

一文详解Java对象的内存布局
存储技术
描述
对象内存构成
Java中通过new关键字创建一个类的实例对象,对象存于内存的堆中并给其分配一个内存地址,那么是否想过如下这些问题:
这个实例对象是以怎样的形态存在内存中的? 一个Object对象在内存中占用多大? 对象中的属性是如何在内存中分配的?
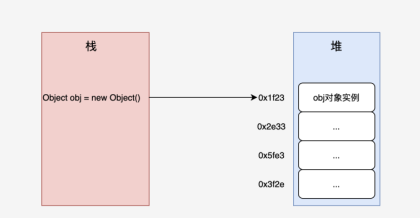
在JVM中,Java对象保存在堆中时,由以下三部分组成:
对象头(objectheader):包括了关于堆对象的布局、类型、GC状态、同步状态和标识哈希码的基本信息。Java对象和vm内部对象都有一个共同的对象头格式。 实例数据(InstanceData):主要是存放类的数据信息,父类的信息,对象字段属性信息。 对齐填充(Padding):为了字节对齐,填充的数据,不是必须的。
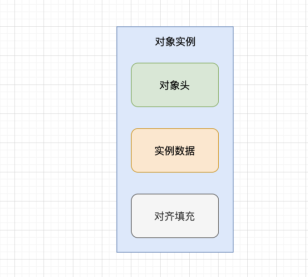
对象头
我们可以在Hotspot官方文档中找到它的描述(下图)。从中可以发现,它是Java对象和虚拟机内部对象都有的共同格式,由两个字(计算机术语)组成。另外,如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中无法确定数组的大小。
它里面提到了对象头由两个字组成,这两个字是什么呢?我们还是在上面的那个Hotspot官方文档中往上看,可以发现还有另外两个名词的定义解释,分别是markword和klasspointer。
从中可以发现对象头中那两个字:第一个字就是markword,第二个就是klasspointer。
MarkWord
用于存储对象自身的运行时数据,如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等。
MarkWord在32位JVM中的长度是32bit,在64位JVM中长度是64bit。我们打开openjdk的源码包,对应路径/openjdk/hotspot/src/share/vm/oops,MarkWord对应到C++的代码markOop.hpp,可以从注释中看到它们的组成,本文所有代码是基于Jdk1.8和64位操作系统。
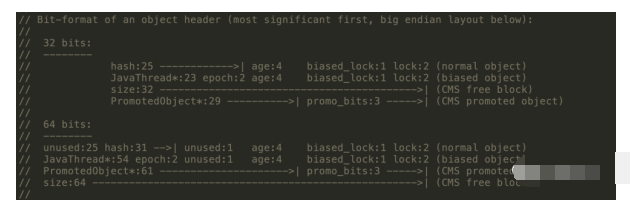
MarkWord在不同的锁状态下存储的内容不同,在32位JVM中是这么存的
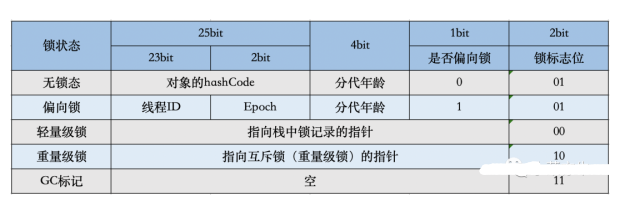
在64位JVM中是这么存的
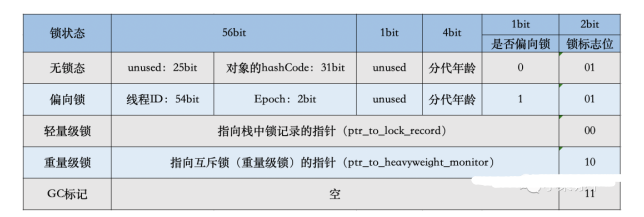
虽然它们在不同位数的JVM中长度不一样,但是基本组成内容是一致的。
锁标志位(lock):区分锁状态,11时表示对象待GC回收状态,只有最后2位锁标识(11)有效。 biased_lock:是否偏向锁,由于正常锁和偏向锁的锁标识都是01,没办法区分,这里引入一位的偏向锁标识位。 分代年龄(age):表示对象被GC的次数,当该次数到达阈值的时候,对象就会转移到老年代。 对象的hashcode(hash):运行期间调用System.identityHashCode()来计算,延迟计算,并把结果赋值到这里。当对象加锁后,计算的结果31位不够表示,在偏向锁,轻量锁,重量锁,hashcode会被转移到Monitor中。 偏向锁的线程ID(JavaThread):偏向模式的时候,当某个线程持有对象的时候,对象这里就会被置为该线程的ID。在后面的操作中,就无需再进行尝试获取锁的动作。 epoch:偏向锁在CAS锁操作过程中,偏向性标识,表示对象更偏向哪个锁。 ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。当锁获取是无竞争的时,JVM使用原子操作而不是OS互斥。这种技术称为轻量级锁定。在轻量级锁定的情况下,JVM通过CAS操作在对象的标题字中设置指向锁记录的指针。 ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。如果两个不同的线程同时在同一个对象上竞争,则必须将轻量级锁定升级到Monitor以管理等待的线程。在重量级锁定的情况下,JVM在对象的ptr_to_heavyweight_monitor设置指向Monitor的指针。
KlassPointer
即类型指针,是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
实例数据
如果对象有属性字段,则这里会有数据信息。如果对象无属性字段,则这里就不会有数据。根据字段类型的不同占不同的字节,例如boolean类型占1个字节,int类型占4个字节等等;
对齐数据
对象可以有对齐数据也可以没有。默认情况下,Java虚拟机堆中对象的起始地址需要对齐至8的倍数。如果一个对象用不到8N个字节则需要对其填充,以此来补齐对象头和实例数据占用内存之后剩余的空间大小。如果对象头和实例数据已经占满了JVM所分配的内存空间,那么就不用再进行对齐填充了。
所有的对象分配的字节总SIZE需要是8的倍数,如果前面的对象头和实例数据占用的总SIZE不满足要求,则通过对齐数据来填满。
为什么要对齐数据?字段内存对齐的其中一个原因,是让字段只出现在同一CPU的缓存行中。如果字段不是对齐的,那么就有可能出现跨缓存行的字段。也就是说,该字段的读取可能需要替换两个缓存行,而该字段的存储也会同时污染两个缓存行。这两种情况对程序的执行效率而言都是不利的。其实对其填充的最终目的是为了计算机高效寻址。
至此,我们已经了解了对象在堆内存中的整体结构布局,如下图所示
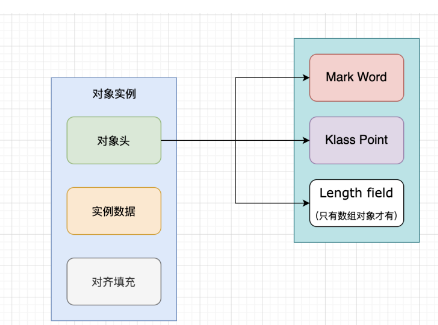
Talkischeap,showmecode
概念的东西是抽象的,你说它是这样组成的,就真的是吗?学习是需要持怀疑的态度的,任何理论和概念只有自己证实和实践之后才能接受它。还好openjdk给我们提供了一个工具包,可以用来获取对象的信息和虚拟机的信息,我们只需引入jol-core依赖,如下
jol-core常用的三个方法
ClassLayout.parseInstance(object).toPrintable():查看对象内部信息。 GraphLayout.parseInstance(object).toPrintable():查看对象外部信息,包括引用的对象。 GraphLayout.parseInstance(object).totalSize():查看对象总大小。
普通对象为了简单化,我们不用复杂的对象,自己创建一个类D,先看无属性字段的时候

通过jol-core的api,我们将对象的内部信息打印出来
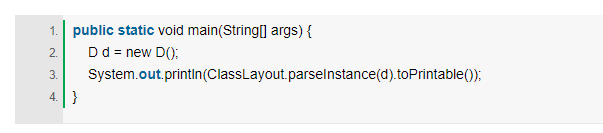
最后的打印结果为
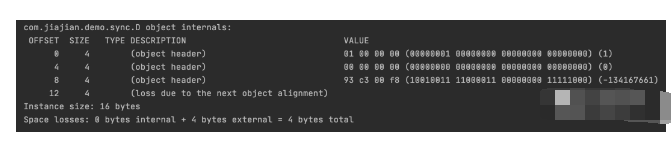
可以看到有OFFSET、SIZE、TYPEDESCRIPTION、VALUE这几个名词头,它们的含义分别是
OFFSET:偏移地址,单位字节; SIZE:占用的内存大小,单位为字节; TYPEDESCRIPTION:类型描述,其中objectheader为对象头; VALUE:对应内存中当前存储的值,二进制32位;
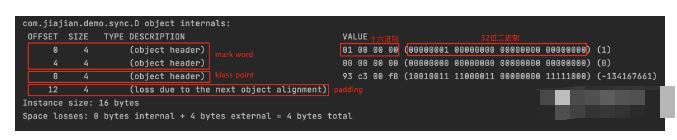
可以看到,d对象实例共占据16byte,对象头(objectheader)占据12byte(96bit),其中markword占8byte(64bit),klasspointe占4byte,另外剩余4byte是填充对齐的。
这里由于默认开启了指针压缩,所以对象头占了12byte,具体的指针压缩的概念这里就不再阐述了,感兴趣的读者可以自己查阅下官方文档。jdk8版本是默认开启指针压缩的,可以通过配置vm参数开启关闭指针压缩,-XX:-UseCompressedOops。
如果关闭指针压缩重新打印对象的内存布局,可以发现总SIZE变大了,从下图中可以看到,对象头所占用的内存大小变为16byte(128bit),其中markword占8byte,klasspointe占8byte,无对齐填充。

开启指针压缩可以减少对象的内存使用。从两次打印的D对象布局信息来看,关闭指针压缩时,对象头的SIZE增加了4byte,这里由于D对象是无属性的,读者可以试试增加几个属性字段来看下,这样会明显的发现SIZE增长。因此开启指针压缩,理论上来讲,大约能节省百分之五十的内存。jdk8及以后版本已经默认开启指针压缩,无需配置。
数组对象
上面使用的是普通对象,我们来看下数组对象的内存布局,比较下有什么异同
打印的内存布局信息,如下
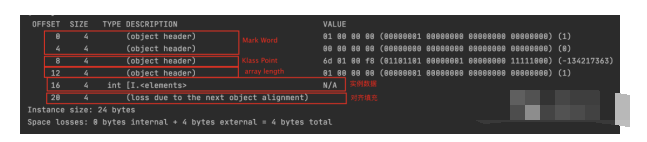
可以看到这时总SIZE为共24byte,对象头占16byte,其中MarkWork占8byte,KlassPoint占4byte,arraylength占4byte,因为里面只有一个int类型的1,所以数组对象的实例数据占据4byte,剩余对齐填充占据4byte。
结尾
对象的内存布局和对象头的概念,特别是对象头的MarkWord的内容,在我们分析synchronize和JVM垃圾回收年龄代的时候会有很大作用。
JVM中大家是否还记得对象在Suvivor中每熬过一次MinorGC,年龄就增加1,当它的年龄增加到一定程度后就会被晋升到老年代中,这个次数默认是15岁,有想过为什么是15吗?在MarkWord中可以发现标记对象分代年龄的分配的空间是4bit,而4bit能表示的最大数就是2^4-1=15。
责任编辑人:CC
-
java虚拟机内存包括远空间内存吗2023-12-05 1199
-
java内存溢出的几种原因和解决办法2023-11-23 7580
-
Java中的对象一定在堆中分配吗2023-09-30 1928
-
详解Java虚拟机的JVM内存布局2023-07-13 1352
-
JVM内存布局详解2023-04-26 1256
-
浅析JVM之对象创建流程及对象内存布局2023-02-02 1172
-
探讨JVM的内存布局2022-09-09 1577
-
如何用java映射创建java对象和调用java对象的方法2022-07-28 2412
-
如何用java映射创建java对象和调用java对象呢2022-04-11 2290
-
详解String对象的内存分配2020-07-01 3063
-
Java教程之Java面向对象程序设计一维数组的使用2019-01-09 1109
-
Java内存区域分配、Java虚拟机栈、对象的访问方式和GC2017-12-11 2758
-
JAVA教程之存储与读取对象2016-04-11 587
-
Java程序内存低效使用问题的分析2009-04-09 926
全部0条评论

快来发表一下你的评论吧 !
