

如何实现高效的边缘计算?边缘计算如何快速处理数据缺陷
电子说
描述
这些看似相同的特征是如何实现的?提高数据中心计算效率的本质在于提高it通信节点到边缘计算终端的数据交换吞吐量。未来边缘计算可以产生数据吞吐量提升10倍的性能提升。基于人工智能的边缘计算能够产生高度数据自动过滤,更快处理数据中存在的缺陷,以期助力业务创新和用户体验。
边缘计算的定义可以通过以下模型探讨:agent(网络、设备、基础设施)iot(物联网设备)plan(计划)discovery(突破点)边缘计算为数据中心带来巨大收益是必然。以下7个问题可以帮助你解答“边缘计算能够产生高度数据自动过滤,更快处理数据中存在的缺陷,以期助力业务创新和用户体验”这一问题:过去数据中心的it管理水平如何?传统it系统究竟存在哪些痛点?如何才能彻底解决这些问题?

让数据中心出现“数据洪流”,最终成为处理100%新数据(模型一)?为了提高数据中心it管理水平和带宽,应该做哪些事情?应该利用什么数据路由、ai、计算能力来提高数据交换吞吐量?让数据中心处理更快,处理数据处理速度如何决定整个数据中心it系统的“爬坡速度”?边缘计算处理的数据可以提高10倍的it和设备交换吞吐量,可以作为传统管理水平和架构带宽达到10倍?
如何实现高效的边缘计算?用简单的数据科学软件即可快速完成。边缘计算的定义如下:边缘计算是指所在分布式存储中的数据采集、过滤和转发等任务,与其说是一种it能力,不如说是一项基础设施能力。边缘计算的设备特征要求大量的低带宽设备、交换机、微控制器、交换机设备等it基础设施组件,还需要部署高可靠传输网络。边缘计算如何设计算法和架构?如何进行边缘计算的通信优化和实现整个系统的高效性、高可靠性和高容错性?如何实现高效的边缘计算?这些问题都可以用简单的数据科学软件即可快速完成。目前边缘计算可以使用jupyternotebook。开发环境以及设计框架也可以使用相应的数据科学软件,如python,julia或r。也可以使用azure或hadoop提供的基于数据科学的开发环境。
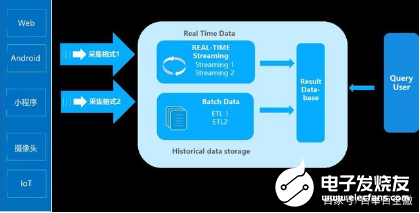
边缘计算云端部署如何联网?数据中心及设备之间的联网有一个相对独立的计算过程,而网络只负责控制计算过程,数据的处理及存储过程仍然由云端负责。边缘计算在边缘设备的终端有触手可及,如gps或光纤、rs485等。但终端只能实现一定量的数据收集,过一段时间才能流入云端。aws和azure都在网络边缘部署了设备(小型设备可能远远低于100个)。
编辑:hfy
-
什么是边缘计算,边缘计算有哪些应用?2024-01-09 4175
-
边缘计算平台是什么配置的2023-12-27 1942
-
AI边缘计算是什么意思?边缘ai是什么?AI边缘计算应用2023-08-24 4209
-
边缘计算盒子用处,边缘计算盒子的特点2023-05-22 2543
-
边缘计算如何快速处理数据缺陷2023-05-18 393
-
为什么需要边缘计算?哪些场景需要边缘计算?2023-05-12 1599
-
边缘计算网关怎么选择?边缘计算网关设备推荐2023-03-16 2127
-
边缘计算的相关资料推荐2021-12-23 2142
-
音视频边缘计算2021-10-29 2090
-
边缘计算是指什么?边缘计算的最大优势是什么2021-07-12 1764
-
边缘计算网关是什么 边缘计算网关功能优势2020-09-10 15571
-
5G边缘计算网关的优势2020-09-06 2765
-
为什么需要边缘计算2020-06-23 2789
-
什么是边缘计算?边缘计算的优点和资料说明2020-02-12 6440
全部0条评论

快来发表一下你的评论吧 !
