

关于HiSpark WiFi IoT OLED移植到鸿蒙
描述
效果图
大家好,我是Gray,是一名默默无闻的嵌入式软件工程师,比较喜欢钻研新技术,一直关注鸿蒙,由于错过最佳申请板子的时间,现在手头没有开发板,申请的还没有下文,现在借用别人的,下班回来搞搞,希望官方有多的板子能送我一套3861~~,今天就给大家分享一下我的在移植OLED到鸿蒙,其实也不叫移植,已经有大佬们移植好了,我只是修改一些函数,让它用起来更加的方便,更加符合我们程序猿的使用风格,今天的主要内容就是让OLED能通过Printf那样输出字符串,支持中英混合的那种,先看效果图:
可以是这种姿势:
ssd1306_Print(0,0,"哈喽鸿蒙", White);

这种姿势:
ssd1306_Print(0,0,"哈喽Harmony", White);

甚至还可以这么搞:
sprintf(buff,"温度 %d C",20); ssd1306_Print(0,32,buff, White);

这样用不比下面的这样的香吗??????
OLED_ShowCHinese(0,0,0);
OLED_ShowCHinese(16,0,1);
OLED_ShowCHinese(32,0,2);
OLED_ShowCHinese(48,0,3);
OLED_ShowCHinese(64,0,4);
OLED_ShowCHinese(80,0,5);
OLED_ShowCHinese(96,0,6); //显示 空气质量检测仪
OLED_ShowString(0,2,"T:");
OLED_ShowNum(16,2,temperature,2,16);//显示温度值
OLED_ShowCHinese(32,2,8);//显示温度符号
OLED_ShowString(56,2,"R:");
OLED_ShowChar(88,2,'%');//显示温度符号
OLED_ShowNum(72,2,humidity,2,16);
传统的这种一个字一条语句,你还得算某个字体有没有越位,或者位置是不是有间隔了。。。这样浪费多少时间,怎么能容忍这样的事情发生呢?坚决不能容忍!!!!接下来看看怎么弄吧~~
移植教程
声明:跟着本教程操作默认你已经搭建好环境,环境搭建可移步:
传送
移植教程已经有了,我是参照润和许老师的教程修改的,移植教程请移步:
[传送]
教程是把代码下载到根目录,并运行,但是我们做项目都是把外设模块统一放在app下执行,所以我的移植是这样的:
1.把代码下载并上传到 linux服务器,我的是虚拟机,直接通过共享文件夹上传到虚拟机桌面,然后敲命令
unzip harmonyos-ssd1306-master.zip -d /home/harmony/harmony/code/code-1.0/applications/sample/wifi-iot/app/
解压到app文件夹:
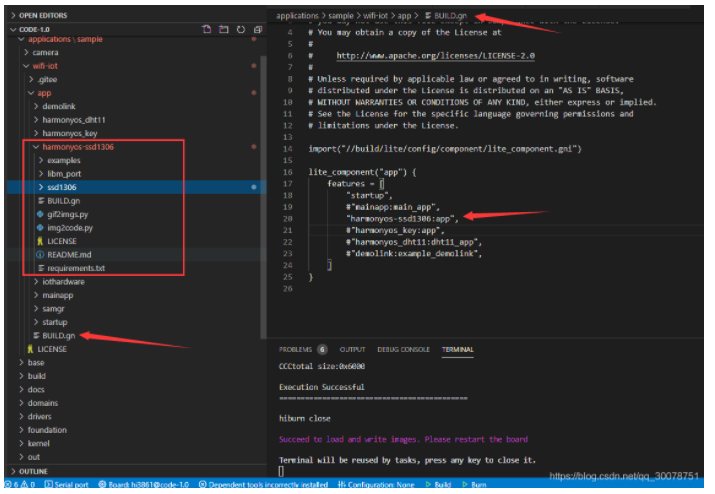
然后修改app目录下的BUILD.gn ,添加"harmonyos-ssd1306:app", 注意分号
然后编译,下载即可。
如何显示中文
我们都知道,oled显示都是ascii码,那中文是用什么码来显示呢?这里普及一下汉字编码知识:
中文汉字:
字节数 : 2;编码:GB2312
字节数 : 2;编码:GBK
字节数 : 2;编码:GB18030
字节数 : 1;编码:ISO-8859-1
字节数 : 3;编码:UTF-8
字节数 : 4;编码:UTF-16
字节数 : 2;编码:UTF-16BE
字节数 : 2;编码:UTF-16LE
1、美国人首先对其英文字符进行了编码,也就是最早的ascii码,用一个字节的低7位来表示英文的128个字符,高1位统一为0;
2、后来欧洲人发现尼玛你这128位哪够用,比如我高贵的法国人字母上面的还有注音符,这个怎么区分,得,把高1位编进来吧,这样欧洲普遍使用一个全字节进行编码,最多可表示256位。欧美人就是喜欢直来直去,字符少,编码用得位数少; 3、但是即使位数少,不同国家地区用不同的字符编码,虽然0–127表示的符号是一样的,但是128–255这一段的解释完全乱套了,即使2进制完全一样,表示的字符完全不一样,比如135在法语,希伯来语,俄语编码中完全是不同的符号; 4、更麻烦的是,尼玛这电脑高科技传到中国后,中国人发现我们有10万多个汉字,你们欧美这256字塞牙缝都不够。于是就发明了GB2312这些汉字编码,典型的用2个字节来表示绝大部分的常用汉字,最多可以表示65536个汉字字符,这样就不难理解有些汉字你在新华字典里查得到,但是电脑上如果不处理一下你是显示不出来的了吧。
5、这下各用各的字符集编码,这世界咋统一?俄国人发封email给中国人,两边字符集编码不同,尼玛显示都是乱码啊。为了统一,于是就发明了unicode,将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码,现在unicode可以容纳100多万个符号,每个符号的编码都不一样,这下可统一了,所有语言都可以互通,一个网页页面里可以同时显示各国文字。
6、然而,unicode虽然统一了全世界字符的二进制编码,但没有规定如何存储啊,亲。x86和amd体系结构的电脑小端序和大端序都分不清,别提计算机如何识别到底是unicode还是acsii了。如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,文本文件的大小会因此大出二三倍,这对于存储来说是极大的浪费。这样导致一个后果:出现了Unicode的多种存储方式。 7、互联网的兴起,网页上要显示各种字符,必须统一啊,亲。utf-8就是Unicode最重要的实现方式之一。另外还有utf-16、utf-32等。UTF-8不是固定字长编码的,而是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。这是种比较巧妙的设计,如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
8、注意unicode的字符编码和utf-8的存储编码表示是不同的,例如"严"字的Unicode码是4E25,UTF-8编码是E4B8A5,这个7里面解释了的,UTF-8编码不仅考虑了编码,还考虑了存储,E4B8A5是在存储识别编码的基础上塞进了4E25。
9、UTF-8 使用一至四个字节为每个字符编码。128 个 ASCII 字符(Unicode 范围由 U+0000 至 U+007F)只需一个字节,带有变音符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及马尔代夫语(Unicode 范围由 U+0080 至 U+07FF)需要二个字节,其他基本多文种平面(BMP)中的字符(CJK属于此类-Qieqie注)使用三个字节,其他 Unicode 辅助平面的字符使用四字节编码。
所以。。我们可以看看在鸿蒙系统上使用的是什么编码格式的,先写个demo验证一下
void test(void)
{
uint8_t i = 0;
char *ch = "鸿蒙";
//uint32_t byte;
printf("len is %d\r\n",strlen(ch));
for (i = 0; i < strlen(ch); i++)
{
printf("code is %x \n", *(ch +i));
}
}
输出
len is 6 code is ffffffe9 code is ffffffb8 code is ffffffbf code is ffffffe8 code is ffffff92 code is ffffff99
整理一下就是 e9b8bf 和 e89299 两个汉字6字节,一个就3字节,证明编码使用UTF-8来的
OK,确定了编码之后,该如何进行下一步?我们使用的ssd1306是不包含字库的,所以需要自己生成字库,那么通常的办法是把需要的字体生成字库数组,然后再通过索引找到这个字再显示出来,我这个也是这样的思路,只不过换了个方法来找字体,那就是通过编码来找。
我们可以先把汉字转成utf-8编码,比如“鸿蒙”的编码就是 0xe9b8bf 0xe89299
转换的网站是这个
转换UTF-8
在里面生成UTF-8编码,然后记住
在代码里创建一个结构体:
typedef struct
{
unsigned int Index; //汉字编码UTF-8
unsigned char Msk[32]; //字模
}typFNT_GB16;
然后创建结构体数组:
typFNT_GB16 CN16_Msk[2] = {
{
0xE9B8BF,
{
0x00,0x80,0x40,0x1F,0x84,0x44,0x44,0x04,0x24,0x44,0xC4,0x47,0x5C,0x48,0x40,0x00,
0x10,0x20,0x7C,0x44,0x64,0x54,0x44,0x4C,0x40,0x7E,0x02,0x02,0x7A,0x02,0x0A,0x04,/*"鸿",0*/
}
},
{
0xE89299,
{
0x08,0xFF,0x08,0x7F,0x40,0x8F,0x00,0x7F,0x06,0x3B,0x04,0x19,0x62,0x0C,0x72,0x01,
0x20,0xFE,0x20,0xFE,0x02,0xE4,0x00,0xFC,0x00,0x08,0xB0,0xC0,0xA0,0x98,0x86,0x00,/*"蒙",1*/
}
},
};
字模生成使用PCtoLCD 配置是 阴码,顺向,行列式,16进制。
显示中文代码
上面的准备工作做好之后,接下来就是编写显示的函数了,一开始想直接用代码自带的字库数组,无奈,这个代码的作者是使用u16类型来编码的,所以无法适配我们u8类型,所以还是得自己编写,那么实现的代码如下:
void ssd1306_Print(uint8_t x, uint8_t y, char *s, SSD1306_COLOR color)
{
unsigned char i,k,length;
uint32_t Index = 0;
uint8_t b;
length = strlen(s);//取字符串总长
for(k=0; k 127){//大于127,为汉字,UTF-8是3个字节
Index = ((uint8_t)(*(s+k)) << 16) | ((uint8_t)(*(s+k+1)) << 8) | (uint8_t)((s+k+2));
//取汉字的编码
//printf("byte is %x \r\n", Index );
for(i=0;i
核心也是画点函数,根据字节来确定是否点亮那个位置,
适配英文字符
为了适配英文,原生字库没有带有8x16大小的英文字符数组,最接近的也是7x10,所以我写了一个8x16显示字符的函数:
char ssd1306_DrawChar_u8(char ch, SSD1306_COLOR color) {
uint32_t i, j;
uint8_t b;
// Check if character is valid
if (ch < 32 || ch > 126)
return 0;
// Check remaining space on current line
if (SSD1306_WIDTH < (SSD1306.CurrentX + 8) ||
SSD1306_HEIGHT < (SSD1306.CurrentY + 16))
{
// Not enough space on current line
return 0;
}
// Use the font to write
for(i = 0; i < 16; i++) { //
b = Font8x16[(ch - 32) * 16 + i];
for(j = 0; j < 8; j++) {
if((b << j) & 0x80) {
ssd1306_DrawPixel(SSD1306.CurrentX + j, (SSD1306.CurrentY + i), (SSD1306_COLOR) color);
} else {
ssd1306_DrawPixel(SSD1306.CurrentX + j, (SSD1306.CurrentY + i), (SSD1306_COLOR)!color);
}
}
}
// The current space is now taken
SSD1306.CurrentX += 8;
// Return written char for validation
return ch;
}
这个函数是对应8x16大小的ascii码,如果想换其他的大小的请自己修改。举一反三
如果想使用原生字库,只需把ssd1306_DrawChar_u8(*(s+k), color); 改成ssd1306_DrawChar((s+k),(字体), color);
就可以了,不过中英文混搭输出还是字体大小对应得上比较好。
验证
编写好代码之后就是验证阶段了,验证结果也就是开头的效果图,还别说写好这样的代码以后用起来是很方便的。
编辑:hfy
-
【HarmonyOS HiSpark Wi-Fi IoT 套件试用连载】鸿蒙HiSpark Wi-Fi IoT套件使用感受(二)2022-06-14 4274
-
WiFi IoT 优秀帖子合集2020-11-27 4161
-
【HarmonyOS HiSpark Wi-Fi IoT 套件试用连载】开发套件初探2020-11-22 2637
-
【HarmonyOS HiSpark Wi-Fi IoT 套件试用OLED驱动】oled屏的使用和oled驱动测试2020-11-15 3443
-
硬件工程师与鸿蒙的初遇——<HiSpark WIFI IOT>开箱2020-11-01 1839
-
【HarmonyOS HiSpark Wi-Fi IoT 套件】 初次体验wifi_iot套件2020-10-20 1542
-
【HarmonyOS HiSpark Wi-Fi IoT 套件试用连连载】我和鸿蒙的亲密接触----开箱报告2020-10-19 1272
-
【HarmonyOS HiSpark Wi-Fi IoT套件】用鸿蒙OS在OLED屏上播放Bad Apple!2020-10-14 1870
-
【HarmonyOS HiSpark Wi-Fi IoT套件】华为海思推出HiSpark系列开发套件 覆盖感知计算、智慧联接领域2020-10-12 2741
-
HiSpark WiFi-IoT开发套件简介2020-09-10 3463
-
【HarmonyOS HiSpark Wi-Fi IoT套件】 HiSpark WiFi-IoT开发套件简介2020-08-26 3676
全部0条评论

快来发表一下你的评论吧 !
