

一个集检测与检索与一身的作品
电子说
描述
本文转载自 AI人工智能初学者,作者ChaucerG
传统的目标检索任务旨在学习具有内部相似度和内部相异度的区分特征表示,它假设图像中的对象是手动或自动精确裁剪的。但是,在许多现实世界中的搜索场景(例如,视频监视)中,很少准确地检测或标注对象(例如,人、车辆等)。因此,在没有边界框注释的情况下,物体级检索变得很棘手,这导致了一个新的但具有挑战性的主题,即图像搜索。
1、简介
行人搜索是图像搜索问题的第一个尝试。在此之前,虽然对人的检测和重识别做了大量的努力,但大多数都是独立处理这两个问题的。也就是说,传统方法将行人搜索任务划分为两个独立的子任务。
首先,利用行人检测器从图像中预测人物的边界盒,然后根据预测的边界盒的坐标对被检测人物的矩形区域进行裁剪。其次,提取检测框内行人的特征用于重新识别人物。
在一般的行人重识别(Re-ID)任务中,对行人图像进行人工注释和裁剪,然后用于训练的鉴别特征表示网络。一方面是因为在真实的视频监控任务中,大多数检测器不可避免地会出现误检和框选不准的情况,在一定程度上可能会导致ReID精度的性能显著下降。另一方面,这两个独立的子任务似乎对实际应用程序中的最终Re-ID不太友好。

图1 传统ReID+检索的过程和本文所提方法的对比图
在本文中,为了解决图像搜索问题,我们首先介绍一个端到端集成网(I-Net),它具有三个优点:
1)通过设计Siamese架构来进行在线匹配相似和不相似样本对。
2)引入了新颖的在线配对(OLP)损失和动态特征字典,该字典通过自动生成多个负数对来限制正数,从而减轻了多任务训练停滞问题。
3)提出了一种Hard example priority(HEP)的softmax损失,以通过选择Hard类别来提高分类任务的鲁棒性。
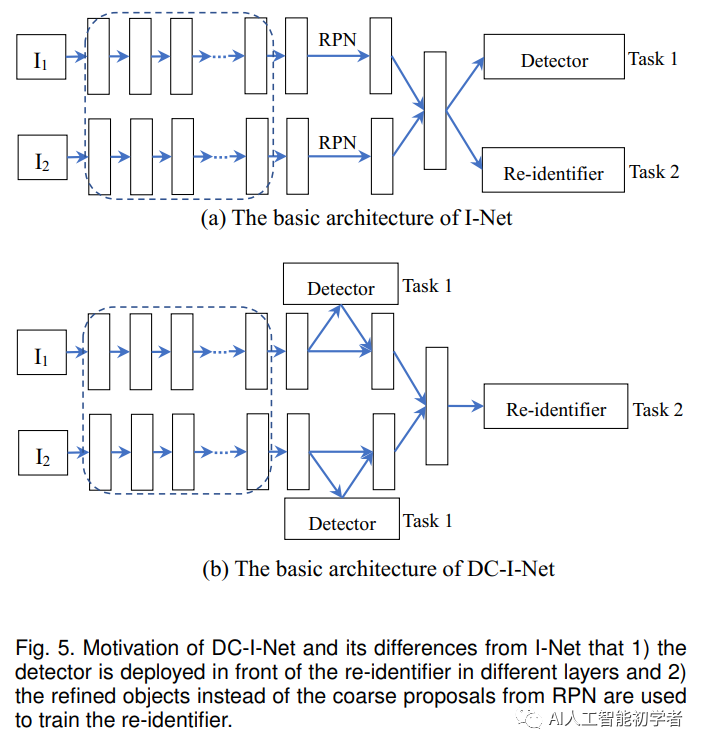
借助分而治之的理念,文章进一步提出了一种改进的I-Net,称为DC-I-Net,它做出了两个新的贡献:
1)量身定制了两个模块以在集成框架中分别处理不同的任务,从而使任务规格得到保证。
2)提出了通过利用memory的类中心进行类中心指导的HEP Loss(),从而可以捕获内部相似度和内部相似度以进行最终检索。
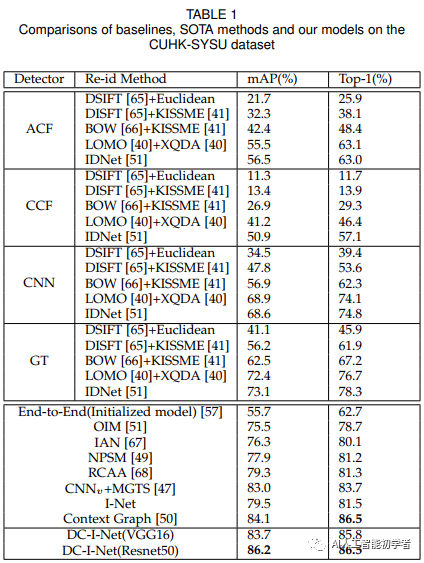
在著名的面向图像级搜索的基准数据集上的大量实验表明,所提出的DC-I-Net优于最新的tasks-integrated和tasks-separated的图像搜索模型。
2、本文方法
这篇论文是I-Net的一个实质性扩展,在网络架构和损失函数方面做出了以下新贡献:
2.1、I-Net
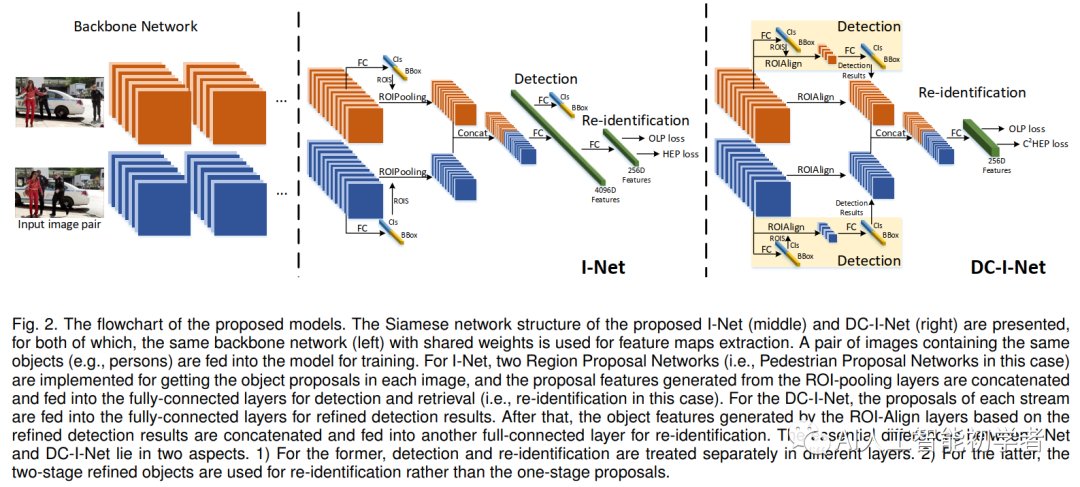
为了实现更好的图像搜索任务,I-Net(Siamese I-Net)将行人检测和行人重识别设计为端到端(End-to-End)的框架,如下图:
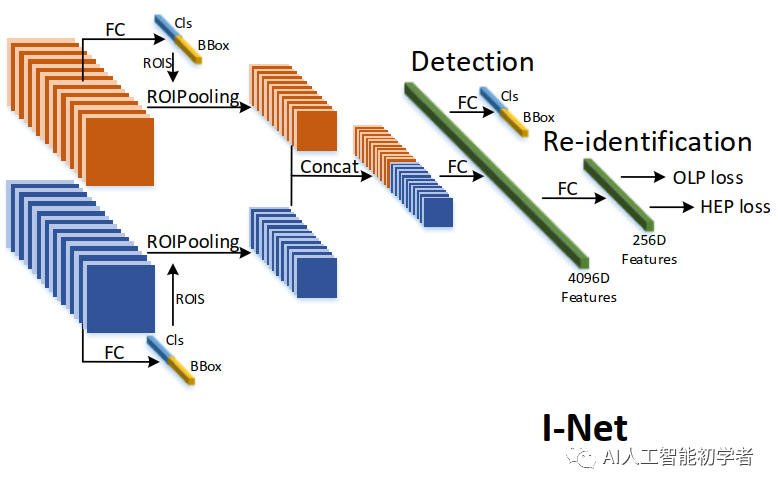
对于每一次迭代,包含相同身份id的图像对将被输入到Siamese I-Net中。利用骨干网络进行初步特征的提取。然后,通过两个RPN结构得到候选区域。再然后将这些候选区域特征输入到ROIPooling中并输出的特征图,最后是两个全连接层分别用于检测任务和检索检索(即ReID)任务。同时该结构的提出的同时也提出了两个损失函数,即OLP Loss和HEPLoss,用于学习与ReID相关的有效特征。
通过两个RPN生成的候选区域,ROI池化层被集成到I-Net中。然后,两个Stream汇集的特征被输入到有4096个神经元的两个FC中。为了消除行人候选区域的假阳性使用二值交叉熵损失区分训练。(注意,对于一般的图像搜索任务都会使用softmax分类器来进行目标检测);除此之外L1损失用来约束候选框的位置,同时会有一对256-D的特征用通过OLP Loss和HEP Loss来训练ReID Branch的模型。
2.2、On-line Pairing Loss (OLP Loss)
设计OLP损失函数主要从以下几个角度考虑的:
1 减小类内差距、增加类间差距
2 由于输入的图像数量不足,且每幅图像中目标的锁定,容易出现容易对多而身份少的情况,会导致传统度量损失(如Triplet Loss)的停滞问题,严重阻碍了模型的有效训练。
OLP Loss的设计形式如下:
OLP损失可以按照如下步骤进行复现:
1.收集两幅相同身份输入图像的特性,并构造成正样本对。
2.为每个正样本对特征中的和被设置为Anchor。负样本特征存储在特征字典中,与Anchor对配对,构建负样本对。
3.计算OLP损失,然后计算OLP梯度,进行梯度反向传播优化。
4.存储输入的特征,逐步更新特征字典。
2.3、Hard Example Priority Loss (HEP Loss)
OLP损失函数使正样本对的余弦距离更小,负样本对的余弦距离更大,这并不能直接对损失函数中的id标签进行回归。另外,传统的基于softmax的分类器交叉损失训练方法没有考虑样本在数据中的难易程度。基于上述考虑,提出了HEP Loss,目的是回归具有高优先级的身份标签。
在图4中,Hard Example的选择如下:
首先确定每个有身份的输入图像对的标签索引,以确保groundtruth类。
对于每个子组,将距离最大的最上面r个负样本的标签索引存储在优先级类池P中,使难例的优先级类得到集中。
如果池P的大小仍然小于预设的T,便随机选择几个类填充池。
最后,利用传统的基于softmax的交叉熵损失和选择的优先级类,将提出的HEP损失函数表示为:
其中,表示分类器给出的第i个proposal的分数,j表示第j个类。在损失函数中,只使用选定的类别进行损失计算,进而使得损失函数集中在硬类别上。
2.4、Overall Loss of I-Net
I-Net是一种将检测和重识别结合起来进行训练的端到端模型。因此损失由两部分组成:检测损失()和重识别损失(和),表示如下:
2.5、DC-I-NET
相较于I-Net,DC-I-NET:
1.通过使用来自不同层的特征,很好地考虑了检测和重新识别的任务专注度;
2.利用ROI-Align模块生成2级检测器来提取refined目标以用于训练度量损失;
3.提出了class-center引导困难样本优先的()损失,用于训练的id的分类损失。
Detector:在DC-I-Net中,检测任务和行人重识别任务的特征是从不同网络层次中提取的。经过分类损失和回归损失监督的两阶段检测,完成准确Bounding Boxes(即目标行人)的检测。
Re-identifier:经过两阶段检测后,将refined bounding Boxes的坐标输入ROIAlign层,计算refined目标建议的特征,用于行人重识别。对于ReID任务,汇集的feature map的大小为7x14,其宽高比与person的边框相似。然后将特征图输入全连通层,学习用于行人重识别的特征向量表示。最后,通过全连通层生成目标方案的256-D的经过L2归一化后特征,并将其输入到和中进行重识别模块的训练。
损失函数定义如下:
DC-I-Net总损失为:
3、实验结果
原文标题:【检测+检索】一个模型让你不仅看得见也可以找得到,集检测与检索与一身的作品
文章出处:【微信公众号:机器视觉CV】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
集才华与美貌于一身是什么体验?2016-03-22 11615
-
哪位高手可否考虑做个集大成于一身的例程分享给大家2020-06-02 1602
-
集实力与颜值于一身, 该笔记本值得入手吗?2017-04-02 940
-
华为荣耀V9怎么样?荣耀V9评测:集颜值和性能于一身的蓝色荣耀V9,为青春代言2017-05-11 2599
-
是德科技首款集仿真、设计、测试工作流程于一身的平台2018-02-17 1669
-
集颜值与才华于一身的HUAWEI MateBook 14,摄影师的“好伙伴”2019-05-05 1202
-
GitHub上开源了个集众多数据源于一身的爬虫工具箱——InfoSpider2020-11-23 2915
-
DN127-3V和5V 12位轨对轨微功率DAC集灵活性和性能于一身2021-05-07 781
-
虹科CANEasy集Vector软件最重要的功能于一身2021-11-18 4367
-
集颜色、色标模式于一身的ESE系列传感器2023-08-22 2305
-
十堰新一批智慧路灯投用,集多种功能于一身 智慧路灯案例分享2025-01-03 837
-
探索Type 2FR:集多功能于一身的无线模块2025-12-16 707
-
IR2166:集PFC与镇流器控制于一身的高效芯片2025-12-24 1125
-
解析MAX14529E:集多功能于一身的过压保护芯片2026-02-09 350
-
ADV7480:集HDMI与MHL功能于一身的卓越接收器2026-05-13 1096
全部0条评论

快来发表一下你的评论吧 !
