

一文了解流媒体协议 视频和图片压缩技术解析
电子说
描述
大家都会关注“在浏览器输入一个地址,然后回车,会发生什么”这样一个问题,但是有没有想过这样一个问题:主播开始直播,用户打开客户端观看,这个过程发生了什么?
随着技术的发展,直播技术对人们生活的渗透日益加深。从最开始的游戏直播,到前几天爆出来的教育直播,甚至现在都有直播招聘。
而我们喜欢的这些直播,他们用到的传输协议有一个通用名-流媒体传输协议。
要认识流媒体协议,就离不开下面的三大系列名词。
三大系列名词
系列一:AVI、MPEG、RMVB、MP4、MOV、FLV、WebM、WMV、ASF、MKV。是不是就 MP4 看着熟悉?
系列二:H.261、H.262、H.263、H.264、H.265。能认出来几个?别着急,重点关注 H.264。
系列三:MPEG-1、MPEG-2、MPEG-4、MPEG-7。是不是更懵逼了?
在解释上面的三大系列名词之前,咱们先来了解下,视频究竟是什么?
博主记得小时候,经常会玩一种叫动感画册的东西。一本很小的画册上,每一页都画了一幅图,用手快速的翻过每一页,就能看到一个很短的“动画片”。
没错,咱们看到的视频,本质上就是一连串快速播放的图片。
每一张图片,我们称为一帧。只要每秒钟的数据足够多,也就是播放速度足够快,人眼就看不出是一张张独立的图片。对于人眼而言,这个播放临界速度是每秒 30 帧,而这里的 30 也就是我们常说的帧率(FPS)。
每一张图片,都是由像素组成,而每个像素又是由 RGB 组成,每个 8 位,共 24 位。
我们假设一个视频中的所有图片的像素都是 1024*768,可以大概估算下视频的大小:
每秒钟大小 = 30 帧 x 1024 x 768 x 24 = 566,231,010 Bits = 70,778,880 Bytes
按我们上面的估算,一分钟的视频大小就是 4,,246,732,800 Bytes,这里已经有 4 个 G 了。
是不是和我们日常接触到的视频大小明显不符?这是因为我们在传输的过程中,将视频压缩了。
为什么要压缩视频?按我们上面的估算,一个一小时的视频,就有 240G,这个数据量根本没办法存储和传输。因此,人们利用编码技术,给视频“瘦身”,用尽量少的 Bit 数保持视频,同时要保证播放的时候,画面仍然很清晰。实际上,编码就是压缩的过程。
视频和图片的压缩特点
我们之所以能够对视频流中的图片进行压缩,因为视频和图片有下列这些特点:
空间冗余:图像的相邻像素之间有较强的相关性,一张图片相邻像素往往是渐变的,而不是突变的,没必要每个像素都完整的保存,可以隔几个保存一个,中间的用算法计算出来。
时间冗余:视频序列的相邻图像之间内容相似。一个视频中连续出现的图片也不是突变的,可以根据已有的图片进行预测和推断。
视觉冗余:人的视觉系统对某些细节不敏感,因此不会注意到每一个细节,可以允许丢失一些数据。
编码冗余:不同像素值出现的概率不同,概率高的用的字节少,概率低的用的字节多,类似霍夫曼编码的思路。
从上面这些特点中可以看出,用于编码的算法非常复杂,而且多种多样。虽然算法多种,但编码过程实际上是类似的,如下图:

视频编码的两大流派
视频编码的算法这么多,能不能形成一定的标准呢?当然能,这里咱们就来认识下视频编码的两大流派。
流派一:ITU(International tELECOMMUNICATIONS Union)的 VCEG(Video Coding Experts Group),这个称为国际电联下的 VCEG。既然是电信,可想而知,他们最初是做视频编码,主要侧重传输。我们上面的系列名词二,就是这个组织制定的标准。
流派二:ISO(International Standards Organization)的 MPEG(Moving Picture Experts Group),这个是 ISO 旗下的 MPEG。本来是做视频存储的,就像咱们场面常说的 VCD 和 DVD。后来也慢慢侧重视频传输了。系列名词三就是这个组织制定的标准。
后来,ITU-T(国际电信联盟电信标准化部门)与 MPEG 联合制定了 H.264/MPEG-4 AVC,这也是我们重点关注的。
直播数据传输
视频经过编码之后,生动活泼的一帧帧图像就变成了一串串让人看不懂的二进制。这个二进制可以放在一个文件里,然后按照一定的格式保存起来,这里的保存格式,就是系列名词一。
编码后的二进制文件就可以通过某种网络协议进行封装,放在互联网上传输,这个时候就可以进行网络直播了。
网络协议将编码好的视频流,从主播端推送到服务器,在服务器上有个运行了同样协议的服务端来接收这些网络数据包,从而得到里面的视频流,这个过程称为接流。
服务端接到视频流之后,可以滴视频流进行一定的处理,比如转码,也就是从一个编码格式转成另一种格式,这样才能适应各个观众使用的客户端,保证他们都能看到直播。
流处理完毕后,就可以等待观众的客户端来请求这些视频流。观众的客户端请求视频流的过程称为拉流。
如果有非常多的观众同时看一个视频直播,都从一个服务器上拉流,压力就非常大,因此需要一个视频的分发网络,将视频预先加载到就近的边缘节点,这样大部分观众就能通过边缘节点拉取视频,降低服务器的压力。
当观众将视频流拉下来后,就需要进行解码,也就是通过上述过程的逆过程,将一串串看不懂的二进制转变成一帧帧生动的图片,在客户端播放出来。
整个直播过程,可以用下图来描述:
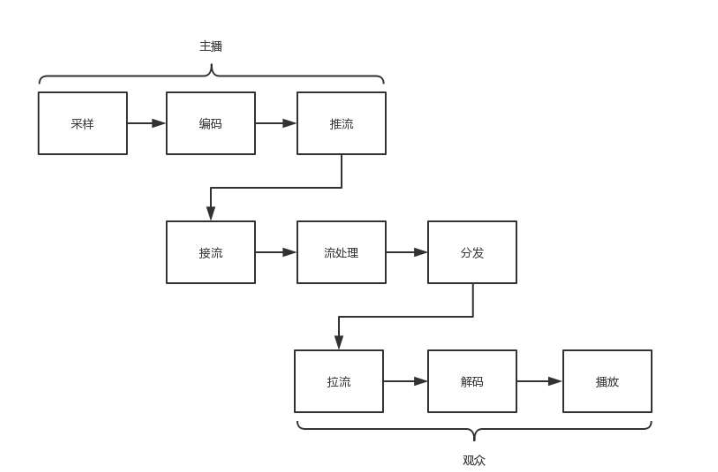
接下来,我们依次来看一下每个过程:
编码:将丰富多彩的图片变成二进制流
虽然我们说视频是一张张图片的序列,但如果每张图片都完整,就太大了,因而会将视频序列分成三种帧:
I帧,也称关键帧。里面是完整的图片,只需要本帧数据,就可以完成解码。
P帧,前向预测编码帧。P 帧表示的是这一帧跟之前一个关键帧(或 P 帧)的差别,解码时需要用之前缓存的画面,叠加上和本帧定义的差别,生成最终画面。
B帧,双向预测内插编码帧。B 帧记录的是本帧与前后帧的差别。要解码 B 帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的数据与本帧数据的叠加,取得最终的画面。
可以看出,I 帧最完整,B 帧压缩率最高,而压缩后帧的序列,应该是 IBBP 间隔出现。这就是通过时序进行编码。
在一帧中,分成多个片,每个片中分成多个宏块,每个宏块分成多个子块,这样将一张大图分解成一个个小块,可以方便进行空间上的编码。如下图:
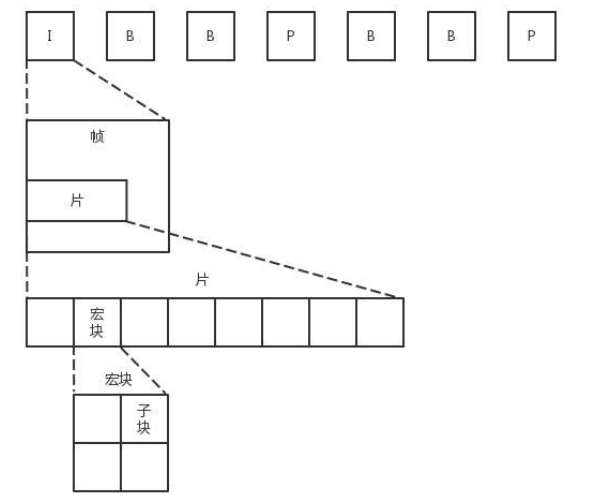
尽管时空非常立体的组成了一个序列,但总归还是要压缩成一个二进制流。这个流是有结构的,是一个个的网络提取层单元(NALU,Network Abstraction Layer Unit)。变成这种格式就是为了传输,因为网络上的传输,默认的是一个个的包,因而这里也就分成了一个个的单元。
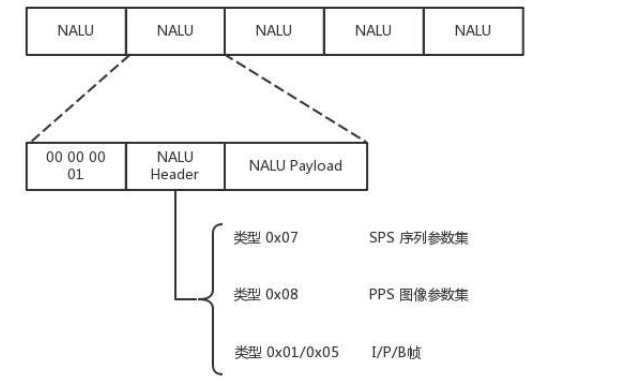
如上图,每个 NALU 首先是一个起始标识符,用于标识 NALU 之间的间隔。然后是 NALU 的头,里面主要配置了 NALU 的类型。最后的 Payload 里面是 NALU 承载的数据。
在 NALU 头里面,主要的内容是类型 NAL Type,其中:
0x07 表示 SPS,是序列参数集,包括一个图像序列的所有信息,如图像尺寸、视频格式等。
0x08 表示 PPS,是图像参数集,包括一个图像的所有分片的所有相关信息,包括图像类型、序列号等。
在传输视频流之前,剥削要传输者两类参数,不然就无法解码。为了保证容错性,每一个 I 帧之前,都会传一遍这两个参数集合。
如果 NALU Header 里面的表示类型是 SPS 或 PPS,则 Payload 中就是真正的参数集的内容。
如果类型是帧,则 Payload 中是真正的视频数据。当然也是一帧帧保存的。前面说了,一帧的内容还是挺多的,因而每一个 NALU 里面保存的是一片。对于每一片,到底是 I 帧,还是 P 帧,亦或是 B 帧,在片结构里面也有 Header,这里面有个类型用来标识帧的类型,然后是片的内容。
这样,整个格式就出来了。一个视频,可以拆分成一系列的帧,每一帧拆分成一系列的片,每一片都放在一个 NALU 里面,NALU 之间都是通过特殊的起始标识符分隔,在每一个 I 帧的第一片前面,要插入单独保存 SPS 和 PPS 的 NALU,最终形成一个长长的 NALU 序列。
推流:将数据流打包传输到对端
形成 NALU 序列后,还需要将这个二进制的流打包成网络包进行发送。这里我们以 RTMP 协议为例,进入第二个过程,推流。
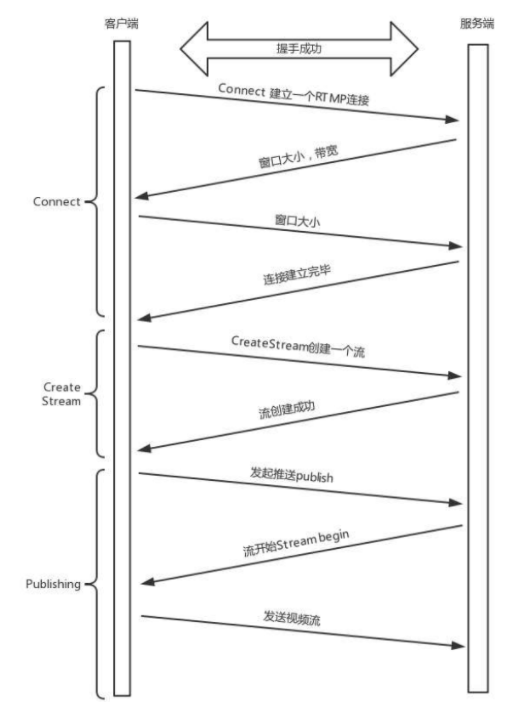
RTMP 是基于 TCP 的,因而也需要双方建立一个 TCP 连接。在有 TCP 的连接的基础上,还需要建立一个 RTMP 连接,也就是在程序里面,我们调用 RTMP 类库的 Connet 函数,显式创建一个连接。
RTMP 为什么需要建立一个单独的连接呢?
因为通信双方需要商量一些事情,保证后续的传输能正常进行。其实主要就是两个事情:
确定版本号。如果客户端、服务端的版本号不一致,就不能正常工作;
确定时间戳。视频播放中,时间是很重要的一个元素,后面的数据流互通的时候,经常要带上时间戳的差值,因而一开始双方就要知道对方的时间戳。
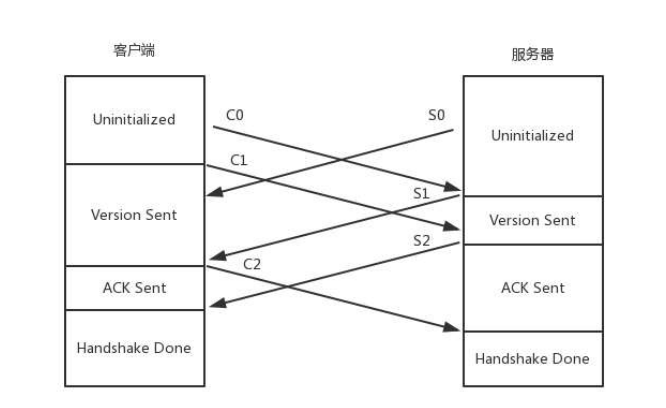
沟通这些事情,需要发送 6 条消息:
客户端发送 C0、C1、C2
服务端发送 S0、S1、S2
首先,客户端发送 C0 表示自己的版本号,不必等对方回复,然后发送 C1 表示自己的时间戳。
服务器只有在收到 C0 的时候,才会返回 S0,表明自己的版本号,如果版本不匹配,可以断开连接。
服务器发送完 S0 后,也不用等待,就直接发送自己的时间戳 S1。
客户端收到 S1 时,发一个知道了最烦时间戳的 ACK C2。同理,服务器收到 C1 的时候,发一个知道了对方时间戳的 ACK S2。
于是,握手完成。
握手之后,双方需要互相传递一些控制信息,例如 Chunk 块的大小、窗口大小等。
真正传输数据的时候,还是需要创建一个流 Stream,然后通过这个 Stream 来推流。
推流的过程,就是讲 NALU 放在 Message 里面发送,这个也称为 RTMP Packet 包。其中,Message 的格式就像下图所示:
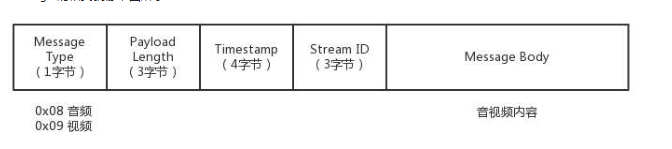
发送的时候,去掉 NALU 的起始标识符。因为这部分对于 RTMP 协议来讲没有用。接下来,将 SPS 和 PPS 参数集封装成一个 RTMP 包发送,然后发送一个个片的 NALU。
RTMP 在收发数据的时候并不是以 Message 为单位的,而是把 Message 拆分成 Chunk 发送,而且必须在一个 Chunk 发送完成之后,才能开始发送下一个 Chunk。每个 Chunk 中都带有 Message ID,表示属于哪个 Message,接收端也会按照这个 ID 将 Chunk 组装成 Message。
前面连接的时候,设置 Chunk 块大小就是指这个 Chunk。将大的消息变为小的块再发送,可以在低带宽的情况下,减少网络拥塞。
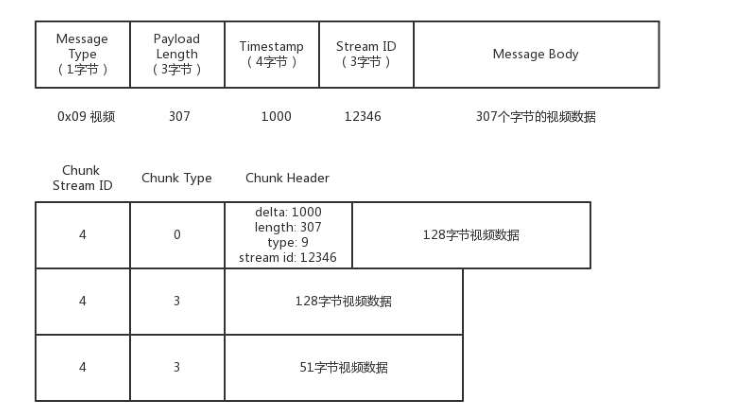
下面用一个分块的示例,来了解下 RTMP 是如何分块的。
假设一个视频的消息长度是 307,而 Chunk 大小约定为 128,那么消息就会被拆分为 3 个 Chunk。
第一个 Chunk 的 Type = 0,表示 Chunk 头是完整的。头里面 Timestamp 为 1000,总长度 Length 为 307,类型为 9,是个视频,Stream ID 为 12346,正文部分承担 128 个字节的 Data。
第二个 Chunk 也要发送 128 个字节,但是由于 Chunk 头和第一个一样,因此它的 Chunk Type = 3,表示头和第一个 Chunk 一样。
第三个 Chunk 要发送的 Data 的长度为 51 个字节,Chunk Type 还是用的 3。
就这样,数据源源不断的到达流媒体服务器,整个过程就像下图:
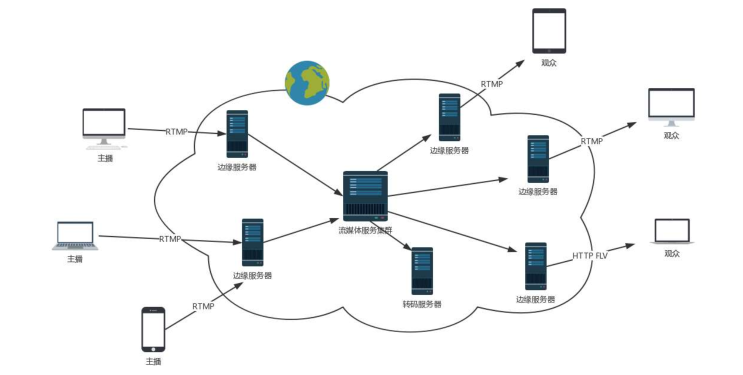
这个时候,大量观看直播的观众就可以通过 RTMP 协议从流媒体服务器上拉取。为了减轻服务器压力,我们会使用分发网络。
分发网络分为中心和边缘两层。边缘层服务器部署在全国各地及横跨各大运营商里,和用户距离很近。而中心层是流媒体服务集群,负责内容的转发。
智能负载均衡系统,根据用户的地理位置信息,就近选择边缘服务器,为用户提供推/拉流服务。中心层也负责转码服务。例如,将 RTMP 协议的码流转换成 HLS 码流。
拉流:观众的客户端看到直播视频
接下来,我们再来看看观众通过 RTMP 拉流的过程。
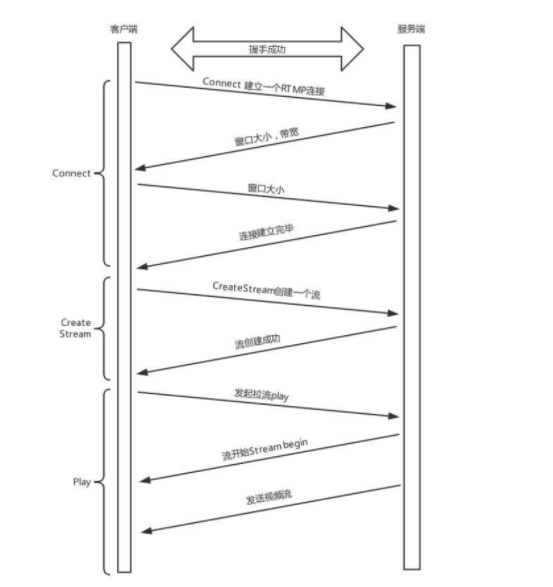
先读到的是 H.264 的解码参数,例如 SPS 和 PPS,然后对收到的 NALU 组成一个个帧,进行解码,交给播放器播放,这样客户端就能看到直播视频了。
小结
视频名词比较多,编码两大流派达成了一致,都是通过时间、空间的各种算法来压缩数据;
压缩好的数据,为了传输而组成一系列的 NALU,按照帧和片依次排列;
排列好的 NALU,在网络传输的是,要按照 RTMP 包的格式进行包装,RTMP 的包会拆分成 Chunk 进行传输;
推送到流媒体集群的视频流经过转码和分发,可以被客户端通过 RTMP 协议拉取,然后组合成 NALU,解码成视频格式进行播放。
编辑:hfy
-
基于流媒体技术的手机视频播放系统的研究与实现2010-04-24 2136
-
流媒体高清视频编码技术应用于视频直播和网络电视台2012-08-10 3897
-
流媒体视频直播技术加快电力行业信息化建设2012-08-23 3645
-
直播软件开发过程中,如何选择流媒体协议?2019-08-21 1936
-
嵌入式Linux机顶盒流媒体播放器的设计流程是什么?2019-08-22 2395
-
什么是流媒体服务器?2021-06-30 6485
-
怎样去编译一个完整的流媒体服务系统呢2021-12-14 1551
-
嵌入式Linux音频流媒体终端系统的设计资料分享2021-12-16 828
-
如何利用协议库对rtp等协议进行处理和程序流程设计呢2022-01-04 2086
-
xplayerdemo播放视频最长只能播放一分钟左右吗?2022-01-13 1559
-
视频流媒体播放器EasyPlayer报IllegalStateException错误如何处理呢2022-09-02 5570
-
基于Directshow的流媒体视频混合及网络传输系统2009-09-03 825
-
基于RTP协议的视频流媒体实时传输2016-05-09 937
-
视频app开发过程中,会用到哪些音视频编解码技术2019-10-15 1390
-
智能猫眼的实现是采用流媒体协议RTSP2022-05-16 4504
全部0条评论

快来发表一下你的评论吧 !
