

基于机器学习方法的网络流量解析
描述
随着大众网络安全意识的稳步提升,对于数据保护的意识也愈加强烈。根据Google的报告,2019年10月,Chrome加载网页中启用加密的比例已经达到了95%。对于特定类型的流量,加密甚至已成为法律的强制性要求,加密在保护隐私的同时也给网络安全带来了新的隐患。攻击者将加密作为隐藏活动的工具,加密流量给攻击者隐藏其命令与控制活动提供了可乘之机。在面临日益严重的网络安全威胁和攻击时,需要提出有效的识别方法。实现加密流量精细化管理,保障计算机和终端设备安全运行,维护健康绿色的网络环境。
01、相关研究
当前对于加密网络流识别的研究主要集中在机器学习相关的方法上。使用机器学习方法对网络流量进行解析时,按使用的机器学习算法不同可以分为传统机器学习算法(浅层学习)和深度学习。传统机器学习算法对加密网络流量解析主要存在两个问题:一个是需要对待分类的报文人工设计一个可以普遍反映流量特征的特征集;另一个就是传统机器学习方法有很大的局限性,例如对复杂函数难以表示、容易陷入局部最优解等。
由于以上两个原因,导致传统机器学习方法对加密网络流量解析的准确率不是很高。随着计算方法的发展和计算能力的提高,深度学习的引入可以有效解决机器学习设计特征的问题。深度学习通过特征学习和分层特征提取的方法来替代手工获取特征。深度神经网络拥有很高的拟合能力,可以逼近许多复杂的函数,不易陷入局部最优解。解决了传统机器学习在加密网络流量解析时存在的两个关键问题。
深度学习是基于表示学习的众多机器学习算法中的一员。目前使用最多的深度学习方法包括DBN(Deep Belief Nets)、CNN(Convolutional Neural Networks)、深度自编码器(AutoEncoder,AE)和循环神经网络(Recurrent Neural Network,RNN)以及基于RNN的长短期记忆网络(Long Short-Term Memory,LSTM),近年来这些方法被广泛地应用在加密流量解析中,并取得了不错的成果。王伟等人提出一种基于CNN的异常流量检测方法,该方法利用CNN特征学习能力,准确地对流量的特征进行提取,将提取到的特征用于流量分类并取得了良好的结果,最终将该模型用于异常流量检测。
J.Ran等人提出了一种将三维卷积神经网络应用于无线网络流量分类的方法,实验结果表明该方法优于一维和二维卷积神经网络。Jain研究了由不同优化器训练的卷积神经网络对协议识别的影响,实验结果表明,随机梯度下降(Stochastic Gradient Descent,SGD)优化器产生的识别效果最好。陈雪娇等利用卷积神经网络的识别准确率高和自主进行特征选择的优势,将其应用于加密流量的识别,测试结果表明该方法优于DPI方法。
王勇等设计了基于LeNet-5深度卷积神经网络的分类方法,通过不断调整参数产生最优分类模型,测试结果表明该方法优于主成分分析、稀疏随机映射等方法。Wu,Kehe等人将网络流量数据的121个流统计特征作为数据集,并对比了一维和二维CNN网络、CNN网络与传统机器学习算法、CNN网络与RNN网络的分类准确性与计算量。
J.Ren等提出了一种针对无线通信网络的协议识别方法,首先利用一维卷积神经网络进行自动化的特征提取,然后基于SVM对应用层协议进行分类。H.Lim等提出了使用深度学习的基于数据包的网络流量分类,该方法提取网络会话中的前几个数据包处理成等长的向量,然后利用CNN和ResNet进行训练,进行流量分类。
在以往的基于深度学习的加密网络流量解析研究中,数据预处理都是只针对原始的网络流量数据进行变换处理,而忽略了数据包在传输过程中的时间特征。因此,在本研究中,将对加密网络流量中的原始报文数据及数据包传输时间间隔进行综合预处理,并采用CNN网络模型进行实验验证。
02、基于CNN的加密网络流量识别方法
本节将从流量采集、数据预处理、加密网络流量识别模型等环节详细介绍本文提出的基于深度学习的加密网络流量解析方法。
2.1流量采集
为了获得更加接近实际使用场景下的网络流量,我们在手机终端安装了代理软件,采集日常真实使用环境下的应用网络流量,并按照应用名称分别保存为不同的文件,共计14类,16.81GB。
2.2数据预处理
采集的网络流量存储为Pcap格式的文件,该格式的文件除了流量数据外,还有该文件协议额外添加的其他信息,而这些信息有可能干扰分类结果。因此需要对该文件的格式进行解析,提取出有用的数据部分。
2.2.1 Pcap格式介绍
Pcap文件格式如图1所示,最开始的24个字节为文件头(Global Header),后面是抓取的包头(Packet Header)和包数据(Packet Data)。此处的包头为Pcap文件格式的固定部分,描述了后面紧跟着的包数据的捕获时间、捕获长度等信息,原始网络数据流量中不包含此部分信息。包数据为数据链路层到应用层的所有数据,包括每一层的包头。

图1 Pcap文件格式
图2描述了Global Header的具体内容以及每部分的长度。
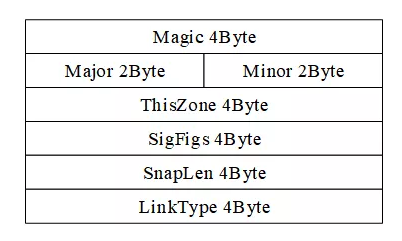
图2 Global Header格式
每个字段的含义如下:
(1)Magic:4Byte,标记文件开始,并用来识别文件自己和字节顺序。0xa1b2c3d4用来表示按照原来的顺序读取,0xd4c3b2a1表示下面的字节都要交换顺序读取。考虑到计算机内存的存储结构,一般会采用0xd4c3b2a1,即所有字节都需要交换顺序读取。
(2)Major:2Byte,当前文件主要的版本号。
(3)Minor:2Byte,当前文件次要的版本号。
(4)ThisZone:4Byte,当地的标准时间。
(5)SigFigs:4Byte,时间戳的精度。
(6)SnapLen:4Byte,最大的存储长度。
(7)LinkType:4Byte,数据链路类型。
图3描述了Packet Header的具体内容以及每部分的长度。

图3 Packet Header格式
每个字段的含义如下:
(1)Timestamp:捕获时间的高位,单位为秒。
(2)Timestamp:捕获时间的低位,单位为微秒。
(3)Caplen:当前数据区的长度,单位为字节。
(4)Len:离线数据长度,网络中实际数据帧的长度。
2.2.2预处理方法
通过图3对Pcap文件格式的介绍,我们发现,Pcap文件中除了原始流量数据之外还有Global Header和Packet Header这两部分原始数据流量中不存在的部分。因此,在接下来的数据处理环节中,我们将剔除这部分数据或者对这部分数据进行转换。预处理流程如下:
首先对采集到的Pcap文件按协议进行过滤,提取出经过加密的网络流量,然后对提取出的流量按五元组进行划分。划分出来的每一个文件将在后续流程中转化为一张图片。对划分出来的每一个Pcap文件做如下处理。
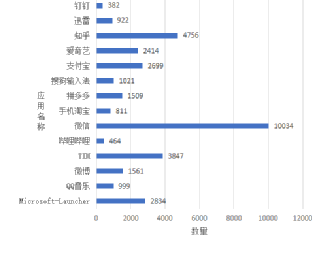
图4每种应用的对应的图片数量
设最后返回的字节数组为A,需要的长度为LEN。
(1)首先忽略前24个字节。
(2)然后读取16个字节的Packet Header,将其中的时间转换为整数,利用其中的捕获长度读取Packet data,忽略掉数据链路层和网络层的包头,将传输层的包头和payload加入字节数组A。
(3)如果不是第一个数据包,则利用本数据包的捕获时间减去上一个数据包的捕获时间,得到时间差Δt,利用本数据包的捕获长度L除以Δt,向上取整得到N,向字节数组A中加入N个0xFF字节。
(4)重复(2)(3)直到文件尾,或者A的长度大于等于LEN。
(5)若读取到文件尾之前,A的长度大于等于LEN,则截断到LEN返回;若读到文件尾,A的长度仍小于LEN,则在末尾填充0x00直到长度为LEN。
(6)将A数组转化为长、宽相同的单通道灰度图片。
最终将生成好的图片存储为TFRecoder格式,以便于后面的实验验证。预处理后每种应用得到的图片数目如图4所示。
2.3加密网络流量识别模型
本文采用了二维CNN模型进行流量分类,为了对比不同输入对实验结果的影响,分别尝试了图片长宽为32、40、48、56、64,其中当长宽为32时效果最佳。下面介绍本文最终采用的CNN模型。
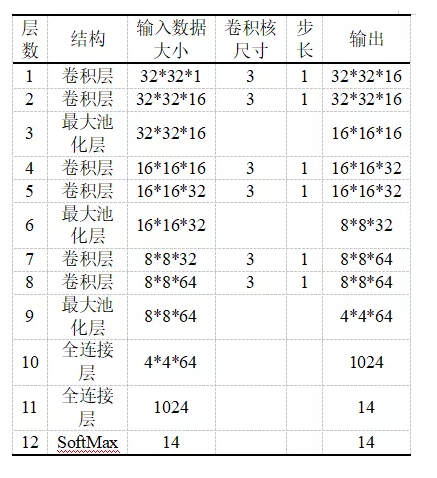
在卷积神经网络中,大尺寸的卷积核可以带来更大的感受视野,获取更多的信息,但也会产生更多的参数,从而增加网络的复杂度。为了减少模型的参数,本文采用两个连续的3*3卷积层来代替单个的5*5卷积层,可以在保持感受视野范围的同时减少参数量。卷积层的Padding方式使用SAME方式,激活函数使用RELU,每一层的参数如表1所示。
表1网络模型参数
03、实验与结果分析
为了对上述加密网络流量识别模型进行验证,采用TensorFlow深度学习框架,在NVIDIA TESLA K80上进行了实验验证。
3.1评价指标
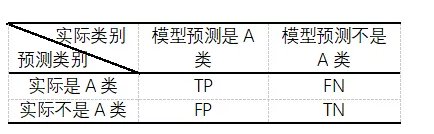
本文采用准确率(accuracy)、精准率(precision)、召回率(recall)和F1-Measure值(以下简称F1值)四个评价指标来对实验结果进行评估,其中准确率是对整体的评价指标,精准率和召回率是用来对某种类别流量识别的评价指标,而F1值是对于精准率和召回率两个指标的综合评估。为了计算这四个指标,需要引入TP、FP、FN、TN四个参数,每个参数的意义如表2混淆矩阵所示。
表2混淆矩阵
每个指标的计算方法如公式(1)~(4)所示。

3.2实验结果
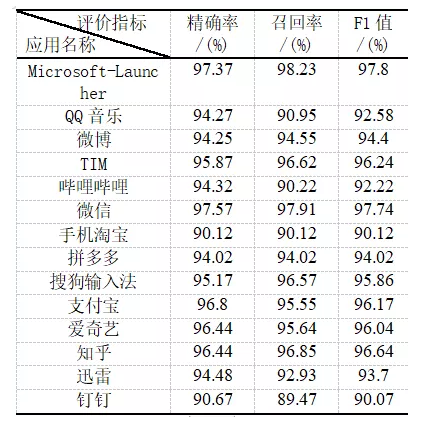
将处理好的数据按4:1的比例分为训练集和测试集,由于采集的数据不均衡,因此在训练时对训练数据采用过采样的方法来缩小数据量之间的差异。采用了Adam优化器和动态学习率来提高模型的训练速度。最终训练好的模型在测试集上的结果如表3所示。
表3测试集结果
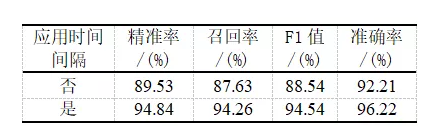
为了验证在预处理阶段引入时间间隔对模型准确率的影响,还做了一组对比实验。对比实验在预处理阶段不对时间间隔做特殊处理,直接舍弃该字段,最终结果如表4所示。可以看出,利用时间间隔可以有效提高分类结果的准确率。
表4不同预处理方式对应的实验结果
04、结语
本文提出了一种基于深度学习的加密网络流量识别方法,该方法对采集到的流量进行预处理,利用传输层数据及数据包之间的时间间隔,将时间间隔转换为二进制数据中的特殊值,然后将解析后的数据转换为灰度图片,采用卷积神经网络对采集到的14类应用的加密流量进行分类,最终识别准确率为96.22%,可以满足实际应用。后续研究将关注流量类型的甄别,即对每种应用流量中不同类型的流量进行识别,如视频流量、文本流量、图片流量等,进一步挖掘用户行为。
编辑:hfy
-
网络流量监控与网关优化2025-01-02 1365
-
传统机器学习方法和应用指导2024-12-30 2562
-
联合学习在传统机器学习方法中的应用2023-07-05 1814
-
面向异质信息的网络表示学习方法综述2021-06-09 973
-
深度解析机器学习三类学习方法2018-05-07 15264
-
IP网络流量矩阵估计方法2018-02-09 1469
-
Linux高速网络流量的监控、计算方法详解2017-12-11 6302
-
基于KPCA优化ESN的网络流量预测方法_田中大2017-01-08 887
-
运营商将能够应对网络流量的增长2011-12-01 2750
-
基于FPGA的网络流量计设计与实现2009-12-18 597
-
基于分组采样组播网络流量预测研究2009-09-25 613
-
浅谈基于PCA的网络流量分析2009-08-15 692
-
网络流量测量的研究与实现2009-08-03 751
-
分布式网络流量监测2009-04-13 726
全部0条评论

快来发表一下你的评论吧 !
