

如何在命令行模式下使用已有的Linux性能分析
描述
当你登陆一台 Linux 服务器之后,因为一个问题要做性能分析时:你会在第 1 分钟内做哪些检测呢?
在 Netflix,我们有很多 EC2 的 Linux 机器,并且也需要很多性能分析工具来监控和检查它们的性能。包括有针对云上的监控工具 Atlas,和按需要进行实例分析的 Vector。虽然这些工具能帮助我们解决大多数问题,但是我们有时候还需要登陆机器实例去运行一些标准的 Linux 性能分析工具。
最开始的 60 秒:总结在这篇文章中,Netflix 的性能分析工程师团队会给你展示在最开始的 60 秒内,如何在命令行模式下使用已有的 Linux 标准工具进行性能优化检测。在 60 秒内只需要通过运行下面的 10 个命令就可以对系统资源使用和运行进程有一个很高程度的了解。寻找错误信息和饱和度指标,并且可以显示为请求队列的长度,或者等待时长。因为它们都很容易理解,然后就是资源利用率。饱和度是指一个资源已经超过了它自己的负荷能力。

有些命令需要安装 sysstat 工具包。这些命令展示的指标会帮助你完成一些 USE(Utilization,Saturation,Errors) 方法:定位性能瓶颈的方法论。包括了检查使用率(Utilization),饱和度(Saturation),所有资源(比如 CPU,内存,磁盘等)的错误指标(Errors)。同样也要关注你什么时候检查和排除一个资源问题,因为通过排除可以缩小分析范围,同时也指导了任何后续的检查。
下面的章节将会通过一个生产系统中的例子来介绍这些命令。要了解更多这些工具的信息,也可以查看它们的帮助手册。
1. uptime
$ uptime
23:51:26 up 21:31, 1 user, load average: 30.02, 26.43, 19.02
这是一个快速展示系统平均负载的方法,这也指出了等待运行进程的数量。在 Linux 系统中,这些数字包括等待 CPU 运行的进程数,也包括了被不可中断 I/O(通常是磁盘 I/O)阻塞的进程。这给出了资源负载的很直接的展示,可以在没有其它工具的帮助下更好的理解这些数据。它是唯一快捷的查看系统负载的方式。
这三个数字是以递减的方式统计了过去 1 分钟,5 分钟和 15 分钟常数的平均数。这三个数字给我们直观展示了随着时间的变化系统负载如何变化。例如,如果你被叫去查看一个有问题的服务器,并且 1 分钟的所代表的值比 15 分钟的值低很多,那么你可能由于太迟登陆机器而错过了问题发生的时间点。
在上面的例子中,平均负载显示是在不断增加的,1 分钟的值是 30,相比 15 分钟的值 19 来说是增加了。这个数字这么大就意味着有事情发生了:可能是 CPU 需求;vmstat 或者 mpstat 会帮助确认到底是什么,这些命令会在本系列的第 3 和第 4 个命令中介绍。
2. dmesg | tail
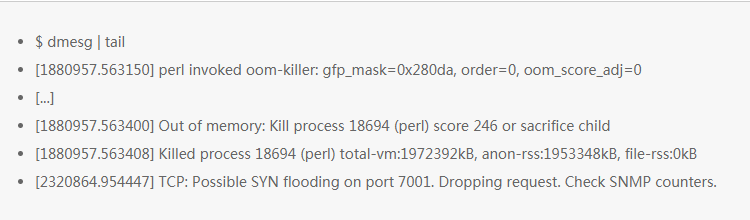
这里展示的是最近 10 条系统消息日志,如果系统消息没有就不会展示。主要是看由于性能问题导致的错误。上面这个例子中包含了杀死 OOM 问题的进程,丢弃 TCP 请求的问题。
所以要记得使用这个命令, dmesg 命令值得一用。
3. vmstat 1
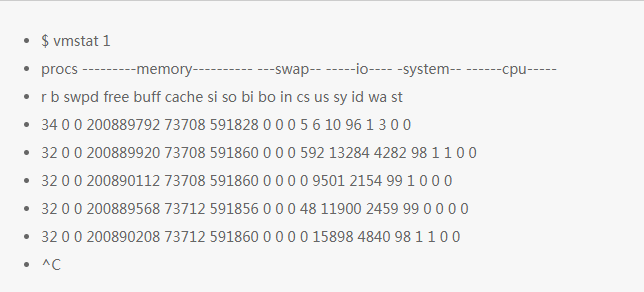
对虚拟内存统计的简短展示,vmstat 是一个常用工具(最早是几十年前为 BSD 创建的)。它每一行打印关键的服务信息统计摘要。
vmstat 使用参数 1 来运行的时候,是每 1 秒打印一条统计信息。在这个版本的 vmstat 中,输出的第一行展示的是自从启动后的平均值,而不是前一秒的统计。所以现在,可以跳过第一行,除非你要看一下抬头的字段含义。
每列含义说明:
r: CPU 上的等待运行的可运行进程数。这个指标提供了判断 CPU 饱和度的数据,因为它不包含 I/O 等待的进程。可解释为:“r” 的值比 CPU 数大的时候就是饱和的。
free:空闲内存,单位是 k。如果这个数比较大,就说明你还有充足的空闲内存。“free -m” 和下面第 7 个命令,可以更详细的分析空闲内存的状态。
si,so:交换进来和交换出去的数据量,如果这两个值为非 0 值,那么就说明没有内存了。
us,sy,id,wa,st:这些是 CPU 时间的分解,是所有 CPU 的平均值。它们是用户时间,系统时间(内核),空闲,等待 I/O 时间,和被偷的时间(这里主要指其它的客户,或者使用 Xen,这些客户有自己独立的操作域)。
CPU 时间的分解可以帮助确定 CPU 是不是非常忙(通过用户时间和系统时间累加判断)。持续的 I/O 等待则表明磁盘是瓶颈。这种情况下 CPU 是比较空闲的,因为任务都由于等待磁盘 I/O 而被阻塞。你可以把等待 I/O 看作是另外一种形式的 CPU 空闲,而这个命令给了为什么它们空闲的线索。
系统时间对于 I/O 处理来说是必须的。比较高的平均系统时间消耗,比如超过了 20%,就有必要进一步探索分析了:也有可能是内核处理 I/O 效率不够高导致。
在上面的例子中,CPU 时间几乎都是用户级别的,说明这是一个应用级别的使用情况。如果 CPU 的使用率平均都超过了 90%。这不一定问题;可以使用 “r” 列来检查使用饱和度。
4. mpstat -P ALL 1

这个命令分打印各个 CPU 的时间统计,可以看出整体 CPU 的使用是不是均衡的。有一个使用率明显较高的 CPU 就可以明显看出来这是一个单线程应用。
5. pidstat 1
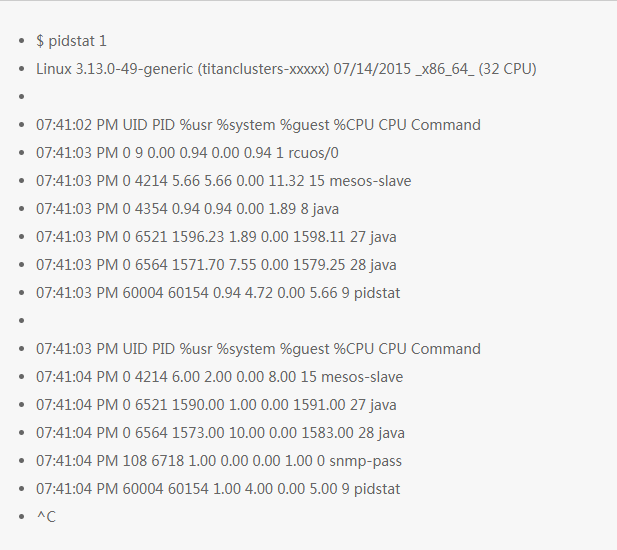
pidstat 命令有点像 top 命令中的为每个 CPU 统计信息功能,但是它是以不断滚动更新的方式打印信息,而不是每次清屏打印。这个对于观察随时间变化的模式很有用,同时把你看到的信息(复制粘贴)记到你的调查记录中。
上面的例子可以看出是 2 个 java 进程在消耗 CPU。%CPU 列是所有 CPU 的使用率;1591% 是说明这个 java 进程消耗了几乎 16 个 CPU 核。
6. iostat -xz 1
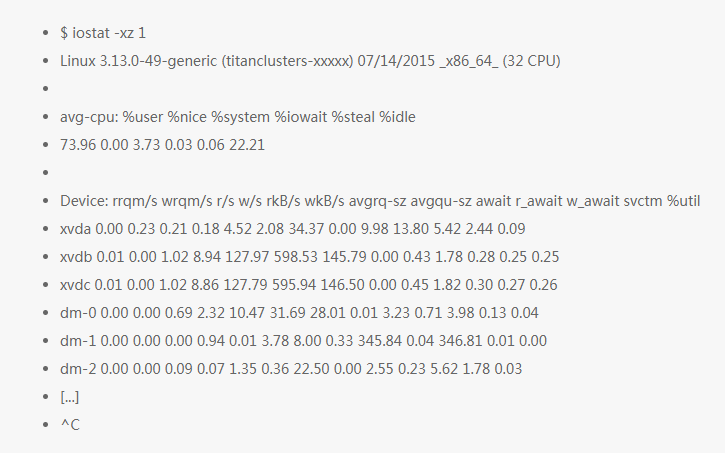
这个工具对于理解块设备(比如磁盘)很有用,展示了请求负载和性能数据。具体的数据看下面字段的解释:
r/s, w/s, rkB/s, wkB/s:这些表示设备上每秒钟的读写次数和读写的字节数(单位是 k 字节)。这些可以看出设备的负载情况。性能问题可能就是简单的因为大量的文件加载请求。
await:I/O 等待的平均时间(单位是毫秒)。这是应用程序所等待的时间,包含了等待队列中的时间和被调度服务的时间。过大的平均等待时间就预示着设备超负荷了或者说设备有问题了。
avgqu-sz:设备上请求的平均数。数值大于 1 可能表示设备饱和了(虽然设备通常都是可以支持并行请求的,特别是在背后挂了多个磁盘的虚拟设备)。
%util:设备利用率。是使用率的百分数,展示每秒钟设备工作的时间。这个数值大于 60% 则会导致性能很低(可以在 await 中看),当然这也取决于设备特点。这个数值接近 100% 则表示设备饱和了。
如果存储设备是一个逻辑磁盘设备,后面挂载了多个磁盘,那么 100% 的利用率则只是表示有些 I/O 是在 100% 处理,然而后端的磁盘或许远远没有饱和,还可以处理更多的请求。
请记住,磁盘 I/O 性能低不一定是应用程序的问题。许多技术通常都被用来实现异步执行 I/O,所以应用程序不会直接阻塞和承受延时(比如:预读取和写缓冲技术)。
7. free -m

右面两列展示的是:
buffers:用于块设备 I/O 缓冲的缓存。
cached:用于文件系统的页缓存。
我们只想检测这些缓存的数值是否接近 0 。不为 0 的可能导致较高的磁盘 I/O(通过 iostat 命令来确认)和较差的性能问题。上面的例子看起来没问题,都还有很多 M 字节。
“-/+ buffers/cache” 这一行提供了对已使用和空闲内存明确的统计。Linux 用空闲内存作为缓存,如果应用程序需要,可以快速拿回去。所以应该包含空闲内存那一列,这里就是这么统计的。甚至有一个网站专门来介绍 Linux 内存消耗的问题:linuxatemyram。
如果在 Linux 上使用了 ZFS 文件系统,则可能会更乱,因为当我们在开发一些服务的时候,ZFS 有它自己的文件系统缓存,而这部分内存的消耗是不会在 free -m 这个命令中合理的反映的。显示了系统内存不足,但是 ZFS 的这部分缓存是可以被应用程序使用的。
8. sar -n DEV 1
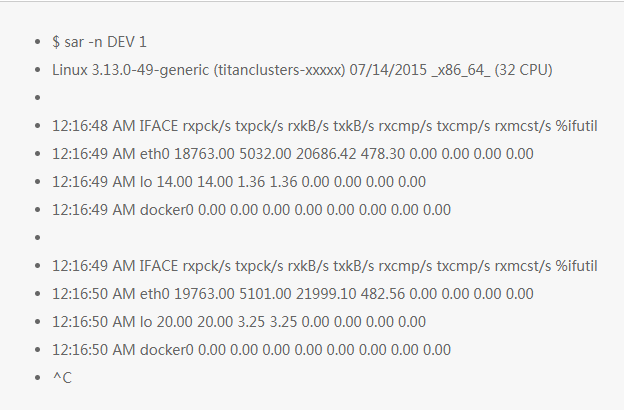
使用这个工具是可以检测网络接口的吞吐:rxkB/s 和 txkB/s,作为收发数据负载的度量,也是检测是否达到收发极限。在上面这个例子中,eth0 接收数据达到 22 M 字节/秒,也就是 176 Mbit/秒(网卡的上限是 1 Gbit/秒)。
这个版本的工具还有一个统计字段: %ifutil,用于统计设备利用率(全双工双向最大值),这个利用率也可以使用 Brendan 的 nicstat 工具来测量统计。在这个例子中 0.00 这种情况就似乎就是没有统计,这个和 nicstat 一样,这个值是比较难统计正确的。
9. sar -n TCP,ETCP 1
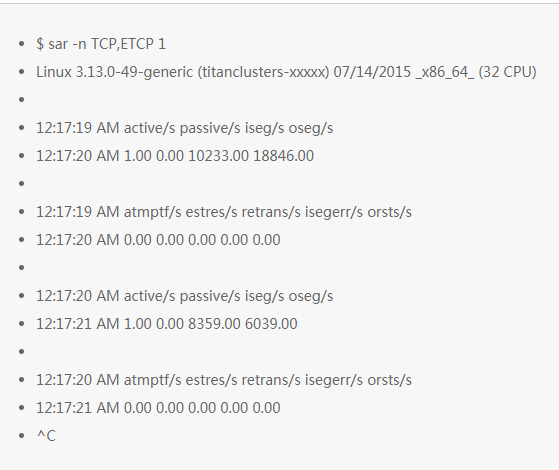
这是对 TCP 关键指标的统计,它包含了以下内容:
active/s:每秒本地发起的 TCP 连接数(例如通过 connect() 发起的连接)。
passive/s:每秒远程发起的连接数(例如通过 accept() 接受的连接)。
retrans/s:每秒 TCP 重传数。
这种主动和被动统计数通常用作对系统负载的粗略估计:新接受连接数(被动),下游连接数(主动)。可以把主动看作是外部的,被动的是内部,但是这个通常也不是非常准确(例如:当有本地到本地的连接时)。
重传是网络或者服务器有问题的一个信号;可能是一个不可靠的网络(例如:公网),或者可能是因为服务器过载了开始丢包。上面这个例子可以看出是每秒新建一个 TCP 连接。
10. top

top 命令包含了很多我们前面提到的指标。这个命令可以很容易看出指标的变化表示负载的变化,这个看起来和前面的命令有很大不同。
top 的一个缺陷也比较明显,很难看出变化趋势,其它像 vmstat 和 pidstat 这样的工具就会很清晰,它们是以滚动的方式输出统计信息。所以如果你在看到有问题的信息时没有及时的暂停下来(Ctrl-S 是暂停, Ctrl-Q 是继续),那么这些有用的信息就会被清屏。
Follow-on Analysis还有很多可以使用来深挖系统问题的命令和技术,可以看看 Brendan 在 2015 年讲的 Linux 性能工具介绍 ,这里面讲述了 40 多个命令,涵盖了可观测性,基准测试,调优,静态性能调优,分析和跟踪等多个方面。
作者:helightxu,腾讯 IEG 开发工程师
编辑:hfy
-
linux命令行运行步骤2023-11-17 1966
-
linux切换到命令行模式2023-11-13 3251
-
linux命令行与shell编程实战2023-11-08 1776
-
在命令行下配置防火墙的基础上网步骤2023-09-24 2200
-
如何在Linux命令行中运行Python脚本2023-05-12 2990
-
如何使用命令行在Linux中查找文件?2023-03-23 5961
-
如何在Linux命令行中格式化输出xml2023-01-12 2603
-
Linux命令行与shell脚本编写2023-01-11 774
-
如何在Linux使用pidof命令2022-12-05 3523
-
Linux下播放器开发-Mplayer命令行使用介绍2022-08-14 8588
-
Linux 命令行教程好书推荐2021-02-14 2416
-
能提高效率的Linux命令行技巧2019-02-02 3016
-
itop4412开发板跑的是linux系统,如何在命令行下,写shell命令来关机?2015-11-18 9553
全部0条评论

快来发表一下你的评论吧 !
