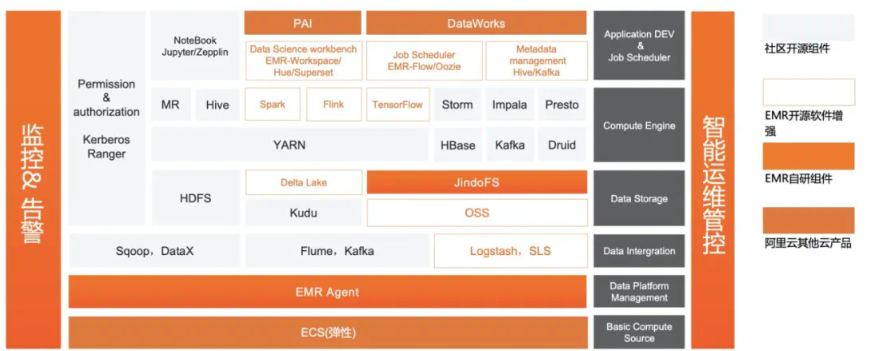
图1 基于ECS的开源大数据解决方案
主要分为以下几层:
ECS物理资源层,也就是Iaas层。
数据接入层,例如实时的Kafka,离线的Sqoop。
存储层,包括HDFS和OSS,以及EMR自研的缓存加速JindoFS。
计算引擎层,包括熟知的Spark,Presto、Flink等这些计算引擎。
数据应用层,如阿里自研的Dataworks、PAI以及开源的Zeppelin,Jupyter。
每一层都有比较多的开源组件与之对应,这些层级组成了最经典的大数据解决方案,也就是EMR的架构。我们对此有以下思考:
是否能够做到更好用的弹性,也就是客户可以完全按照自己业务实际的峰值和低谷进行弹性扩容和缩容,保证速度足够快,资源足够充足。
不考虑现有状况,看未来几年的发展方向,是否还需要支持所有的计算引擎和存储引擎。这个问题也非常实际,一方面是客户是否有能力维护这么多的引擎,另一方面是某些场景下是否用一种通用的引擎即可解决所有问题。举个例子来说,Hive和Mapreduce,诚然现有的一些客户还在用Hive on Mapreduce,而且规模也确实不小,但是未来Spark会是一个很好的替代品。
存储与计算分离架构,这是公认的未来大方向,存算分离提供了独立的扩展性,客户可以做到数据入湖,计算引擎按需扩容,这样的解耦方式会得到更高的性价比。
基于以上这些思考,我们考虑一下云原生的这个概念,云原生比较有前景的实现就是Kubernetes,所以有时候我们一提到云原生,几乎就等价于是Kubernetes。随着Kubernetes的概念越来越火,客户也对该技术充满了兴趣,很多客户已经把在线的业务搬到了Kubernetes之上,并且希望在这种类似操作系统上,建设一套统一的、完整的大数据基础架构。所以我们总结为以下几个特征:
希望能够基于Kubernetes来包容在线服务、大数据、AI等基础架构,做到运维体系统一化。
存算分离架构,这个是大数据引擎可以在Kubernetes部署的前提,未来的趋势也都在向这个方向走。
通过Kubernetes的天生隔离特性,更好的实现离线与在线混部,达到降本增效目的。
Kubernetes生态提供了非常丰富的工具,我们可以省去很多时间搞基础运维工作,从而可以专心来做业务。
EMR计算引擎 on ACK
图2是EMR计算引擎 on ACK的架构。ACK就是阿里云版本的Kubernetes,在兼容社区版本的API同时,做了大量的优化。在本文中不会区分ACK和Kubernetes这两个词,可以认为代表同一个概念。
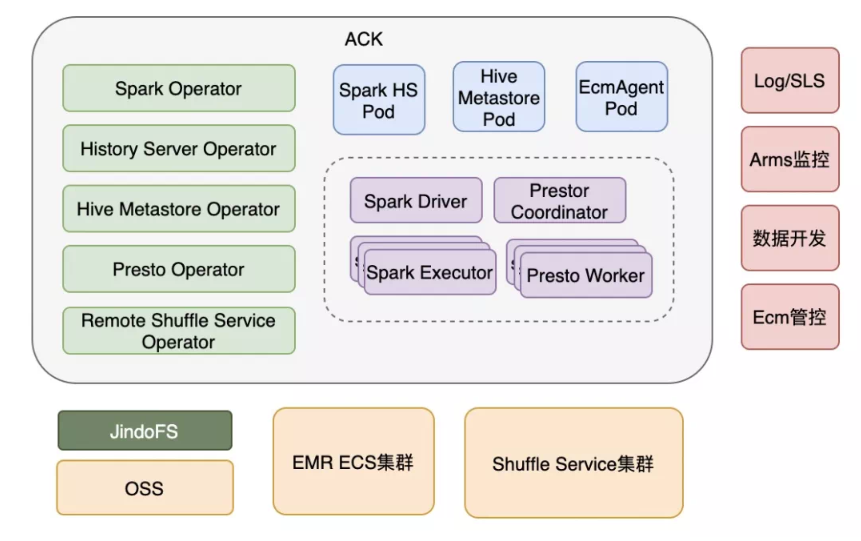
图2 计算引擎Kubernetes化
基于最开始的讨论,我们认为比较有希望的大数据批处理引擎是Spark和Presto,当然我们也会随着版本迭代逐步的加入一些比较有前景的引擎。
EMR计算引擎提供以Kubernetes为底座的产品形态,本质上来说是基于CRD+Operator的组合,这也是云原生最基本的哲学。我们针对组件进行分类,分为service组件和批处理组件,比如Hive Metastore就是service组件,Spark就是批处理组件。
图中绿色部分是各种Operator,技术层面在开源的基础上进行了多方面的改进,产品层面针对ACK底座进行了各方面的兼容,能够保证用户在集群中很方便的进行管控操作。右边的部分,包括Log、监控、数据开发、ECM管控等组件,这里主要是集成了阿里云的一些基础设施。我们再来看下边的部分:
引入了JindoFS作为OSS缓存加速层,做计算与存储分离的架构。
打通了现有EMR集群的HDFS,方便客户利用已有的EMR集群数据。
引入Shuffle Service来做Shuffle 数据的解耦,这也是EMR容器化区别于开源方案的比较大的亮点,之后会重点讲到。
这里明确一下,由于本身Presto是无状态的MPP架构,在ACK中部署是相对容易的事情,本文主要讨论Spark on ACK的解决方案。
Spark on Kubernetes的挑战
整体看,Spark on Kubernetes面临以下问题:
我个人认为最重要的,就是Shuffle的流程,按照目前的Shuffle方式,我们是没办法打开动态资源特性的。而且还需要挂载云盘,云盘面临着Shuffle数据量的问题,挂的比较大会很浪费,挂的比较小又支持不了Shuffle Heavy的任务。
调度和队列管理问题,调度性能的衡量指标是,要确保当大量作业同时启动时,不应该有性能瓶颈。作业队列这一概念对于大数据领域的同学应该非常熟悉,他提供了一种管理资源的视图,有助于我们在队列之间控制资源和共享资源。
读写数据湖相比较HDFS,在大量的Rename,List等场景下性能会有所下降,同时OSS带宽也是一个不可避免的问题。
针对以上问题,我们分别来看下解决方案。
Spark on Kubernetes的解决方案
Remote Shuffle Service架构
Spark Shuffle的问题,我们设计了Shuffle 读写分离架构,称为Remote Shuffle Service。首先探讨一下为什么Kubernetes不希望挂盘呢,我们看一下可能的选项:
如果用是Docker的文件系统,问题是显而易见的,因为性能慢不说,容量也是极其有限,对于Shuffle过程是十分不友好的。
如果用Hostpath,熟悉Spark的同学应该知道,是不能够启动动态资源特性的,这个对于Spark资源是一个很大的浪费,而且如果考虑到后续迁移到Serverless K8s,那么从架构上本身就是不支持Hostpath的。
如果是Executor挂云盘的PV,同样道理,也是不支持动态资源的,而且需要提前知道每个Executor的Shuffle数据量,挂的大比较浪费空间,挂的小Shuffle数据又不一定能够容纳下。
所以Remote Shuffle架构针对这一痛点、对现有的Shuffle机制有比较大的优化,图3中间有非常多的控制流,我们不做具体的讨论。主要来看数据流,对于Executor所有的Mapper和Reducer,也就是图中的蓝色部分是跑在了K8s容器里,中间的架构是Remote Shuffle Service,蓝色部分的Mapper将Shuffle数据远程写入service里边,消除了Executor的Task对于本地磁盘的依赖。Shuffle Service会对来自不同Mapper的同一partition的数据进行merge操作,然后写入到分布式文件系统中。等到Reduce阶段,Reducer通过读取顺序的文件,可以很好地提升性能。这套系统最主要的实现难点就是控制流的设计,还有各方面的容错,数据去重,元数据管理等等工作。
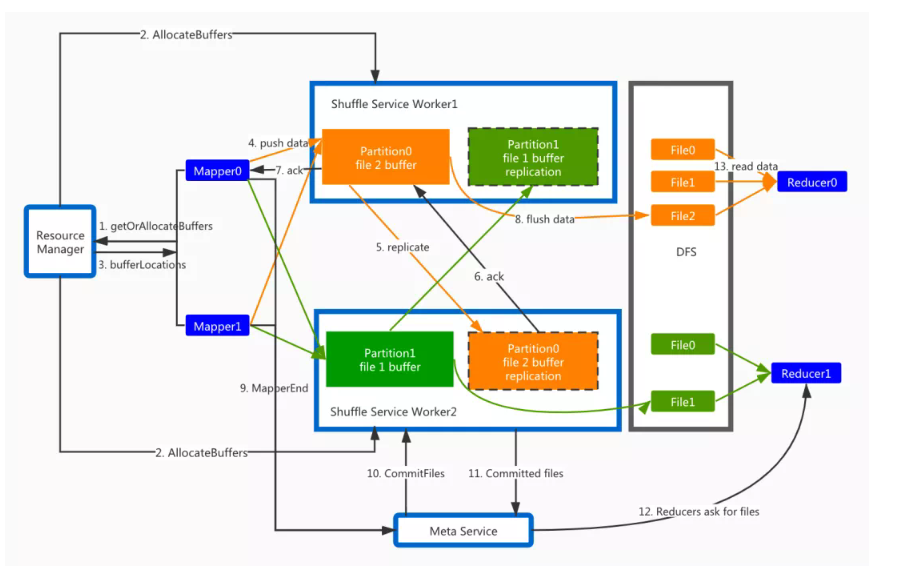
图3 Remote Shuffle Service架构图
简而言之,我们总结为以下3点:
Shuffle数据通过网络写出,中间数据计算与存储分离架构
DFS 2副本,消除Fetch Failed引起的重算,Shuffle Heavy作业更加稳定
Reduce阶段顺序读磁盘,避免现有版本的随机IO,大幅提升性能
Remote Shuffle Service性能
我们在这里展示一下关于性能的成绩,图4和图5是Terasort Benchmark。之所以选取Terasrot这种workload来测试,是因为它只有3个stage,而且是一个大Shuffle的任务,大家可以非常有体感的看出关于Shuffle性能的变化。
图4中,蓝色部分是Shuffle Service版本的运行时间,橙色部分是原版Shuffle的运行时间。我们测试了2T,4T,10T的数据,可以观察到随着数据量越来越大,Shuffle Service优势就越来越明显。图5红框部分说明了作业的性能提升主要体现在Reduce阶段,可见10T的Reduce Read从1.6小时下降到了1小时。原因前边已经解释的很清楚了,熟悉Spark shuffle机制的同学知道,原版的sort shuffle是M*N次的随机IO,在这个例子中,M是12000,N是8000,而Remote Shuffle就只有N次顺序IO,这个例子中是8000次,所以这是提升性能的根本所在。
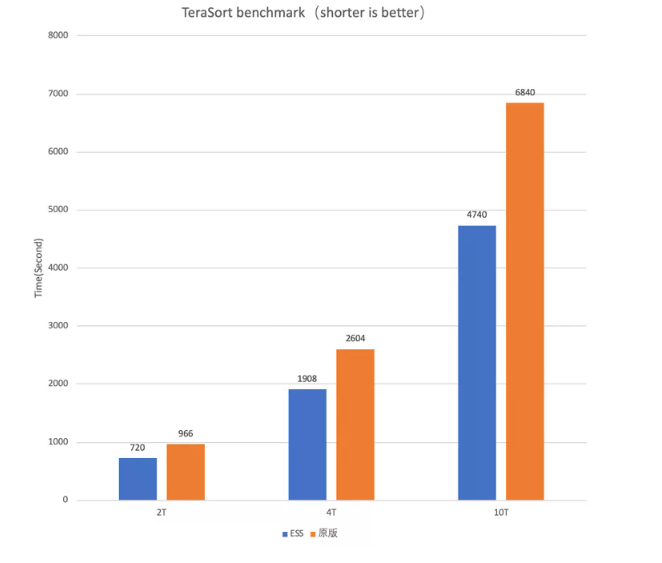
图4 Remote Shuffle Service性能
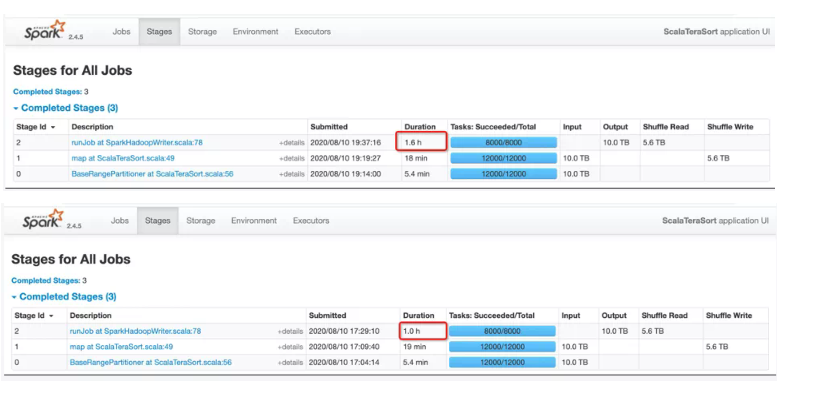
图5 Terasort作业的stage图
其他方面的重点优化
这里讲一下EMR在其他方面做的优化。
调度性能优化,我们解决了开源的Spark Operator的一些不足,对于Executor pod的很多配置Spark Operator把他做到了Webhook里边,这个对调度来说是十分不友好的,因为相当于在API Server上绕了一圈,实际测试下来性能损耗很大。我们把这些工作直接做到Spark内核里边,这样避免了这方面的调度性能瓶颈。然后从调度器层面上,我们保留了两种选择给客户,包括ACK提供的Scheduler FrameworkV2实现方式和Yunicorn实现方式。
读写OSS性能优化,我们这里引入了JindoFS作为缓存,解决带宽问题,同时EMR为OSS场景提供了Jindo Job Committer,专门优化了job commit的过程,大大减少了Rename和List等耗时操作。
针对Spark本身,EMR积累了多年的技术优势,也在TPCDS官方测试中,取得了很好的成绩,包括Spark性能、稳定性,还有Delta lake的优化也都有集成进来。
我们提供了一站式的管控,包括Notebook作业开发,监控日志报警等服务,还继承了NameSpace的ResourceQuota等等。
总体来说,EMR版本的Spark on ACK,无论在架构上、性能上、稳定性上、易用性方面都有着很大的提升。
Spark云原生后续展望
从我的视角来观察,Spark云原生容器化后续的方向,一方面是达到运维一体化,另一方面主要希望做到更好的性价比。我们总结为以下几点:
可以将Kubernetes计算资源分为固定集群和Serverless集群的混合架构,固定集群主要是一些包年包月、资源使用率很高的集群,Serverless是做到按需弹性。
可以通过调度算法,灵活的把一些SLA不高的任务调度到Spot实例上,就是支持抢占式ECI容器,这样可以进一步降低成本。
由于提供了Remote Shuffle Service集群,充分让Spark在架构上解耦本地盘,只要Executor空闲就可以销毁。配合上OSS提供的存算分离,必定是后续的主流方向。
对于调度能力,这方面需要特别的增强,做到能够让客户感受不到性能瓶颈,短时间内调度起来大量的作业。同时对于作业队列管理方面,希望做到更强的资源控制和资源共享。
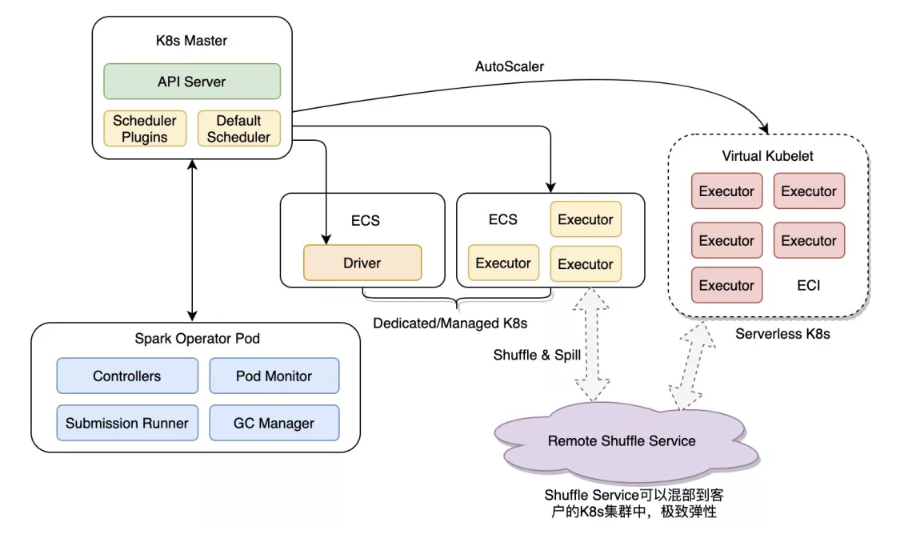
图6 Spark on Kubernetes混合架构
随着阿里云2.0时代的到来,云原生已经逐渐成为新的主角,越来越多的企业将会享受到云原生所带来的红利。数据湖计算引擎云原生容器化,能够极大地方便客户上云,提升性价比。但是整体上来讲:大数据云原生的落地是十分具有挑战性的,阿里云EMR团队会和社区同伴、合作伙伴一起打造技术和生态,共同打造“存算分离,按需扩展”、“极致弹性,随用随得”、“运维闭环,高性价比”的愿景。
编辑:hfy
-
Kubernetes的Device Plugin设计解读2018-03-12 3583
-
容器开启数据服务之旅系列(二):Kubernetes如何助力Spark大数据分析2018-04-17 3603
-
再次升级!阿里云Kubernetes日志解决方案2018-05-28 2520
-
Spark Network Common的实现2019-04-23 1782
-
Spark Core整合实现思路2019-07-05 1862
-
Spark Streaming基础总结2019-09-11 1387
-
Kubernetes平台中的日志收集方案2019-11-04 1857
-
Kubernetes Dashboard实践学习2020-04-10 1952
-
浅谈Kubernetes集群的高可用方案2017-10-11 1188
-
基于Spark的BIRCH算法并行化的设计与实现2017-11-23 1131
-
Kubernetes云平台的弹性伸缩实现方案2021-03-11 1471
-
使用SPARK和Ada进行代码清理2022-06-29 2742
-
SPARK语言可否取代 C语言?2022-11-23 1968
-
基于Kubernetes实现CI/CD配置的流程2023-02-08 2916
-
NVIDIA 携手腾讯开发和优化 Spark UCX 实现性能跃升2023-08-25 1872
全部0条评论

快来发表一下你的评论吧 !
